在python 文件开头加上
#!user/bin/python3
运行python, 可以用
./mypython.py
#而不用,
python3 mypython.py
Ctrl + d # open new terminal window tab
Shell: a program that take commands from keyboard and give them to operating system to perform;
Command Line or Shell: aslo called CLI(Command Line Interface)
Terminal: a tool which you can use to pass your shell commands. A program that opens a window and lets you interact with the shell
File in Linux system are arranged in hierarchical directory structure: organized in a tree-like pattern
实用code
一个file 多少行
wc -l file.txt
一个file 多少个column, 假定column 数一样
col=`head -1 file.txt | wc -w`
把文件每个单词 各自打在独立的一行
grep -o '[[:alpha:]]\{2,\}' file.txt
#or
grep -o -E '[[:alpha:]]{2,}' file.txt
#or
cat file.txt | xargs -n1
#or
cat words.txt | tr -s ' ' '\n'
Remove all prefix white space
sed "s/^[[:space::]]*//" file.txt
Swap two columns
awk `{ t=$1; $1=$2; $2=t; print;}` file.txt
设置变量来自上个结果输出
"$()" or ``
col="$(head -1 file.txt | wc -w)"
col=`head -1 file.txt|wc -w`
Loop File
while IFS= read -r line
do #
for word in $line
do#
done #
done
打印中间行
打印文件第12行到第22行
head -n22 | tail -n+12
head -n22 | tail -n11
sed -n '12,22p'
把file 的每三行变成一行
paste -d';' - - -
paste - - - | tr $'\t' ';'
paste -s -d';;\n'
精确寻找
grep ```\bthe\b``` file.txt #只需找the 这个词, there 不会匹配
#or
grep -w 'the'
grep -iw -E 'the|that|then|those' #只需找含有the, that, then, those 的句子, there 不会包括
Linux 基础
cat list1.txt #显示list1.txt 所有内容: group_name:password:GID:user_list: 比如 sudo:x:27, 密码一般不显示,用x 代替. 如果用户的 GID 等于用户组的 GID,那么最后一个字段 user_list 就是空的
| 字符 | Meaning |
|---|---|
| * | 匹配 0 或多个字符 |
| ? | 匹配任意一个字符 |
| [list] | 匹配 list 中的任意单一字符 |
| [^list] | 匹配 除list 中的任意单一字符以外的字符 |
| [c1-c2] | 匹配 c1-c2 中的任意单一字符 如:[0-9] [a-z] |
| {string1,string2,…} | 匹配 string1 或 string2 (或更多)其一字符串 |
| {c1..c2} | 匹配 c1-c2 中全部字符 如{1..10} |
按键 作用
Ctrl+d 键盘输入结束或退出终端
Ctrl+s 暂停当前程序,暂停后按下任意键恢复运行
Ctrl+z 将当前程序放到后台运行,恢复到前台为命令fg
Ctrl+a 将光标移至输入行头,相当于Home键
Ctrl+e 将光标移至输入行末,相当于End键
Ctrl+k 删除从光标所在位置到行末
Alt+Backspace 向前删除一个单词
Shift+PgUp 将终端显示向上滚动
Shift+PgDn 将终端显示向下滚动
#Open Terminal 快捷键
press ctrl alt T
#show current(home) directory
pwd
clear #clear terminal
# 给options 再到directory
ls [options] [name of directory]
#list all file in current directory
ls
ls ~ #跟上面作用一样,显示home directory
ls Documents/ #Documents必须在当前文件夹下,显示Documents文件夹所有文件
ls Documents/*.html #显示Documents中只包含.html的文件
ls Documents/*.* #show all the files
ls / #显示root的所有文件,注意root的directory跟现在文件夹可能不同
ls .. #显示parent directory 所有文件
ls ../.. #显示parent 的parent directory所有文件
cd ../.. #Go to parent's parent folder
ls -l #list all directory in long format, 显示详细的信息, user, what is rights of files (write? read?), size of file,Date of creating
#drwxr-xr-x: drwxr directory (r) read (w)write, x(execute), read, -xr (group right): only execute and read, -x (others): only execute
ls -a # give hidden files also, in linux, .表示hidden files
ls -al #show hidden file and show long format
ls -lS #sort directory by size and show long format
ls -lS > out.txt #put all the show into out.txt file
ls -d */ #只显示所有的directory
ls -R #显示每个子文件夹都包含什么文件
man ls #显示所有ls 的function, 按Q退出
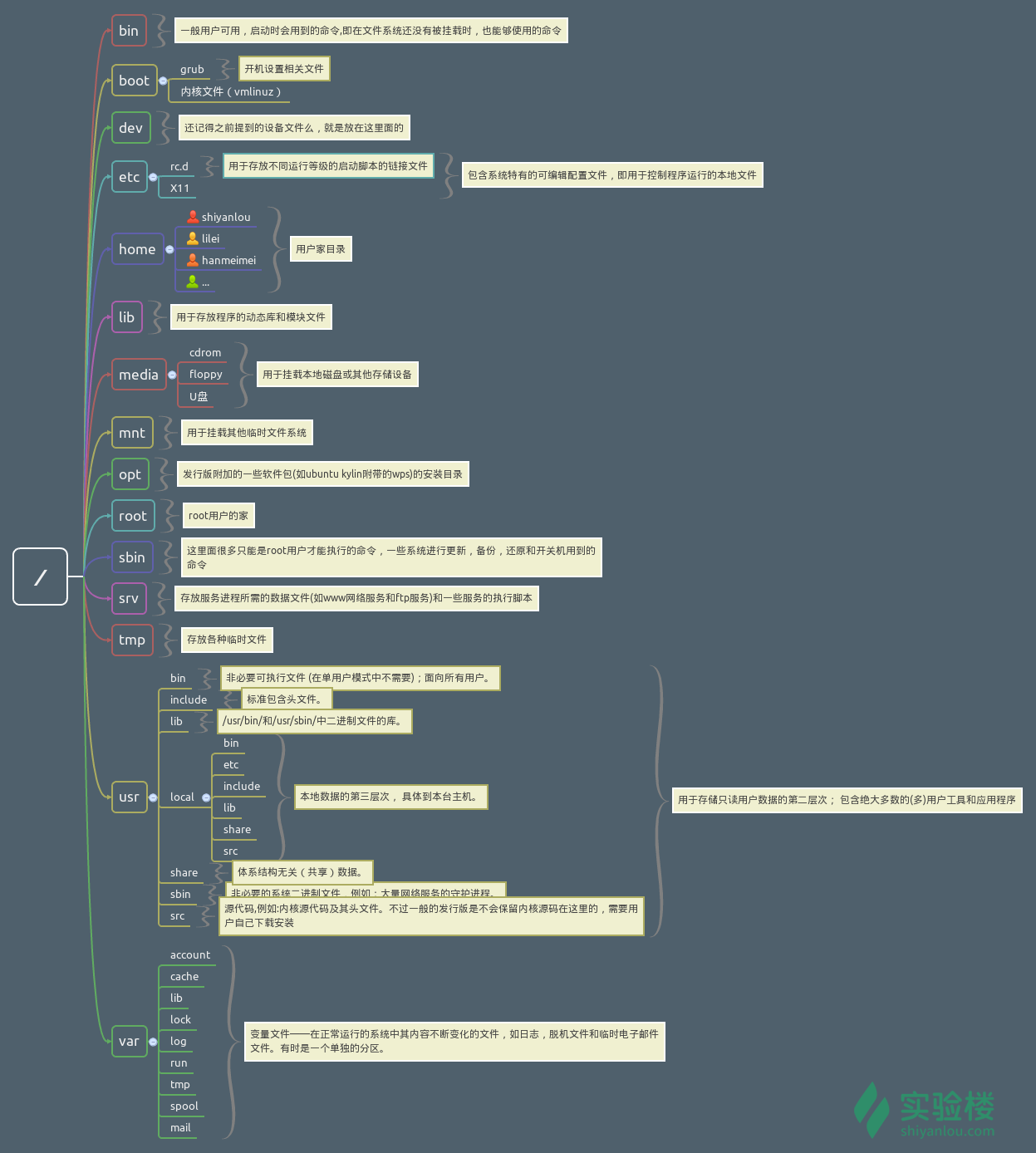
FHS(英文:Filesystem Hierarchy Standard 中文:文件系统层次结构标准),多数 Linux 版本采用这种文件组织形式,FHS 定义了系统中每个区域的用途、所需要的最小构成的文件和目录同时还给出了例外处理与矛盾处理。
FHS 定义了两层规范,第一层是, / 下面的各个目录应该要放什么文件数据,例如 /etc 应该放置设置文件,/bin 与 /sbin 则应该放置可执行文件等等。 第二层则是针对 /usr 及 /var 这两个目录的子目录来定义。例如 /var/log 放置系统日志文件,/usr/share 放置共享数据等等。
环境变量
注意:为了与普通变量区分,通常我们习惯将环境变量名设为大写。
declare tmp #创建一个名为tmp 变量
#其实也可以不用 declare 预声明一个变量,直接即用即创建,
# 这里只是告诉你 declare 的作用,这在创建其它指定类型的变量(如数组)时会用到。
tmp=shiyanlou
echo $tmp
在所有的 UNIX 和类 UNIX 系统中,每个进程都有其各自的环境变量设置,且默认情况下,当一个进程被创建时,除了创建过程中明确指定的话,它将继承其父进程的绝大部分环境设置。Shell 程序也作为一个进程运行在操作系统之上,而我们在 Shell 中运行的大部分命令都将以 Shell 的子进程的方式运行
通常我们会涉及到的变量类型有三种:
- 当前 Shell 进程私有用户自定义变量,如上面我们创建的 tmp 变量,只在当前 Shell 中有效。
- Shell 本身内建的变量。
- 从自定义变量导出的环境变量。
| 字符 | Meaning |
|---|---|
set |
显示当前 Shell 所有变量,包括其内建环境变量(与 Shell 外观等相关),用户自定义变量及导出的环境变量。 |
env |
显示与当前用户相关的环境变量,还可以让命令在指定环境中运行。 |
export |
显示从 Shell 中把变量 导出成 环境变量的变量,也能通过它将自定义变量导出为环境变量 |
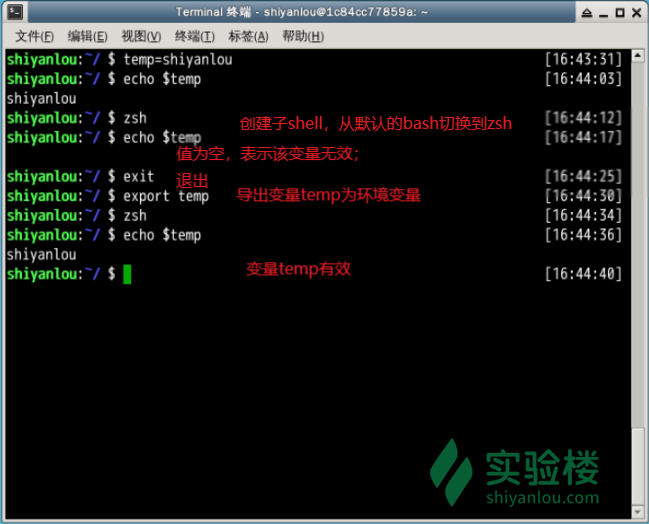
你可以更直观的使用 vimdiff 工具比较一下它们之间的差别:
$ temp=shiyanlou
$ export temp_env=shiyanlou
$ env|sort>env.txt
$ export|sort>export.txt
$ set|sort>set.txt
| 上述操作将命令输出通过管道 | 使用 sort 命令排序,再重定向到对象文本文件中。 |
$ vimdiff env.txt export.txt set.txt
按变量的生存周期来划分,Linux 变量可分为两类:
- 永久的:需要修改配置文件,变量永久生效;
- 临时的:使用 export 命令行声明即可,变量在关闭 shell 时失效。
这里介绍两个重要文件 /etc/bashrc(有的 Linux 没有这个文件) 和 /etc/profile ,它们分别存放的是 shell 变量和环境变量。还有要注意区别的是每个用户目录下的一个隐藏文件:
.profile 可以用 ls -a 查看
cd /home/shiyanlou
ls -a
这个 .profile 只对当前用户永久生效。而写在 /etc/profile 里面的是对所有用户永久生效,所以如果想要添加一个永久生效的环境变量,只需要 打开 /etc/profile,在最后加上你想添加的环境变量就好啦。
添加到environment variable
注意这里一定要使用绝对路径。
$ PATH=$PATH:/home/shiyanlou/mybin
#如果有程序在mybin 中 可以执行程序用
hello.sh #而不是用./hello.sh
上面的方法一旦关闭terminal, 下次再打开,之前定义的Path就没有用了, 解决办法:
在每个用户的 home 目录中有一个 Shell 每次启动时会默认执行一个配置脚本,以初始化环境,包括添加一些用户自定义环境变量等等。zsh 的配置文件是 .zshrc,相应 Bash 的配置文件为 .bashrc。它们在 etc 下还都有一个或多个全局的配置文件,不过我们一般只修改用户目录下的配置文件
我们可以简单地使用下面命令直接添加内容到 .zshrc 中:
$ echo "PATH=$PATH:/home/shiyanlou/mybin" >> .zshrc #>> append
如何让环境变量立即生效
在 Shell 中修改了比如 zsh 的配置文件 home 目录下的 .zshrc),每次都要退出终端重新打开甚至重启主机之后其才能生效,很是麻烦,我们可以使用 source 命令来让其立即生效,如
source .zshrc
#source 命令还有一个别名就是 .,上面的命令如果替换成 . 的方式就该是:
. ./.zshrc
#在使用.的时候,需要注意与表示当前路径的那个点区分开。
修改删除已有变量
| 命令 | 说明 |
|---|---|
${变量名#匹配字串} |
从头向后开始匹配,删除符合匹配字串的最短数据 |
${变量名##匹配字串} |
从头向后开始匹配,删除符合匹配字串的最长数据 |
${变量名%匹配字串} |
从尾向前开始匹配,删除符合匹配字串的最短数据 |
${变量名%%匹配字串} |
从尾向前开始匹配,删除符合匹配字串的最长数据 |
${变量名/旧的字串/新的字串} |
将符合旧字串的第一个字串替换为新的字串 |
${变量名//旧的字串/新的字串} |
将符合旧字串的全部字串替换为新的字串 |
比如要修改我们前面添加到 PATH 的环境变量。为了避免操作失误导致命令找不到,我们先将 PATH 赋值给一个新的自定义变量 path:
$ path=$PATH
$ echo $path
$ path=${path%/home/shiyanlou/mybin}
# 或使用通配符,*表示任意多个任意字符
$ path=${path%*/mybin}
变量删除
可以使用 unset 命令删除一个环境变量:
$ unset temp
搜索文件
whereis: 简单快速. 这个搜索很快,因为它并没有从硬盘中依次查找,而是直接从数据库中查询。whereis只能搜索二进制文件(-b),man 帮助文件(-m)和源代码文件(-s)。locate: 快而全: 通过“ /var/lib/mlocate/mlocate.db ”数据库查找,不过这个数据库也不是实时更新的,系统会使用定时任务每天自动执行 updatedb 命令更新一次,所以有时候你刚添加的文件,它可能会找不到,需要手动执行一次 updatedb 命令which小而精: 只从 PATH 环境变量指定的路径中去搜索命令find精而细:find应该是这几个命令中最强大的了,它不但可以通过文件类型、文件名进行查找而且可以根据文件的属性(如文件的时间戳,文件的权限等)进行搜索
内建命令与外部命令
内建命令实际上是 shell 程序的一部分,其中包含的是一些比较简单的 Linux 系统命令,这些命令是写在bash源码的builtins里面的,由 shell 程序识别并在 shell 程序内部完成运行,通常在 Linux 系统加载运行时 shell 就被加载并驻留在系统内存中。而且解析内部命令 shell 不需要创建子进程,因此其执行速度比外部命令快。比如:
history、cd、exit等等。
外部命令 是 Linux 系统中的实用程序部分,因为实用程序的功能通常都比较强大,所以其包含的程序量也会很大,在系统加载时并不随系统一起被加载到内存中,而是在需要时才将其调入内存。虽然其不包含在 shell 中,但是其命令执行过程是由 shell 程序控制的。外部命令是在 Bash 之外额外安装的,通常放在/bin,/usr/bin,/sbin,/usr/sbin等等。比如:
ls、vi等。
简单来说就是:一个是天生自带的天赋技能,一个是后天得来的附加技能。我们可以使用 type 命令来区分命令是内建的还是外部的。例如这两个得出的结果是不同的
type exit
type vim
#得到这样的结果说明是内建命令,正如上文所说内建命令都是在 bash 源码中的 builtins 的.def中
xxx is a shell builtin
#得到这样的结果说明是外部命令,正如上文所说,外部命令在/usr/bin or /usr/sbin等等中
xxx is /usr/bin/xxx
#若是得到alias的结果,说明该指令为命令别名所设定的名称;
xxx is an alias for xx --xxx
执行多条语句
$ sudo apt-get update
# 等待——————————然后输入下面的命令
$ sudo apt-get install some-tool //这里some-tool是指具体的软件包
# 等待——————————然后输入下面的命令
$ some-tool
这时你可能就会想:要是我可以一次性输入完,让它自己去依次执行各命令就好了,这就是我们这一小节要解决的问题。
简单的顺序执行你可以使用;来完成,比如上述操作你可以:
$ sudo apt-get update;sudo apt-get install some-tool;some-tool
# 让它自己运行
有选择的执行命令
$?获取上次语句执行结果, 返回0或者1&&: 如果上个语句返回0 (true), 执行&&后面的||: 如果上个语句返回1, 执行||后面的
which cowsay
返回: cowsay not found
$?
返回: 1
which cat
返回: /bin/cat
$?
返回:0
$ which cowsay>/dev/null || echo "cowsay has not been install, please run 'sudo apt-get install cowsay' to install"
返回 "cowsay has not been install, please run 'sudo apt-get install cowsay' to install"
which cowsay>/dev/null && echo "exist" || echo "not exist"

如果把 && 和|| 顺序倒过来, 逻辑与其他语言一样, 只是0 代表true, 1 代表false
which cowsay>/dev/null || echo "exist" && echo "not exist"
返回: exist
not exis
管道
管道是什么?管道是一种通信机制,通常用于进程间的通信(也可通过socket进行网络通信),就是将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)。管道又分为匿名管道和具名管道, 我们在使用一些过滤程序时经常会用到的就是匿名管道,在命令行中由|分隔符表示
E.g. 通过管道将前一个命令(ls)的输出作为下一个命令(less)的输入,然后就可以一行一行地看。
ls -al /etc | less
数据流重定向
<从右侧传入文件到左侧command, 比如grep 'int' < somefile<<is known as here-document structure. 告诉program what is ending text, and whenever that delimiter is seen, the program will read all the stuff you’ve given to the program as input and perform a task upon it.
< 输入重新定向, >> 和 > 输出重新定向,我们在简单地用<或>时,相当于使用 0< (到输入) 或 1>(到输出)
- stdin: 标准输入,对应于你在终端的输入
stdout: 标准输出,对应于终端的输出stderr: 标准错误输出,对应于终端的输出
| 文件描述符 | 设备文件 | 说明 |
|---|---|---|
0 |
/dev/stdin |
标准输入 |
1 |
/dev/stdout |
标准输出 |
2 |
/dev/stderr |
标准错误 |
文件描述符:文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于 UNIX、Linux 这样的操作系统。
我们可以这样使用这些文件描述符:
默认使用终端的标准输入作为命令的输入和标准输出作为命令的输出
$ cat
(按Ctrl+C退出)
将cat的连续输出(heredoc方式)重定向到一个文件
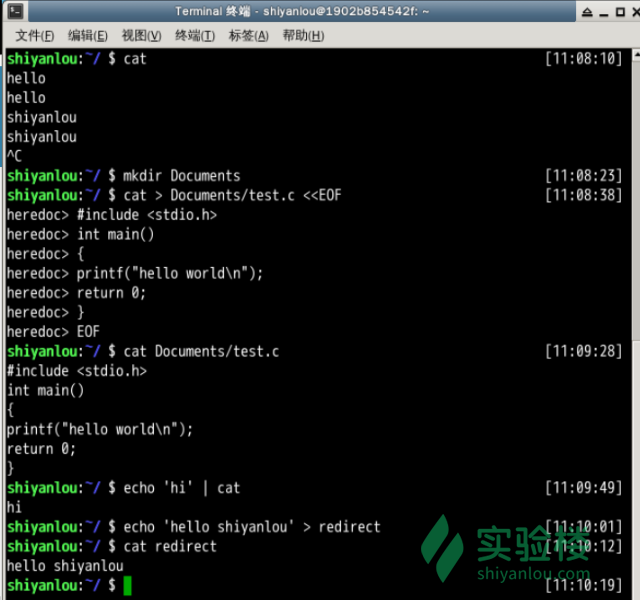
$ mkdir Documents
$ cat > Documents/test.c <<EOF #输入EOF 自动结束输入, EOF 不会写进file
# cat > Documents/test.c <<EOD #输入EOD 自动结束输入,EOD 不会写进file
#include <stdio.h>
int main()
{
printf("hello world\n");
return 0;
}
EOF
将echo命令通过管道传过来的数据作为cat命令的输入,将标准输出作为命令的输出
$ echo 'hi' | cat
# 返回 hi
注意不要将管道和重定向混淆,管道默认是连接前一个命令的输出到下一个命令的输入,而重定向通常是需要一个文件来建立两个命令的连接
标准错误重定向
标准输出和标准错误都被指向伪终端的屏幕显示,所以我们经常看到的一个命令的输出通常是同时包含了标准输出和标准错误的结果的。比如下面的操作:
# 使用cat 命令同时读取两个文件,其中一个存在(test.c),另一个不存在(hello.c)
$ cat Documents/test.c hello.c
# 你可以看到除了正确输出了前一个文件的内容,还在末尾出现了一条错误信息
# 下面我们将输出重定向到一个文件
$ cat Documents/test.c hello.c > somefile
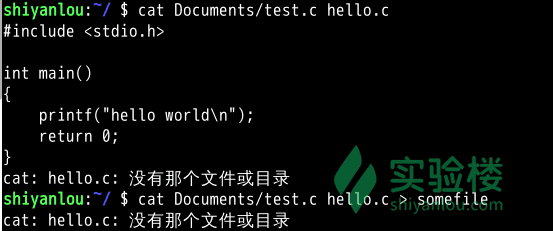
我们就是要隐藏某些错误或者警告,那又该怎么做呢
# 将标准错误重定向到标准输出,再将标准输出重定向到文件,注意要将重定向到文件写到前面
$ cat Documents/test.c hello.c >somefile 2>&1
# 或者只用bash提供的特殊的重定向符号"&"将标准错误和标准输出同时重定向到文件
$ cat Documents/test.c hello.c &>somefilehell
2>&1, 看上面的文件描述符,2 是标准错误, 1 是标准输出, 注意你应该在输出重定向文件描述符前加上&,否则shell会当做重定向到一个文件名为1的文件中
永久重新定向
exec: 你应该可以看出我们前面的重定向操作都只是临时性的,即只对当前命令有效,那如何做到“永久”有效呢,我们可以使用exec命令实现“永久”重定向。
创建输出文件描述符
在 Shell 中有9个文件描述符。上面我们使用了也是它默认提供的0,1,2号文件描述符. 另外我们还可以使用3-8的文件描述符,只是它们默认没有打开而已。你可以使用下面命令查看当前 Shell 进程中打开的文件描述符:
$ cd /dev/fd/;ls -Al
同样使用exec命令可以创建新的文件描述符:
$ zsh
$ exec 3>somefile
# 先进入目录,再查看,否则你可能不能得到正确的结果,然后再回到上一次的目录
$ cd /dev/fd/;ls -Al;cd -
# 注意下面的命令>与&之间不应该有空格,如果有空格则会出错
$ echo "this is test" >&3
$ cat somefile
$ exit

关闭文件描述符
如上面我们打开的3号文件描述符,可以使用如下操作将它关闭:
$ exec 3>&-
$ cd /dev/fd;ls -Al;cd -
在 Linux 中有一个被称为“黑洞”的设备文件,所有导入它的数据都将被“吞噬”。
在类 UNIX 系统中,
/dev/null,或称空设备,是一个特殊的设备文件,它通常被用于丢弃不需要的输出流,或作为用于输入流的空文件,这些操作通常由重定向完成。读取它则会立即得到一个EOF。
我们可以利用/dev/null屏蔽命令的输出:
$ cat Documents/test.c 1>/dev/null 2>&1
上面这样的操作将使你得不到任何输出结果
*cmd > file: 把cmd命令的输出重定向到文件file中。如果file已经存在,则清空原有文件,使用bash的noclobber选项可以防止复盖原有文件。* cmd >> file: 把cmd命令的输出重定向到文件file中,如果file已经存在,则把信息加在原有文件後面。* cmd < file: 使cmd命令从file读入* cmd << text: 从命令行读取输入,直到一个与text相同的行结束。除非使用引号把输入括起来,此模式将对输入内容进行shell变量替换。如果使用«- ,则会忽略接下来输入行首的tab,结束行也可以是一堆tab再加上一个与text相同的内容,可以参考後面的例子。* cmd <<< word: 把word(而不是文件word)和後面的换行作为输入提供给cmd。* cmd <> file: 以读写模式把文件file重定向到输入,文件file不会被破坏。仅当应用程序利用了这一特性时,它才是有意义的。* cmd >| file: 功能同>,但即便在设置了noclobber时也会复盖file文件,注意用的是|而非一些书中说的!,目前仅在csh中仍沿用>!实现这一功能。: > filename把文件”filename”截断为0长度.# 如果文件不存在, 那么就创建一个0长度的文件(与’touch’的效果相同).cmd >&n: 把输出送到文件描述符ncmd m>&n: 把输出 到文件符m的信息重定向到文件描述符ncmd >&-: 关闭标准输出cmd <&n: 输入来自文件描述符ncmd m<&n: m来自文件描述各个ncmd <&-: 关闭标准输入cmd <&n-: 移动输入文件描述符n而非复制它。(需要解释)cmd >&n-: 移动输出文件描述符 n而非复制它。(需要解释)
注意: >&实际上复制了文件描述符,这使得cmd > file 2>&1与cmd 2>&1 >file的效果不一样。更多Linux知识可参考《Linux就该这么学》。
cmd>file 2>&1
1)cmd>file: stdout-->file,stdout重定向到file,将标准输出信息写入到file文件;
2)2>&1: 1表示stdout,2表示stderr,stderr重定向到stdout,由于之前已经将stdout已经重定向到file,所以stderr信息也会写入到
cmd 2>&1 >file:
1)2>&1: stderr-->stdout,stderr重定向到stdout,将错误信息写入到stdout中;
2)>file : 这里>file相当于 cmd>file,也就是 stdout>file,将stdout重定向到file;
该命令只是把stdout重定向到file,并没有把stderr信息写入到file。
Linux下软件安装
通常 Linux 上的软件安装主要有四种方式:
- 在线安装
- 从磁盘安装deb软件包
- 从二进制软件包安装
- 从源代码编译安装
在不同的linux发行版上面在线安装方式会有一些差异包括使用的命令及它们的包管理工具,因为我们的开发环境是基于ubuntu, ubuntu又是基于debian的发行版,它使用的是debian的包管理工具dpkg,所以一些操作也适用与debian。而在一些采用其它包管理工具的发行版如redhat,centos,fedora等将不适用(redhat和centos使用rpm)。
从二进制包安装
二进制包的安装比较简单,我们需要做的只是将从网络上下载的二进制包解压后放到合适的目录,然后将包含可执行的主程序文件的目录添加进PATH环境变量即可,
进程(process)
进程的衍生
进程有这么多的种类,那么进程之间定是有相关性的,而这些有关联性的进程又是如何产生的,如何衍生的?
就比如我们启动了终端,就是启动了一个 bash 进程,我们可以在 bash 中再输入 bash 则会再启动一个 bash 的进程,此时第二个 bash 进程就是由第一个 bash 进程创建出来的,他们之间又是个什么关系?
我们一般称呼第一个 bash 进程是第二 bash 进程的父进程,第二 bash 进程是第一个 bash 进程的子进程,这层关系是如何得来的呢?
关于父进程与子进程便会提及这两个系统调用 fork() 与 exec()
-
fork()是一个系统调用(system call),它的主要作用就是为当前的进程创建一个新的进程,这个新的进程就是它的子进程,这个子进程除了父进程的返回值和 PID 以外其他的都一模一样,如进程的执行代码段,内存信息,文件描述,寄存器状态等等 -
exec()也是系统调用,作用是切换子进程中的执行程序也就是替换其从父进程复制过来的代码段与数据段
子进程就是父进程通过系统调用 fork() 而产生的复制品,fork() 就是把父进程的 PCB 等进程的数据结构信息直接复制过来,只是修改了 PID,所以一模一样,只有在执行 exec()之后才会不同,而早先的 fork() 比较消耗资源后来进化成 vfork(),效率高了不少
这就是子进程产生的由来。简单的实现逻辑就如下方所示
pid_t p;
p = fork();
if (p == (pid_t) -1)
/* ERROR */
else if (p == 0)
/* CHILD */
else
/* PARENT */
既然子进程是通过父进程而衍生出来的,那么子进程的退出与资源的回收定然与父进程有很大的相关性。当一个子进程要正常的终止运行时,或者该进程结束时它的主函数 main()会执行 exit(n); 或者 return n,这里的返回值 n 是一个信号,系统会把这个 SIGCHLD 信号传给其父进程,当然若是异常终止也往往是因为这个信号。
在将要结束时的子进程代码执行部分已经结束执行了,系统的资源也基本归还给系统了,但若是其进程的进程控制块(PCB)仍驻留在内存中,而它的 PCB 还在,代表这个进程还存在(因为 PCB 就是进程存在的唯一标志,里面有 PID 等消息),并没有消亡,这样的进程称之为僵尸进程(Zombie)。
如图中第四列标题是 S,S 表示的是进程的状态,而在下属的第三行的 Z表示的是 Zombie 的意思。( ps 命令将在后续详解)
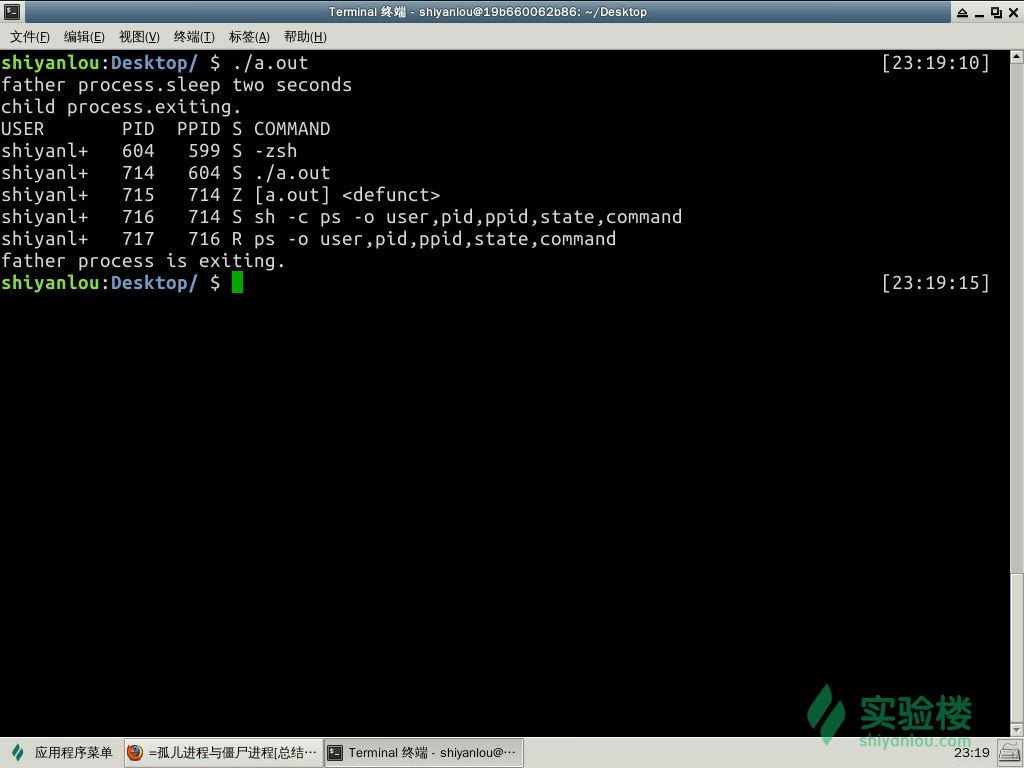
正常情况下,父进程会收到两个返回值:exit code(SIGCHLD 信号)与 reason for termination 。之后,父进程会使用 wait(&status) 系统调用以获取子进程的退出状态,然后内核就可以从内存中释放已结束的子进程的 PCB;而如若父进程没有这么做的话,子进程的 PCB 就会一直驻留在内存中,一直留在系统中成为僵尸进程(Zombie)。
虽然僵尸进程是已经放弃了几乎所有内存空间,没有任何可执行代码,也不能被调度,在进程列表中保留一个位置,记载该进程的退出状态等信息供其父进程收集,从而释放它。但是 Linux 系统中能使用的 PID 是有限的,如果系统中存在有大量的僵尸进程,系统将会因为没有可用的 PID 从而导致不能产生新的进程。
另外如果父进程结束(非正常的结束),未能及时收回子进程,子进程仍在运行,这样的子进程称之为孤儿进程。在 Linux 系统中,孤儿进程一般会被 init 进程所“收养”,成为 init 的子进程。由 init 来做善后处理,所以它并不至于像僵尸进程那样无人问津,不管不顾,大量存在会有危害。
进程 0 是系统引导时创建的一个特殊进程,也称之为内核初始化,其最后一个动作就是调用 fork() 创建出一个子进程运行 /sbin/init 可执行文件,而该进程就是 PID=1 的进程 1,而进程 0 就转为交换进程(也被称为空闲进程),进程 1 (init 进程)是第一个用户态的进程,再由它不断调用 fork() 来创建系统里其他的进程,所以它是所有进程的父进程或者祖先进程。同时它是一个守护程序,直到计算机关机才会停止。
通过以下的命令我们可以很明显的看到这样的结构
pstree

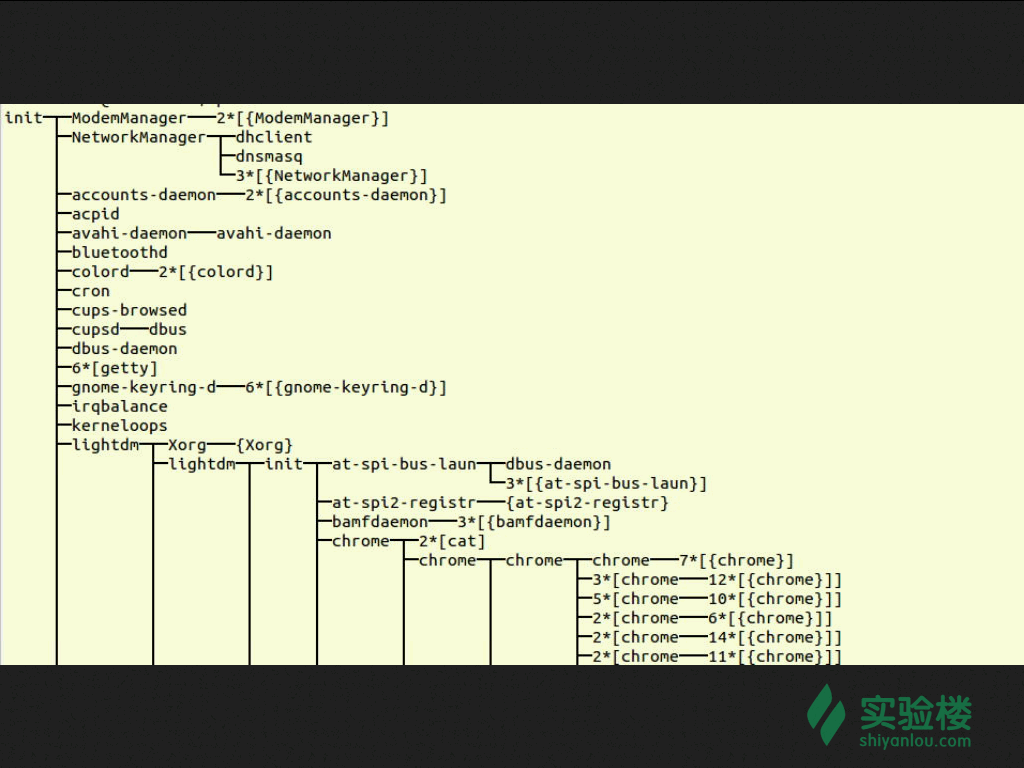
通过以上的显示结果我们可以看的很清楚,init 为所有进程的父进程或者说是祖先进程
我们还可以使用这样一个命令来看,其中 pid 就是该进程的一个唯一编号,ppid 就是该进程的父进程的 pid,command 表示的是该进程通过执行什么样的命令或者脚本而产生的
ps -fxo user,ppid,pid,pgid,command
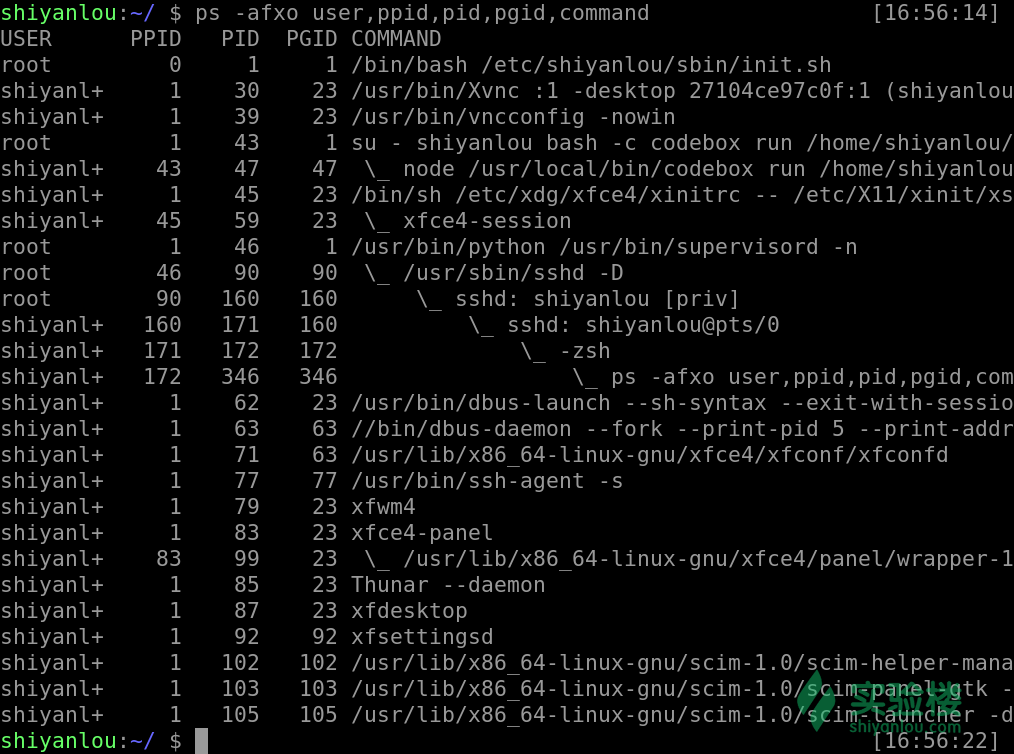
可以在图中看见我们执行的 ps 就是由 zsh 通过 fork-exec 创建的子进程而执行的
使用这样的一个命令我们也能清楚的看见 init 如上文所说是由进程 0 这个初始化进程来创建出来的子进程,而其他的进程基本是由 init 创建的子进程,或者是由它的子进程创建出来的子进程。所以 init是用户进程的第一个进程也是所有用户进程的父进程或者祖先进程。(ps 命令将在后续课程详解)
就像一个树状图,而 init 进程就是这棵树的根,其他进程由根不断的发散,开枝散叶
进程组与 Sessions
每一个进程都会是一个进程组的成员,而且这个进程组是唯一存在的,他们是依靠 PGID(process group ID)来区别的,而每当一个进程被创建的时候,它便会成为其父进程所在组中的一员。
一般情况,进程组的 PGID 等同于进程组的第一个成员的 PID,并且这样的进程称为该进程组的领导者,也就是领导进程,进程一般通过使用 getpgrp() 系统调用来寻找其所在组的 PGID,领导进程可以先终结,此时进程组依然存在,并持有相同的PGID,直到进程组中最后一个进程终结。
与进程组类似,每当一个进程被创建的时候,它便会成为其父进程所在 Session 中的一员,每一个进程组都会在一个 Session 中,并且这个 Session 是唯一存在的,
Session 主要是针对一个 tty 建立,Session 中的每个进程都称为一个工作(job)。每个会话可以连接一个终端(control terminal)。当控制终端有输入输出时,都传递给该会话的前台进程组。Session 意义在于将多个 jobs 囊括在一个终端,并取其中的一个 job 作为前台,来直接接收该终端的输入输出以及终端信号。 其他 jobs 在后台运行。
- 前台(foreground)就是在终端中运行,能与你有交互的
- 后台(background)就是在终端中运行,但是你并不能与其任何的交互,也不会显示其执行的过程
详见 PS
工作管理
bash(Bourne-Again shell)支持工作控制(job control),而 sh(Bourne shell)并不支持。
并且每个终端或者说 bash 只能管理当前终端中的 job,不能管理其他终端中的 job。比如我当前存在两个 bash 分别为 bash1、bash2,bash1 只能管理其自己里面的 job 并不能管理 bash2 里面的 job
| 命令 | 说明 |
& |
让命令在后台中运行 |
ctrl + c |
当一个进程在前台运作时, 终止它, 但是若是在后台的话就不行了 |
ctrl + z |
使我们的当前工作停止并丢到后台中去 |
jobs |
查看 被停止并放置在后台的工作 |
fg [%jobnumber] |
后台的工作拿到前台来, ubuntu 在 zsh 中需要 %,在 bash 中不需要 % |
fg [%jobnumber] |
让放置在后台工作运作 ubuntu 在 zsh 中需要 %,在 bash 中不需要 % |
让命令在后台中运行
ls &
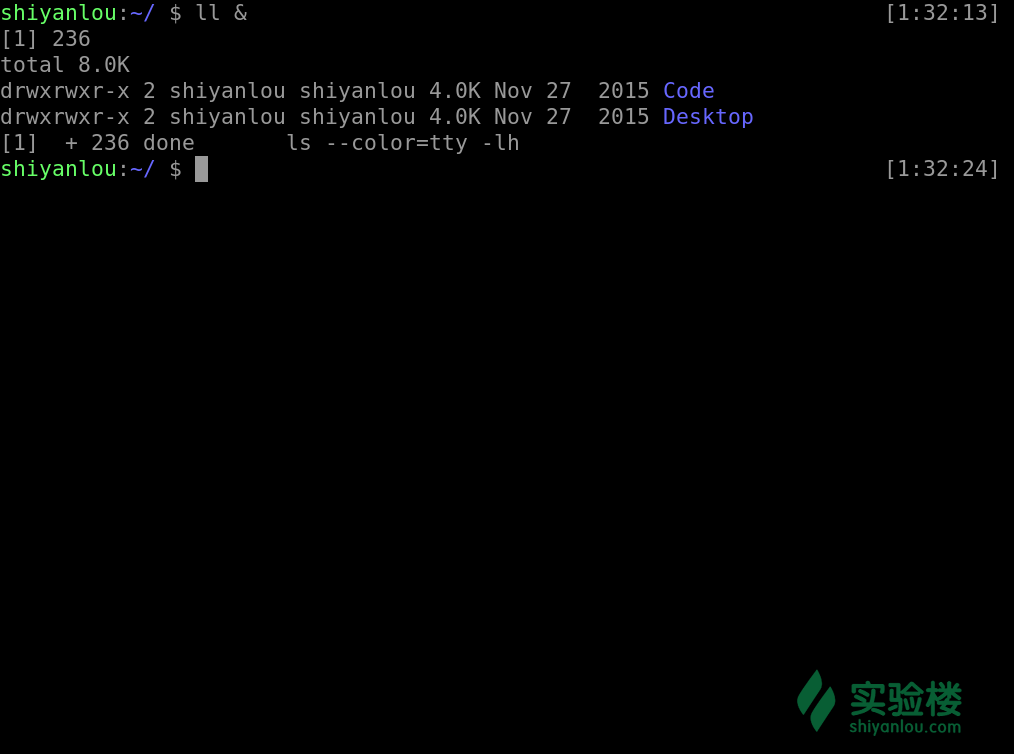
图中所显示的 [1] 236分别是该 job 的 job number 与该进程的 PID,而最后一行的 Done 表示该命令已经在后台执行完毕。
当前工作停止并丢到后台中去
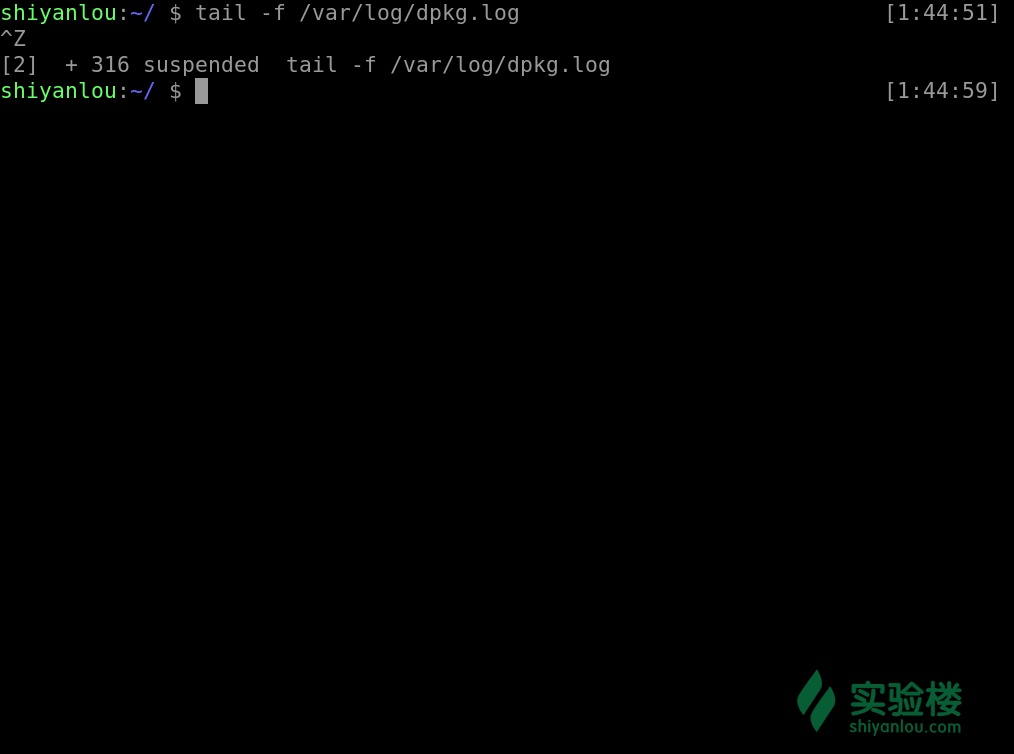
被停止并放置在后台的工作我们可以使用这个命令来查看
jobs
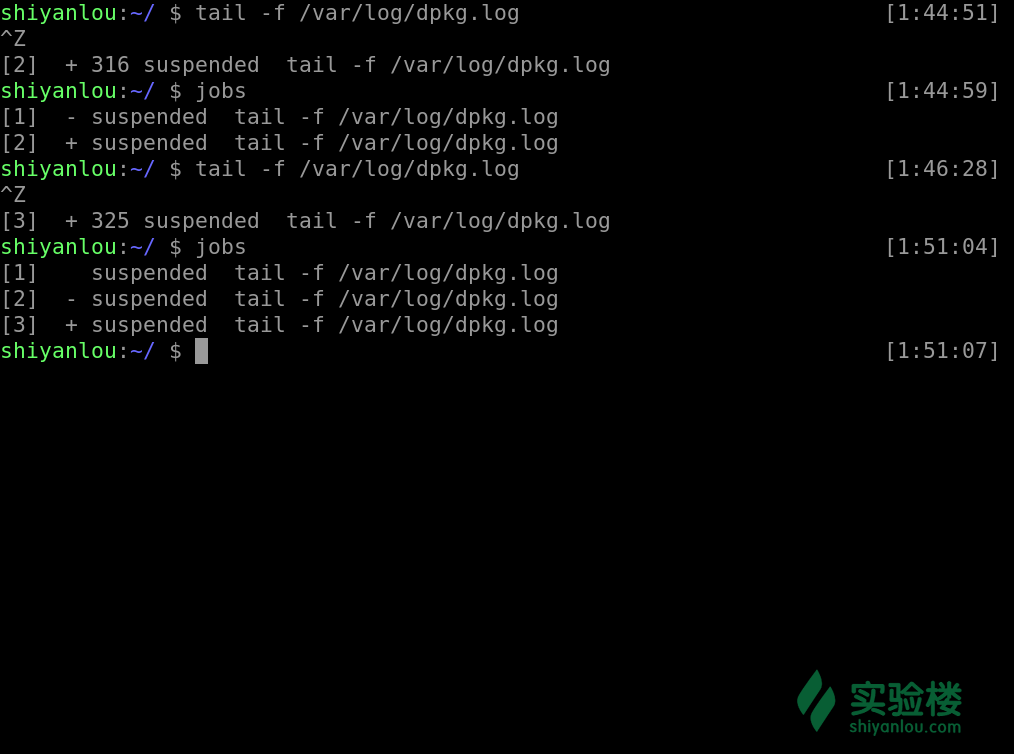
其中第一列显示的为被放置后台 job 的编号,而第二列的 + 表示最近(刚刚、最后)被放置后台的 job,同时也表示预设的工作,也就是若是有什么针对后台 job 的操作,首先对预设的 job,- 表示 **倒数第二(也就是在预设之前的一个)被放置后台的工作,倒数第三个(再之前的)以后都不会有这样的符号修饰,第三列表示它们的状态,而最后一列表示该进程执行的命令
我们可以通过这样的一个命令将后台的工作拿到前台来
#后面不加参数提取预设工作,加参数提取指定工作的编号
#ubuntu 在 zsh 中需要 %,在 bash 中不需要 %
fg [%jobnumber]
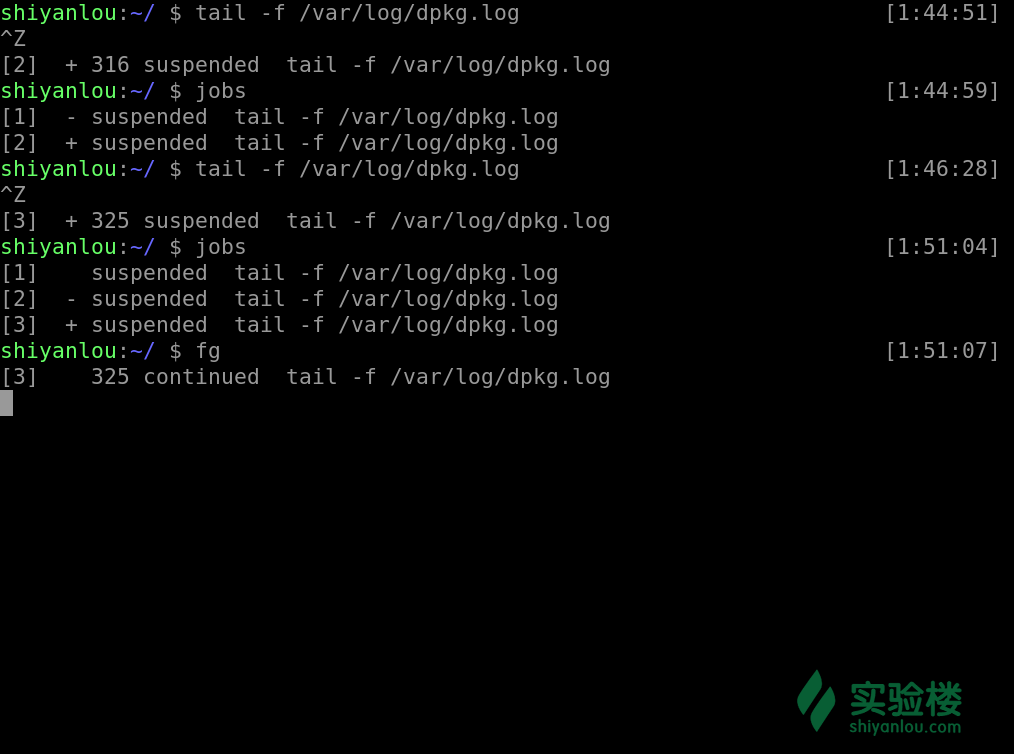
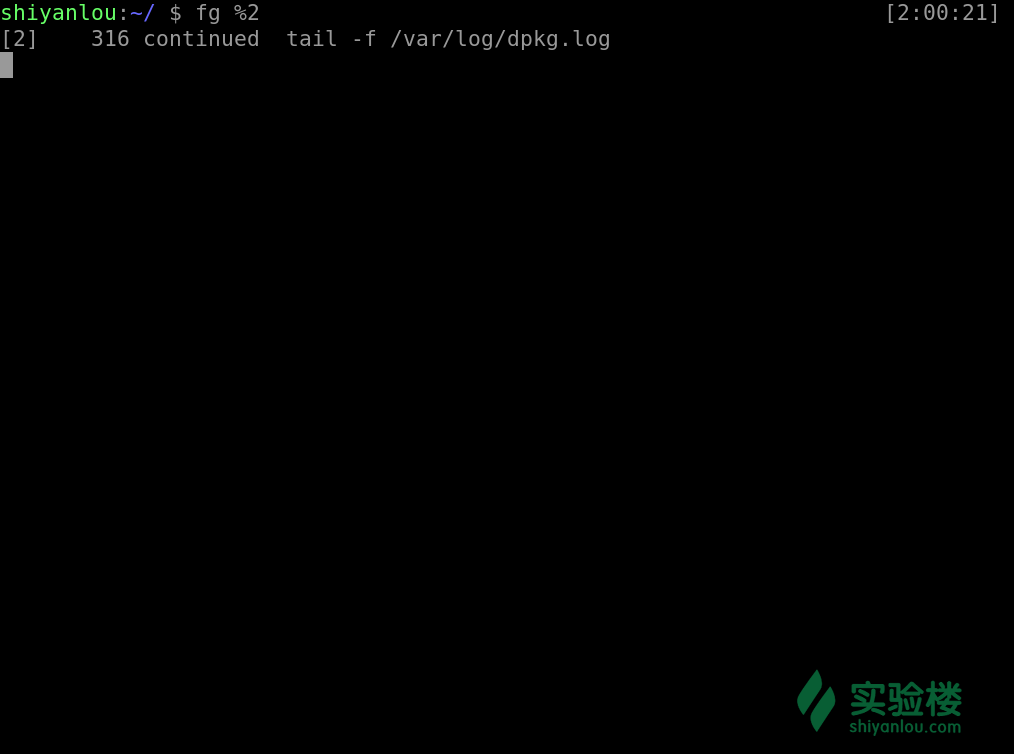
之前我们通过 ctrl + z 使得工作停止放置在后台,若是我们想让其在后台运作我们就使用这样一个命令
#与fg类似,加参则指定,不加参则取预设
bg [%jobnumber]
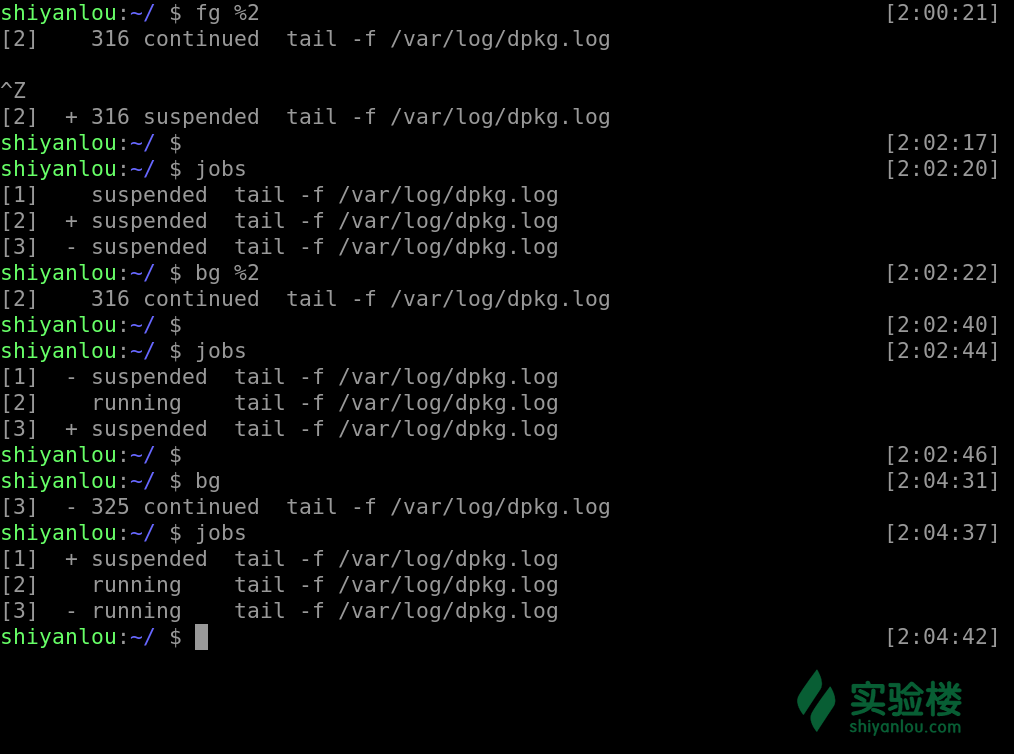
既然有方法将被放置在后台的工作提至前台或者让它从停止变成继续运行在后台,当然也有方法删除一个工作,或者重启等等, 详见kill
Linux 日志
在 Linux 中大部分的发行版都内置使用 syslog 系统日志,那么通过前期的课程我们了解到常见的日志一般存放在 /var/log 中,我们来看看其中有哪些日志
根据图中所显示的日志,我们可以根据服务对象粗略的将日志分为两类
- 系统日志: 主要是存放系统内置程序或系统内核之类的日志信息如 alternatives.log 、btmp 等 - 应用日志: 应用日志主要是我们装的第三方应用所产生的日志如 tomcat7 、apache2 等等。
接下来我们来看看常见的系统日志有哪些,他们都记录了怎样的信息
| 日志名称 | 记录信息 | |
|---|---|---|
alternatives.log |
系统的一些更新替代信息记录 | |
apport.log |
应用程序崩溃信息记录 | |
apt/history.log |
使用 apt-get 安装卸载软件的信息记录 |
|
apt/term.log |
使用 apt-get 时的具体操作,如 package 的下载、打开等 |
|
auth.log |
登录认证的信息记录 | |
boot.log |
系统启动时的程序服务的日志信息 | |
btmp |
错误的信息记录 | |
Consolekit/history |
控制台的信息记录 | |
dist-upgrade |
dist-upgrade 这种更新方式的信息记录 |
|
dmesg |
启动时,显示屏幕上内核缓冲信息,与硬件有关的信息 | |
dpkg.log |
dpkg 命令管理包的日志。 | |
faillog |
用户登录失败详细信息记录 | |
fontconfig.log |
与字体配置有关的信息记录 | |
kern.log |
内核产生的信息记录,在自己修改内核时有很大帮助 | |
lastlog |
用户的最近信息记录 | |
wtmp |
登录信息的记录。wtmp可以找出谁正在进入系统,谁使用命令显示这个文件或信息等 | |
syslog |
系统信息记录 |
history.log 与 term.log,两个日志文件的区别在于 history.log 主要记录了进行了哪个操作,相关的依赖有哪些,而 term.log 则是较为具体的一些操作,主要就是下载包,打开包,安装包等等的细节操作。
只闻其名,不见其人,我们并不能明白这些日志记录的内容。首先我们来看 alternatives.log 中的信息,我可以看看从alternatives.log 截取过来的内容
update-alternatives 2016-07-02 13:36:16: run with --install /usr/bin/x-www-browser x-www-browser /usr/bin/google-chrome-stable 200
update-alternatives 2016-07-02 13:36:16: run with --install /usr/bin/gnome-www-browser gnome-www-browser /usr/bin/google-chrome-stable 200
update-alternatives 2016-07-02 13:36:16: run with --install /usr/bin/google-chrome google-chrome /usr/bin/google-chrome-stable 200
我们可以从中得到的信息有程序作用,日期,命令,成功与否的返回码
我们用这样的命令来看看 auth.log 中的信息
less auth.log
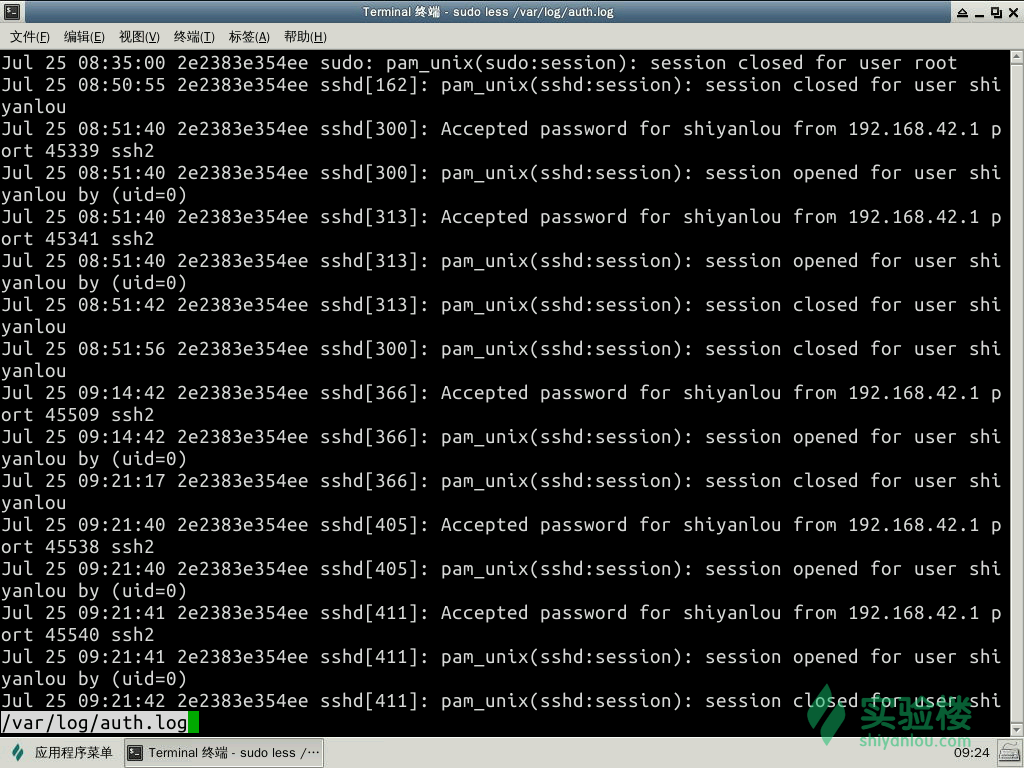
我们可以从中得到的信息有日期与 ip 地址的来源以及的用户与工具
然后我们来安装 git 这个程序
sudo apt-get install git
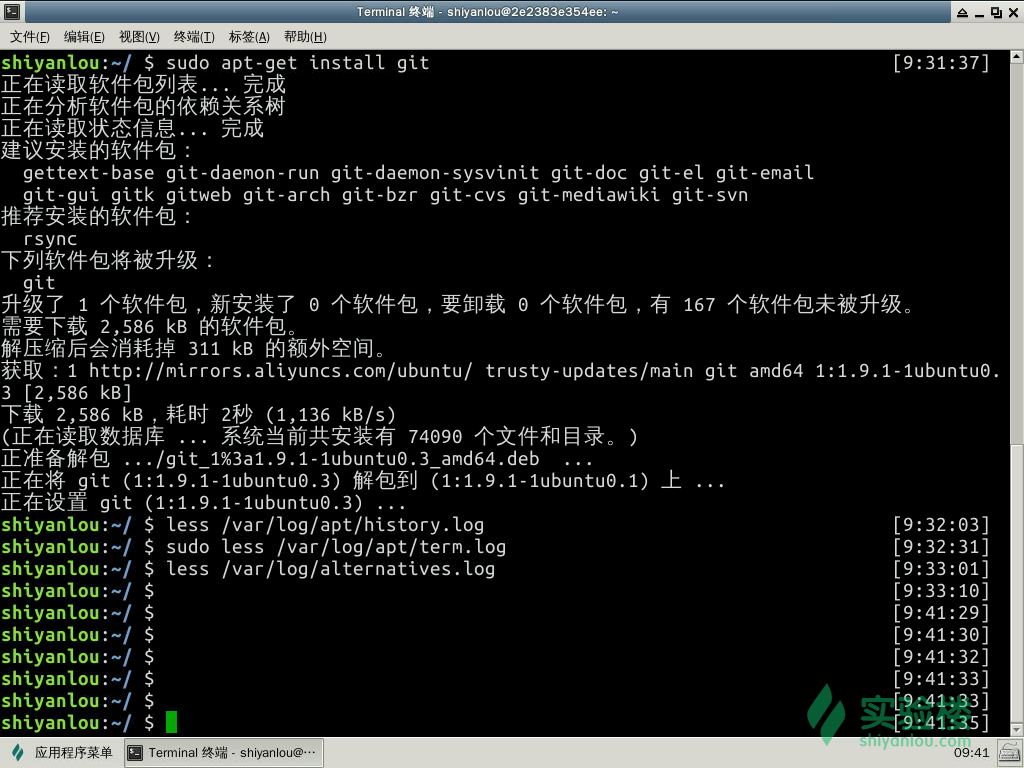
成功的执行之后我们再来查看两个日志的内容变化
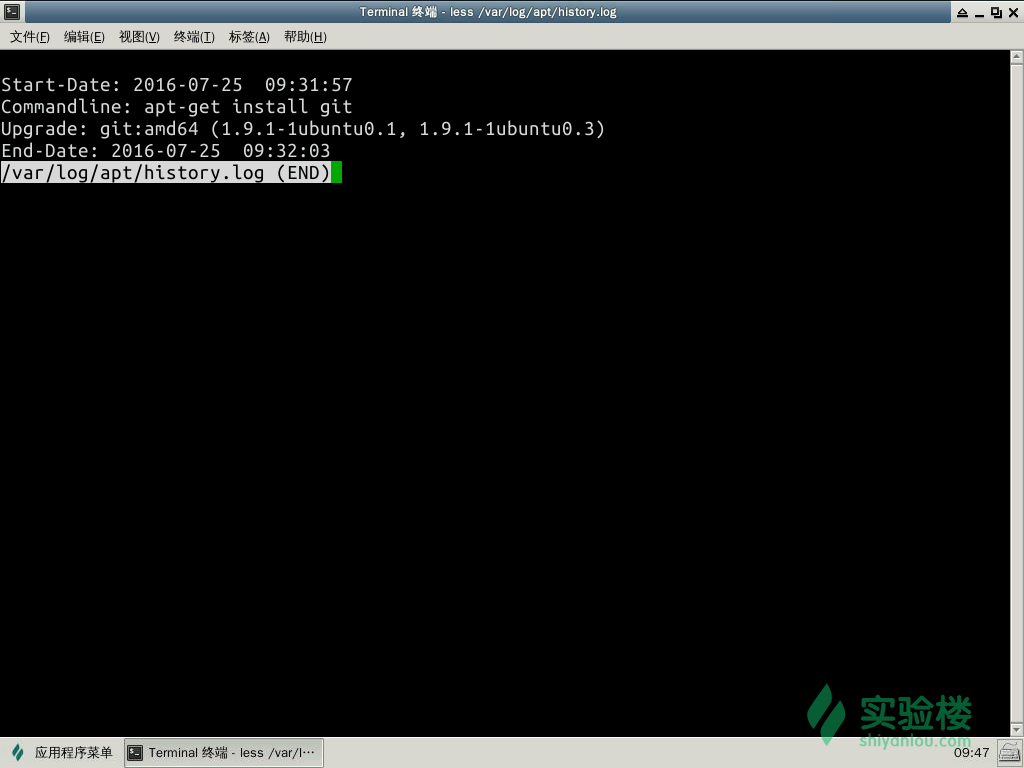
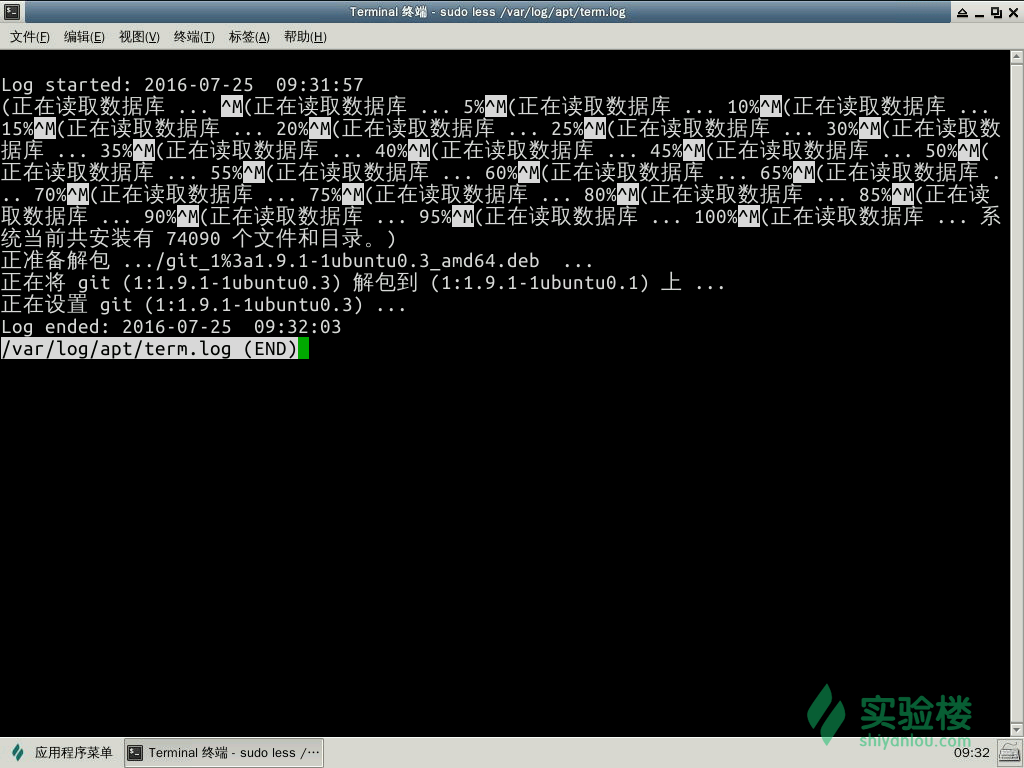
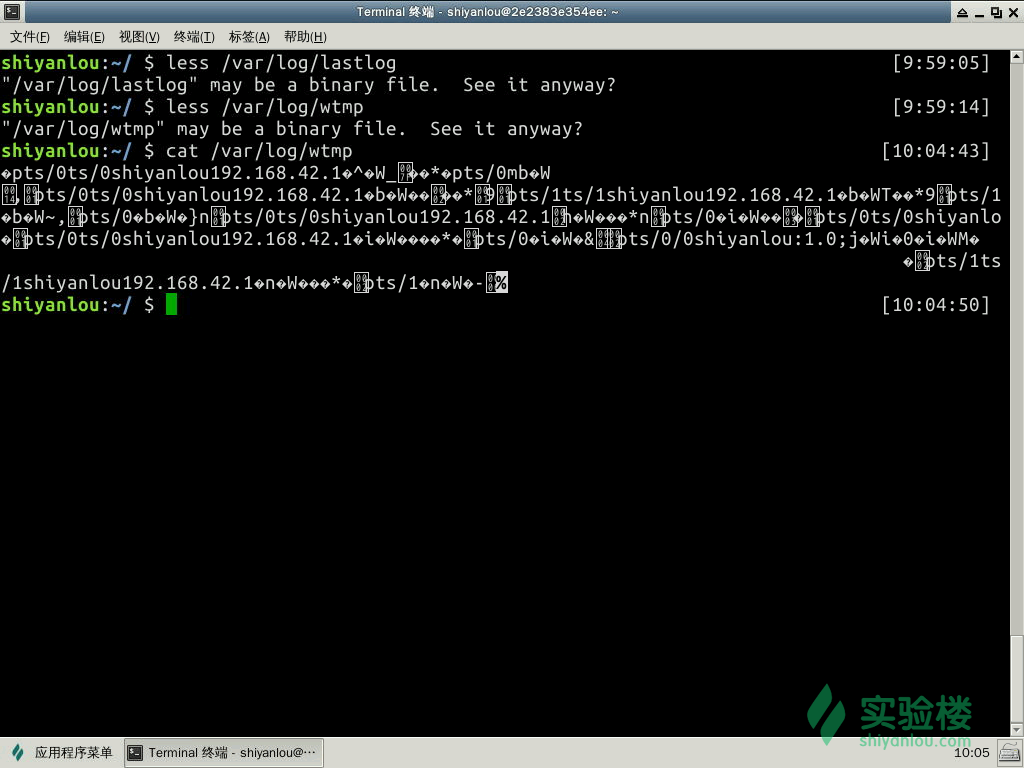
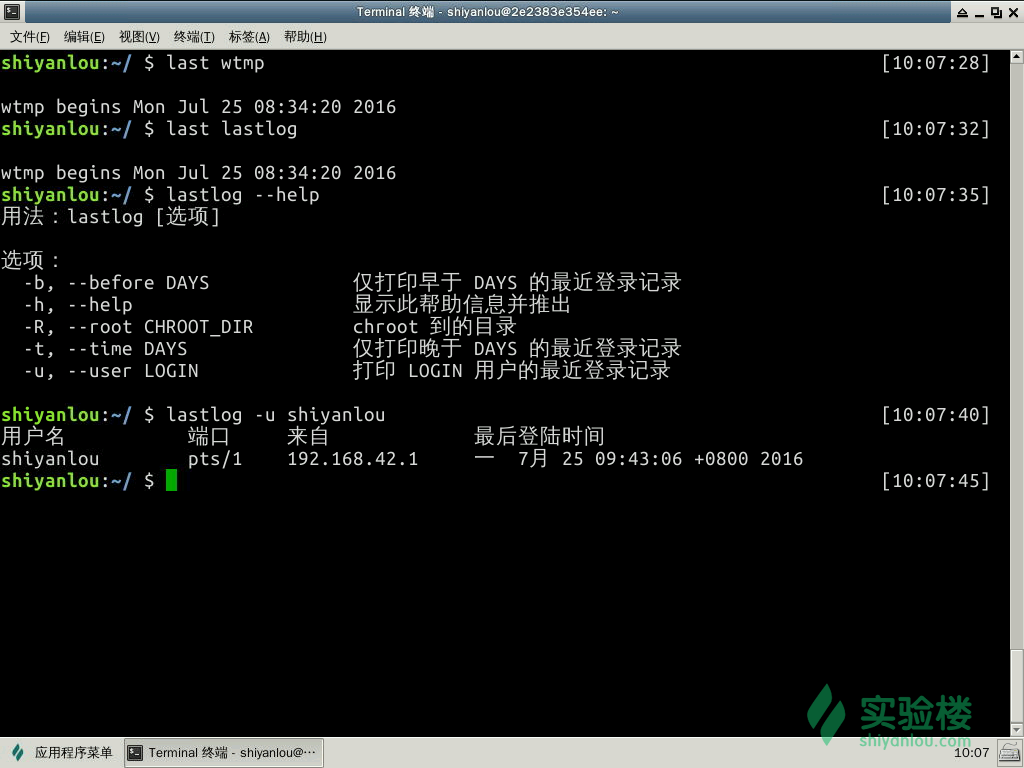
而这其中有两个比较特殊的日志wtmp,lastlog,因为这两个日志并不是 ASCII 文件而是被编码成了二进制文件,所以我们并不能直接使用 less、cat、more 这样的工具来查看,我们查看的方法是使用 last 与 lastlog 工具来提取其中的信息
配备日志
日志是如何产生的?通过上面的例子我们可以看出大部分的日志信息似乎格式都很类似,并且都出现在这个文件夹中。
这样的实现可以通过两种方式:
- 一种是由软件开发商自己来自定义日志格式然后指定输出日志位置;
- 一种方式就是 Linux 提供的日志服务程序,而我们这里系统日志是通过 syslog 来实现,提供日志管理服务。
syslog 是一个系统日志记录程序,在早期的大部分 Linux 发行版都是内置 syslog,让其作为系统的默认日志收集工具,虽然随着时代的进步与发展,syslog 已经年老体衰跟不上时代的需求,所以他被 rsyslog 所代替了,较新的 Ubuntu、Fedora 等等都是默认使用 rsyslog 作为系统的日志收集工具
rsyslog的全称是 rocket-fast system for log,它提供了高性能,高安全功能和模块化设计。rsyslog 能够接受各种各样的来源,将其输入,输出的结果到不同的目的地。rsyslog 可以提供超过每秒一百万条消息给目标文件。
这样能实时收集日志信息的程序是有其守护进程的,如 rsyslog 的守护进程便是 rsyslogd
因为一些原因本实验环境中默认并没有打开这个服务,我们可以手动开启这项服务,然后来查看
sudo apt-get update
sudo apt-get install -y rsyslog
sudo service rsyslog start
ps aux | grep syslog
首先我们来看 rsyslog 的配置文件是什么样子的,而 rsyslog 的配置文件有两个, 一个是 /etc/rsyslog.conf, 一个是 /etc/rsyslog.d/50-default.conf. 第一个主要是配置的环境,也就是 rsyslog 加载什么模块,文件的所属者等;而第二个主要是配置的 Filter Conditions
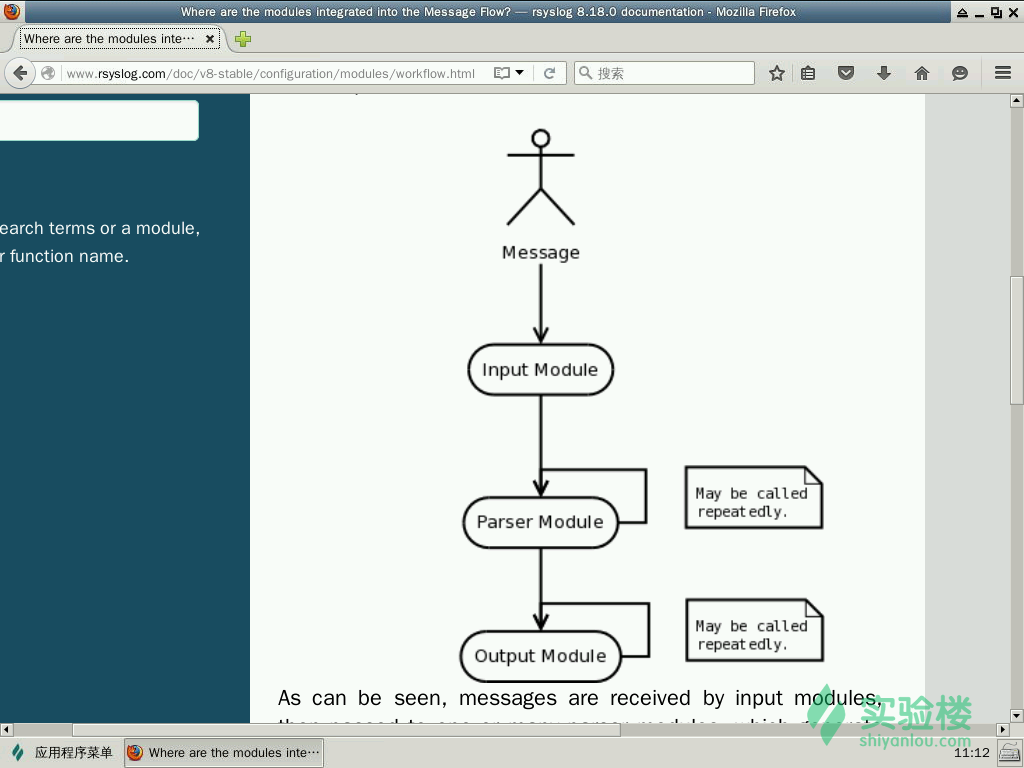
通过这个简单的流程图我们可以知道 rsyslog 主要是由 Input、Output、Parser 这样三个模块构成的,并且了解到数据的简单走向,首先通过 Input module 来收集消息,然后将得到的消息传给 Parser module,通过分析模块的层层处理,将真正需要的消息传给 Output module,然后便输出至日志文件中。
上文提到过 rsyslog 号称可以提供超过每秒一百万条消息给目标文件,怎么只是这样简单的结构。我们可以通过下图来做更深入的了解
Rsyslog 架构如图中所示,从图中我们可以很清楚的看见,rsyslog 还有一个核心的功能模块便是 Queue,也正是因为它才能做到如此高的并发。
第一个模块便是 Input,该模块的主要功能就是从各种各样的来源收集 messages,通过这些接口实现:
| 接口名 | 作用 | |
|---|---|---|
| im3195 | RFC3195 Input Module | |
| imfile | Text File Input Module | |
| imgssapi | GSSAPI Syslog Input Module | |
| imjournal | Systemd Journal Input Module | |
| imklog | Kernel Log Input Module | |
| imkmsg | /dev/kmsg Log Input Module | |
| impstats | Generate Periodic Statistics of Internal Counters | |
| imptcp | Plain TCP Syslog | |
| imrelp | RELP Input Module | |
| imsolaris | Solaris Input Module | |
| imtcp | TCP Syslog Input Module | |
| imudp | UDP Syslog Input Module | |
| imuxsock | Unix Socket Input |
在配置中 rsyslog 支持三种配置语法格式:
- sysklogd: 老的简单格式,一些新的语法特性不支持
- legacy rsyslog: dollar 符($)开头的语法,在 v6 及以上的版本还在支持,就如上文所说的 $ModLoad 还有一些插件和特性只在此语法下支持。而以 $ 开头的指令是全局指令,全局指令是 rsyslogd 守护进程的配置指令,每行只能有一个指令
- RainerScript: 最新的语法。在官网上 rsyslog 大多推荐这个语法格式来配置
注释有两种语法:
- 井号
# - C-style
/* .. */
执行顺序: 指令在 rsyslog.conf 文件中是从上到下的顺序执行的。
我们看向 /etc/rsyslog.d/50-default.conf 这个配置文件,这个文件中主要是配置的 Filter Conditions,也就是我们在流程图中所看见的 Parser & Filter Engine,它的名字叫 Selectors 是过滤 syslog 的传统方法,他主要由两部分组成,facility 与 priority,其配置格式如下
facility.priority log_location
其中一个 priority 可以指定多个 facility,多个 facility 之间使用逗号 , 分割开, rsyslog 通过 Facility 的概念来定义日志消息的来源,以便对日志进行分类,Facility 的种类有:
| 类别 | 解释 |
|---|---|
kern |
内核消息 |
user |
用户信息 |
mail |
邮件系统消息 |
daemon |
系统服务消息 |
auth |
认证系统 |
authpriv |
权限系统 |
syslog |
日志系统自身消息 |
cron |
计划安排 |
news |
新闻信息 |
local0~7 |
由自定义程序使用 |
而另外一部分 priority 也称之为 serverity level,除了日志的来源以外,对统一源产生日志消息还需要进行优先级的划分,而优先级的类别有以下几种:
| 类别 | 解释 |
|---|---|
emergency |
系统已经无法使用了 |
alert |
必须立即处理的问题 |
critical |
很严重了 |
error |
错误 |
warning |
警告信息 |
notice |
系统正常,但是比较重要 |
informational |
正常 |
debug |
debug的调试信息 |
panic |
很严重但是已淘汰不常用 |
none |
没有优先级,不记录任何日志消息 |
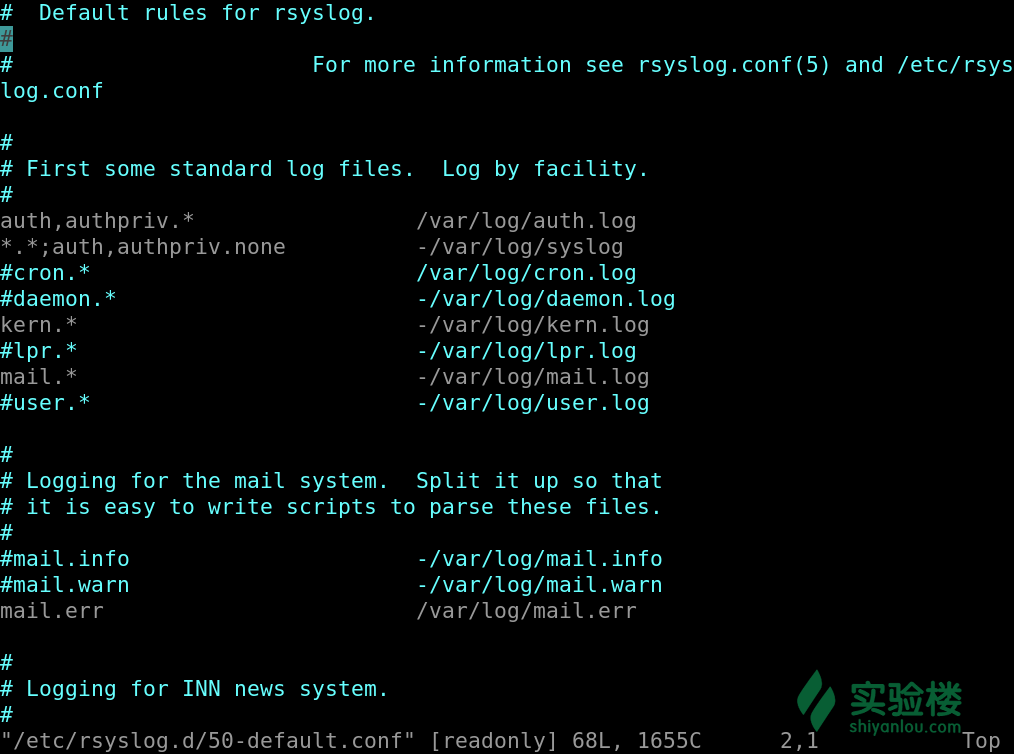
auth,authpriv.* /var/log/auth.log
这里的意思是 auth 与 authpriv 的所有优先级的信息全都输出于 /var/log/auth.log 日志中
而其中有类似于这样的配置信息意思有细微的差别
kern.* -/var/log/kern.log
- 代表异步写入,也就是日志写入时不需要等待系统缓存的同步,也就是日志还在内存中缓存也可以继续写入无需等待完全写入硬盘后再写入。通常用于写入数据比较大时使用。
logger
与日志相关的还有一个还有常用的命令 logger, logger 是一个 shell 命令接口,可以通过该接口使用 Syslog 的系统日志模块,还可以从命令行直接向系统日志文件写入信息。
#首先将syslog启动起来
sudo service rsyslog start
#向 syslog 写入数据
ping 127.0.0.1 | logger -it logger_test -p local3.notice &
#查看是否有数据写入
sudo tail -f /var/log/syslog
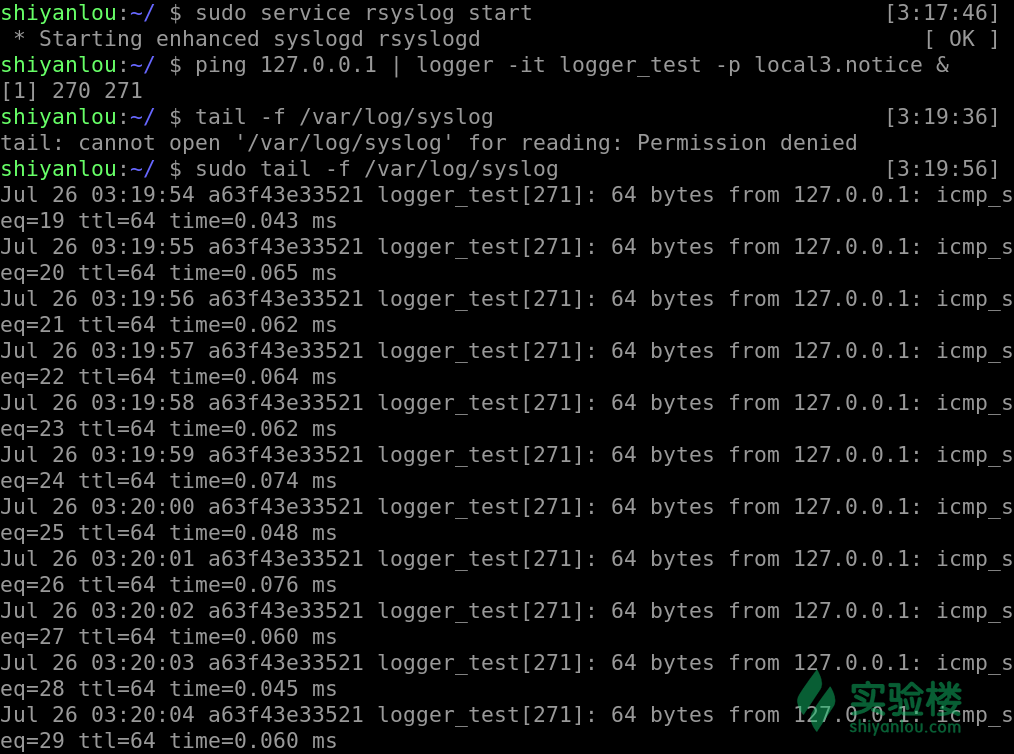
从图中我们可以看到我们成功的将 ping 的信息写入了 syslog 中,格式也就是使用的 rsyslog 的默认模板
我们可以通过 man 来查看 logger 的其他用法,
| 参数 | 内容 |
-i |
在每行都记录进程 ID |
-t |
添加 tag 标签 |
-p |
设置日志的 facility 与 priority |
logrotate
在本地的机器中每天都有成百上千条日志被写入文件中,更别说是我们的服务器,每天都会有数十兆甚至更多的日志信息被写入文件中,如果是这样的话,每天看着我们的日志文件不断的膨胀,那岂不是要占用许多的空间,所以有个叫 logrotate 的东西诞生了。
logrotate 程序是一个日志文件管理工具。用来把旧的日志文件删除,并创建新的日志文件。我们可以根据日志文件的大小,也可以根据其天数来切割日志、管理日志,这个过程又叫做“转储”。
大多数 Linux 发行版使用 logrotate 或 newsyslog 对日志进行管理。logrotate 程序不但可以压缩日志文件,减少存储空间,还可以将日志发送到指定 E-mail,方便管理员及时查看日志。
显而易见,logrotate 是基于 CRON 来运行的,其脚本是 /etc/cron.daily/logrotate;同时我们可以在/etc/logrotate 中找到其配置文件
cat /etc/logrotate.conf
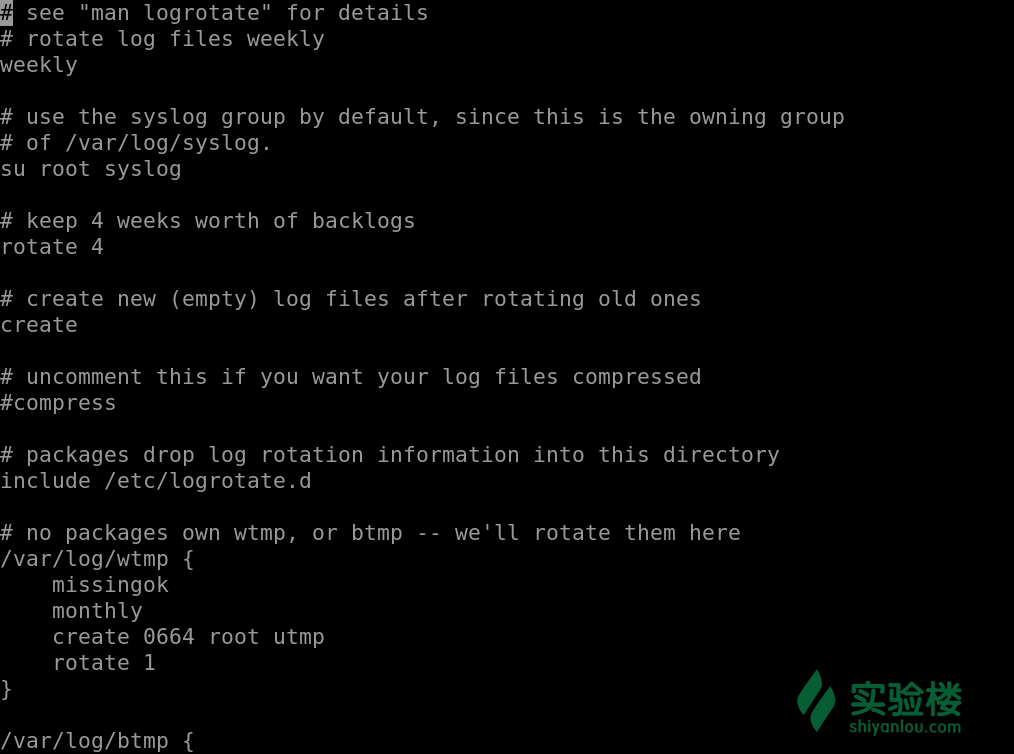
# see "man logrotate" for details //可以查看帮助文档
# rotate log files weekly
weekly //设置每周转储一次(daily、weekly、monthly当然可以使用这些参数每天、星期,月 )
# keep 4 weeks worth of backlogs
rotate 4 //最多转储4次
# create new (empty) log files after rotating old ones
create //当转储后文件不存在时创建它
# uncomment this if you want your log files compressed
compress //通过gzip压缩方式转储(nocompress可以不压缩)
# RPM packages drop log rotation information into this directory
include /etc/logrotate.d //其他日志文件的转储方式配置文件,包含在该目录下
# no packages own wtmp -- we'll rotate them here
/var/log/wtmp { //设置/var/log/wtmp日志文件的转储参数
monthly //每月转储
create 0664 root utmp //转储后文件不存在时创建它,文件所有者为root,所属组为utmp,对应的权限为0664
rotate 1 //最多转储一次
}
当然在 /etc/logrotate.d/ 中有各项应用的 logrotate 配置,还有更多的配置参数,可以使用 man 查看,如按文件大小转储,按当前时间格式命名等等参数配置。
access Linux by VNC
在linux 上装vnc server
sudo apt-get install x11vnc
x11vnc -storepassword #输入vnc 以后连接密码
x11vnc -usepw #要求用密码形式开启VNC server
#如果VNC 有闪屏问题, 频繁挑出VNC现象, 尝试开启x11vnc时候输入下面参数让它永远运行
x11vnc -usepw -forever
在mac 上搜索screen sharing 打开, 输入ip地址 (ifconfig 显示的), 这个ip 是内网,只能在同一个路由器下面使用
避免在mac上每次登陆 重复输入密码
ssh-keygen
Enter passphrase 表示用的密码代替实际用的密码,避免密码的话,直接回车

把在mac 上的public key 推送到linux
ssh-copy-id -i y.pub becks@@具体的ip #y.pub 是上面储存的file
#If the -i option is given then the identity file (defaults to ~/.ssh/id_rsa.pub) is used, regardless of whether there are any keys in your ssh-agent.
apt-get
比如我们想安装一个软件,名字叫做 w3m(w3m是一个命令行的简易网页浏览器),那么输入如下命令:
APT是Advance Packaging Tool(高级包装工具)的缩写,是Debian及其派生发行版的软件包管理器,APT可以自动下载,配置,安装二进制或者源代码格式的软件包,因此简化了Unix系统上管理软件的过程。APT最早被设计成dpkg的前端,用来处理deb格式的软件包。现在经过APT-RPM组织修改,APT已经可以安装在支持RPM的系统管理RPM包。这个包管理器包含以 apt- 开头的多个工具,如
apt-get apt-cache apt-cdrom等,在Debian系列的发行版中使用。
当你在执行安装操作时,首先apt-get 工具会在本地的一个数据库中搜索关于 w3m 软件的相关信息,并根据这些信息在相关的服务器上下载软件安装,这里大家可能会一个疑问:既然是在线安装软件,为啥会在本地的数据库中搜索?要解释这个问题就得提到几个名词了:
- 软件源镜像服务器
- 软件源
我们需要定期从服务器上下载一个软件包列表,使用 sudo apt-get update 命令来保持本地的软件包列表是最新的(有时你也需要手动执行这个操作,比如更换了软件源),而这个表里会有软件依赖信息的记录,对于软件依赖,我举个例子:我们安装 w3m 软件的时候,而这个软件需要 libgc1c2 这个软件包才能正常工作,这个时候 apt-get 在安装软件的时候会一并替我们安装了,以保证 w3m 能正常的工作。
apt-get 是用于处理 apt包的公用程序集,我们可以用它来在线安装、卸载和升级软件包等,下面列出一些apt-get包含的常用的一些工具:
| 工具 | 说明 |
|---|---|
install |
其后加上软件包名,用于安装一个软件包 |
update |
从软件源镜像服务器上下载/更新用于更新本地软件源的软件包列表 |
upgrade |
升级本地可更新的全部软件包,但存在依赖问题时将不会升级,通常会在更新之前执行一次update, is used to install the newest versions of all packages currently installed on the system from the sources in /etc/apt/sources.list |
dist-upgrade |
解决依赖关系并升级(存在一定危险性) attempt to upgrade the most important packages at the expense of less important ones if necessary. |
remove |
移除已安装的软件包,包括与被移除软件包有依赖关系的软件包,但不包含软件包的配置文件(leaves configuration files on the system) |
autoremove |
移除之前被其他软件包依赖,但现在不再被使用的软件包, remove packages that were automatically installed to satisfy dependencies for othe packages and are now no longer needed |
purge |
与remove相同,但会完全移除软件包,包含其配置文件(cany onfiguration files are deleted too) |
clean |
移除下载到本地的已经安装的软件包,默认保存在/var/cache/apt/archives/ |
autoclean |
移除已安装的软件的旧版本软件包 |
下面是一些apt-get常用的参数:
| 参数 | 说明 |
|---|---|
-y or -yes or --assume-yes |
自动回应是否安装软件包的选项,在一些自动化安装脚本中使用这个参数将十分有用, automatically yes to prompt |
-s or --simulate |
模拟安装. No action. performs a simulation of events that would occur based on current system state but do not actually change the system |
-q or --quite |
静默安装方式,指定多个q或者-q=#,#表示数字,用于设定静默级别,这在你不想要在安装软件包时屏幕输出过多时很有用 produce output suitable for logging, omiting progress indicators |
-f or --fix-broken |
修复损坏的依赖关系, attempt to correct system with broken dependency in place |
-d or --download-only |
只下载不安装 |
--reinstall |
重新安装已经安装但可能存在问题的软件包 |
--install-suggests |
同时安装APT给出的建议安装的软件包 |
有时候你需要同时安装多个软件包,你还可以使用正则表达式匹配软件包名进行批量安装。
安装
$ sudo apt-get install w3m
注意:如果你在安装一个软件之后,无法立即使用Tab键补全这个命令,你可以尝试先执行source ~/.zshrc,然后你就可以使用补全操作。
w3m https://www.shiyanlou.com/faq
重新安装
如不知道软件包完整名, 通常我们是使用Tab键补全软件包名
$ sudo apt-get --reinstall install w3m
升级
# 更新软件源
$ sudo apt-get update
# 升级没有依赖问题的软件包
$ sudo apt-get upgrade
# 升级并解决依赖关系
$ sudo apt-get dist-upgrade
卸载软件
sudo apt-get remove w3m
或者,你可以执行
# 不保留配置文件的移除
$ sudo apt-get purge w3m
# 或者 sudo apt-get --purge remove
# 移除不再需要的被依赖的软件包
$ sudo apt-get autoremove
软件搜索
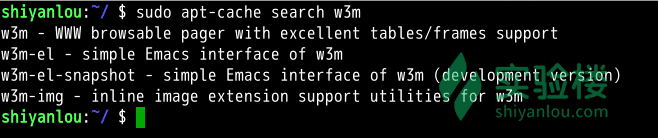
当自己刚知道了一个软件,想下载使用,需要确认软件仓库里面有没有,就需要用到搜索功能了,命令如下:
sudo apt-cache search softname1 softname2 softname3……
apt-cache 命令则是针对本地数据进行相关操作的工具,search 顾名思义在本地的数据库中寻找有关 softname1 softname2 …… 相关软件的信息。现在我们试试搜索一下之前我们安装的软件 w3m ,如图:
sudo apt-get install chromium-broswer #install chrome
apt-get(urbantu): install, uninstall, update packages. apt: advance packaging tool
对于centos: 用yum, dnf instead of apt-get
sudo apt-get update #resync your local package file to the server package file, update all the packages
java -version #check if java installed, and if so check version
php5 -version #check if php installed, 如果没有install 会给出install的hint
sudo apt-get install php5 #安装首先what is required extra dependency to install php5, 也会显示多少space required to install
php5 -v #显示php5 version
sudo apt-get remove php5 #remove php5
sudo apt-get remove --purge php5 #remove all configuration file related to php5
sudo apt-get autoremove #auto remove the dependency which required for the package(php5) and no longer needed for other packages
awk
awk 所有的操作都是基于 pattern(模式)—action(动作)对来完成的,如下面的形式
pattern {action}
你可以看到就如同很多编程语言一样,它将所有的动作操作用一对{}花括号包围起来。其中pattern通常是表示用于匹配输入的文本的“关系式”或“正则表达式”,action则是表示匹配后将执行的动作。在一个完整awk操作中,这两者可以只有其中一个,
- 如果没有pattern则默认匹配输入的全部文本,
- 如果没有action则默认为打印匹配内容到屏幕。
awk 处理文本的方式,是将文本分割成一些“字段”,然后再对这些字段进行处理,默认情况下,awk 以空格作为一个字段的分割符,不过这不是固定的,你可以任意指定分隔符,下面将告诉你如何做到这一点
awk命令基本格式
awk [-F fs] [-v var=value] [-f prog-file | 'program text'] [file...]
其中-F参数用于预先指定前面提到的字段分隔符(每一行/段内)(还有其他指定字段的方式) ,-v用于预先为awk程序指定变量,-f参数用于指定awk命令要执行的程序文件,或者在不加-f参数的情况下直接将程序语句放在这里,最后为awk需要处理的文本输入,且可以同时输入多个文本文件
先用vim新建一个文本文档
$ vim test
包含如下内容:
I like linux
www.shiyanlou.com
使用awk将文本内容打印到终端
# "quote>" 不用输入
awk '{
> print
> }' test
# 或者写到一行
awk '{print}' test
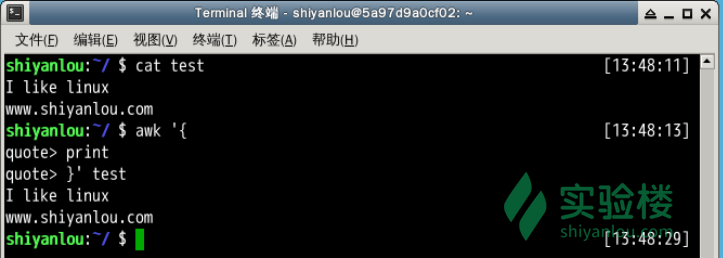
在这个操作中省略了pattern,所以awk会默认匹配输入文本的全部内容,然后在{}花括号中执行动作,即print打印所有匹配项,这里是全部文本内容
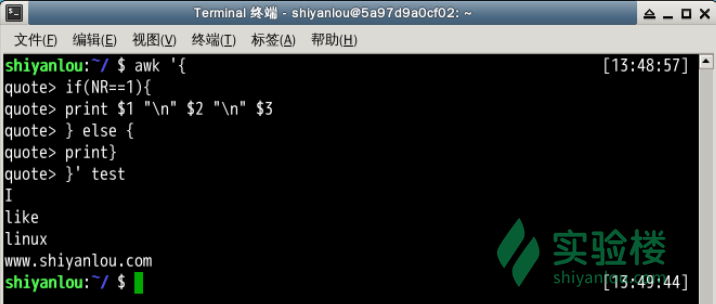
将test的第一行的每个字段单独显示为一行
awk '{
> if(NR==1){
> print $1 "\n" $2 "\n" $3
> } else {
> print}
> }' test
# 或者
awk '{
> if(NR==1){
> OFS="\n"
> print $1, $2, $3
> } else {
> print}
> }' test
- 你首先应该注意的是,这里我使用了
awk语言的分支选择语句if,它的使用和很多高级语言如C/C++语言基本一致,如果你有这些语言的基础,这里将很好理解。 - 另一个你需要注意的是
NR,NF与OFS,这两个是awk内建的变量,NR表示当前读入的记录数,你可以简单的理解为当前处理的行数,NF: 这行都多少个 字段OFS表示输出时的字段分隔符,默认为” “空格,如上图所见,我们将字段分隔符设置为\n换行符,所以第一行原本以空格为字段分隔的内容就分别输出到单独一行了。然后是$N其中N为相应的字段号,它表示引用相应的字段,因为我们这里只有三个字段,所以只引用到了$3。除此之外另一个这里没有出现的$0,它表示引用当前记录(当前行)的全部内容。
| 变量名 | 说明 |
|---|---|
FILENAME |
当前输入文件名,若有多个文件,则只表示第一个。如果输入是来自标准输入,则为空字符串 |
$0 |
当前记录的内容 |
$N |
N表示字段号,最大值为NF变量的值 |
FS |
字段分隔符(当前行的分隔符),由正则表达式表示,默认为” “空格 |
RS |
输入记录分隔符(行与行之间分隔符),默认为”\n”,即一行为一个记录 |
NF |
a variable indicating the number of fields (i.e. number of “columns”) on an input line |
NR |
indicating the number of records (i.e. current line number) that’s accumulated across multiple files read |
FNR |
当前输入文件的记录数,请注意它与NR的区别 |
OFS |
输出字段分隔符,默认为” “空格 |
ORS |
输出记录分隔符,默认为\n |
BEGIN |
a code block with a “BEGIN” prefix will be executed before any line reads. 在读取所有输入前执行 |
END |
The code block with an “END” prefix is only executed after the last line is read. 在读取所有输入后执行 |
$i |
the i-th field of the input line |
关于awk的内容本课程将只会包含这些内容,如果你想了解更多,请期待后续课程,或者参看一下链接内容:
将test的第二行的以点为分段的字段换成以空格为分隔
$ awk -F'.' '{
> if(NR==2){
> print $1 "\t" $2 "\t" $3
> }}' test
# 或者
$ awk '
> BEGIN{
> FS="."
> OFS="\t" # 如果写为一行,两个动作语句之间应该以";"号分开
> }{
> if(NR==2){
> print $1, $2, $3
> }}' test
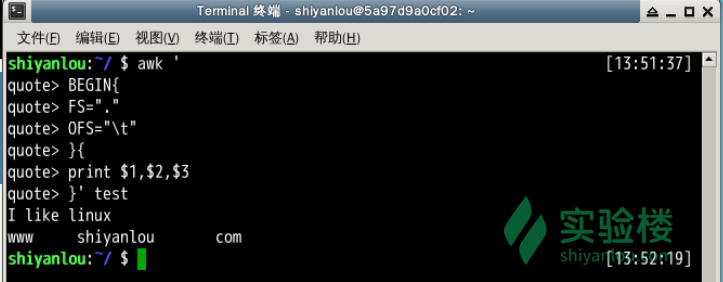
说明:这里的-F参数,前面已经介绍过,它是用来预先指定待处理记录的字段分隔符。我们需要注意的是除了指定OFS我们还可以在print 语句中直接打印特殊符号如这里的\t,print打印的非变量内容都需要用""一对引号包围起来。上面另一个版本,展示了实现预先指定变量分隔符的另一种方式,即使用BEGIN,就这个表达式指示了,其后的动作将在所有动作之前执行,这里是FS赋值了新的"."点号代替默认的" "空格
注意:首先说明一点,我们在学习和使用awk的时候应该尽可能将其作为一门程序语言来理解,这样将会使你学习起来更容易,所以初学阶段在练习awk时应该尽量按照我那样的方式分多行按照一般程序语言的换行和缩进来输入,而不是全部写到一行(当然这在你熟练了之后是没有任何问题的)
bashrc
bashrc is a script executed whenever a new terminal session start in interactive mode
some linux system, .bashrc file exist when a new terminal session start. Some not
Bashrc file is used for setting up environment variable such as Java. When use git, which repo you checked or cloned, use Bashrc
ls -a #在home directory ls -a 可以看见有.bashrc
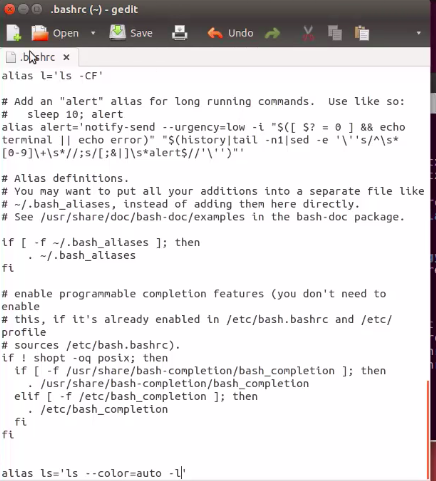
nano .bashrc #查看.bashrc
gedit .bashrc #查看 .bashrc
可以修改 .bashrc file 比如加上alias ls=’ls –color=auto -l’, 之后open new terminal, 输入ls, 显示long list of ls
Bash Script
Script: txt file contain sequence of command
nano myscript.sh #open editor
#! /bin/bash #需要contain location of bash
which bash #会告诉哪里有bash,give location
./myscript.sh #./ 是去run bash script
#显示permission denied 因为file created not have execute permission
#先给permission
chmod +x myscript.sh #give permission for all groups
./myscript.sh #显示会成功

cal
show conventially formatted calendar on your command line
cal #显示calendar, weekday on the top
ncal #显示calendar, weekday on the left
cal 2016 #显示2016的calendar
cal 2 2016 #显示2016年 2月 calendar
cal -3 #give you current month, previous month and next month calendar
#default 是 -1, 比如cal, 等于cal -1
cat / tac
cat: 1. Display Txt 2. combine Txt file 3. Create new Txt file
tac: 为倒序显示 syntax: cat options file1 file2 …
cat Hello World #会打印 echo Hello world
#Ctrl D means the end of cat command
cat list1.txt #显示list1.txt 所有内容
cat list1.txt | sort #显示list1.txt 根据每行sort 后的顺序打印
cat list1.txt list2.txt #显示list1.txt 和list2.txt所有内容,先显示list1的再显示list2的
cat -b list1.txt #把list1.txt的 不是blank的line(空行) 显示序号
#-n 显示行数
cat -n list1.txt #把list1.txt的 所有行(空行或者不空行) 都显示序号
cat -s list1.txt #squeeze 连续 blank line to one blank line
cat -E list1.txt #add $ at the end of each line
man cat #显示cat所有function
cat > test.txt #把接下来input的内容 output 到test.txt,输完了 按Ctrl+D, test.txt之前内容被remove
cat >> text.txt #把接下来input的内容 append 到test.txt
cat list1.txt list2.txt > out.txt #把mlist1, list2的内容合并,生成out.txt
cat list1.txt list2.txt > list2.txt #这样是不行的,不能把input 当成output file
cat list1.txt >> list2.txt #修改上面一行的error,append list1.txt 到list2.txt
cd
home directory和root directory 不一样, root是/, home 是 /Users/ username 的文件夹
cd / #go to root directory
cd ~ #home directory
cd .. #到parent directory
cd Documents #go to Document Directory
cd /home/programming/Documents/ #功能与上面一样, Go to Document Directory
cd My\ Books # go to My Books folder, 在My Books中间有空格
cd "My Books" #功能与上面一样
cd 'My Books' #功能与上面一样
chmod, File Permissions
drwxr-xr-x 1 beckswu staff 22 Jul 23 18:56 file: d means directory
-rw-rw-r- 1 beckswu staff 没有d 表示normal file, 如果开头是c, 表示character special file。如果是b,表示binary special file
1表示symbolic links of the file, 接下来表示owner of the file, next is the group of the file, 22 表示size of the file, July 23 18:56 date of created. file is the name of file
symbolic link is a term for any file that contains a reference to another file or directory in the form of an absolute or relative path and that affects pathname resolution
如果没有r access, 不能用cat 打印file
第一个字母表示文件类型:
- d: 目录
- l: 软连接。 硬链接不常用,软链接相当于windows 快捷方式
- b: 块设备
- c: character file
- s: socket
- p: 管道
- -: 普通文件
接下来每三个字母或 ‘-‘ 是一组, 第一组表示owner access, 第二组表示owner 所属group access, 第三堆表示 everybody else(其他用户)的access,
- r : reading access
- w : writing access
- x : executing access. 执行权限像windows exe
不过 Linux 上不是通过文件后缀名来区分文件的类型。你需要注意的一点是,一个目录同时具有读权限和执行权限才可以打开并查看内部文件,而一个目录要有写权限才允许在其中创建其它文件,这是因为目录文件实际保存着该目录里面的文件的列表等信息。
u, g, o, a 分别表示user, group, others 和 all users
#o means other group, + add permission, - minus permission,
chmod o+x file #给file 的other user(第三堆) 加execute permission
chmod g+x file #给file 的group(第二堆) 加execute permission
chmod g-wx file #给file的group 移走write execute permission
chmod ug=rwx file #给user(owner), group read write execute permission
chmod a-rwx file #给所有的(owerner, group, others) remove read, write, execution permission
chmod u+rw, g=rw, o+r file #给user add read write, 给group read, write permission, 给other add read permission
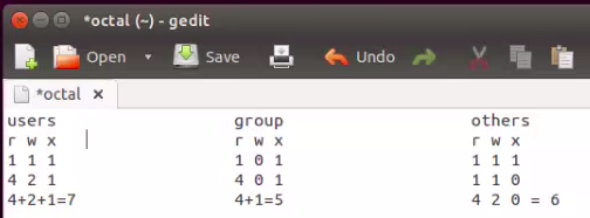
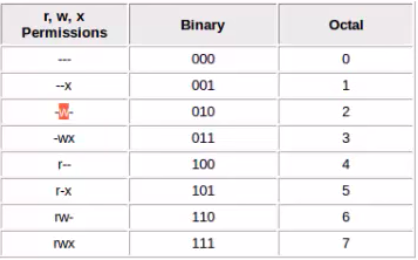
二进制数字:
rwx -> 1*2**2 +1*2**1 + 1*2**0 = 7
chmod 600 file #表示给owner 6 ( r, w), group 0, other user 0
chmod 755 file.txt #give user read, write execute(7), give both group and othe group read and execute access
Octal & Numerical Permissions
change file ownership
sudo chown becks iphone6 #如果iphone6 不属于becks, 可以改变ownership
chown
修改文件拥有者
chmod becks newfile.txt #把文件修改为becks 为onwer
#or
sudo chmod becks newfile.txt
col
col 命令可以将Tab换成对等数量的空格键,或反转这个操作。 (filter reversed line from input)
使用方式: col [option]
| 命令 | 说明 |
|---|---|
-x |
将Tab转换为空格 |
-h |
将空格转换为Tab(默认选项) |
# 查看 /etc/protocols 中的不可见字符,可以看到很多 ^I ,这其实就是 Tab 转义成可见字符的符号
$ cat -A /etc/protocols
# 使用 col -x 将 /etc/protocols 中的 Tab 转换为空格,然后再使用 cat 查看,你发现 ^I 不见了
$ cat /etc/protocols | col -x | cat -A
colrm
colrm start 和stop 是inclusive 的
colrm [start] [stop]
e.g.
cat file.txt
abcdefgh
colrm 4 6
abcgh
cp
CP: copy and paste
cp options source destination
cp file1.txt file2.txt #if file2.txt not exist will creat file2.txt. Content from file1 will copy to file2
cp file1.txt dir1 # 把file1.txt copy 到directory 1
cp file1.txt file2.txt dir1 # 把file1.txt 和file2.txt copy 到directory 1
cp -i file1.txt file2.txt dir1 #如果directory 1 里面有file1.txt -i 会ask 是否要overwrite, 选n, 就会只copy file2 不会copy file1
cp ../f1.txt ../f2.txt . #从parent directory copy f1.txt和f2.txt 到现在directory, 因为没有-i, 会overwrite
cp dir1 dir3 # error, 因为dir1 有文件,不能被copy
cp -R dir1 dir3 # -R means recursive copy,copy everything from dir1 to dir3
#whenever destination (dir3) doesn't exist, it create destination and copy all content from source
#如果存在destination, 只copy paste
cp -vR dir1 dir3 #显示详细的copy 哪些文件
cp file* folder2/ #把当前文件夹下所有以file 开头文件都copy

crontab
crontab属于守护进程:守护进程是一直运行的一种进程,在 Linux 系统启动时启动,在系统关闭时终止
crontab 命令常见于 Unix 和类 Unix 的操作系统之中(Linux 就属于类 Unix 操作系统),用于设置周期性被执行的指令。
crontab 命令从输入设备读取指令,并将其存放于 crontab 文件中,以供之后读取和执行。通常,crontab 储存的指令被守护进程激活,crond 为其守护进程,crond 常常在后台运行,每一分钟会检查一次是否有预定的作业需要执行。
通过 crontab 命令,我们可以在固定的间隔时间执行指定的系统指令或 shell script 脚本。时间间隔的单位可以是分钟、小时、日、月、周的任意组合。
这里我们看一看crontab 的格式
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
crontab 在本实验环境中需要做一些特殊的准备,首先我们会启动 rsyslog,以便我们可以通过日志中的信息来了解我们的任务是否真正的被执行了(在本实验环境中需要手动启动,而在自己本地中 Ubuntu 会默认自行启动不需要手动启动)
sudo apt-get install -y rsyslog
sudo service rsyslog start
在本实验环境中 crontab 也是不被默认启动的,同时不能在后台由 upstart 来管理,所以需要我们来启动它:
sudo cron -f &
crontab 使用
crontab -e
Cron time Format: five values separated by spaces, 必须保证有五位, 如果想重复run 比如每两分钟, append a slash */ ,
| Character | Descriptor | Acceptable values |
|---|---|---|
| 1 | Minute | 0 to 59, or * (no specific value) |
| 2 | Hour | 0 to 23, or * for any value. All times UTC. |
| 3 | Day of the month | 1 to 31, or * (no specific value) |
| 4 | Month | 1 to 12, or * (no specific value) |
| 5 | Day | of the week 0 to 7 (0 and 7 both represent Sunday), or * (no specific value) |
| Cron time string | Description | |
|---|---|---|
30 * * * * |
Execute a command at 30 minutes past the hour, every hour. | |
0 13 * * 1 |
Execute a command at 1:00 p.m. UTC every Monday. | |
*/5 * * * * |
Execute a command every five minutes. | |
0 */2 * * * |
Execute a command every second hour, on the hour. |
文档的最后一排加上这样一排命令,该任务是每分钟我们会在/home/shiyanlou目录下创建一个以当前的年月日时分秒为名字的空白文件
*/1 * * * * touch /home/shiyanlou/$(date +\%Y\%m\%d\%H\%M\%S) #数字1
注意 % 在 crontab 文件中,有结束命令行、换行、重定向的作用,前面加 \ 符号转义,否则,% 符号将执行其结束命令行或者换行的作用,并且其后的内容会被做为标准输入发送给前面的命令。
添加成功后我们会得到最后一排 installing new crontab 的一个提示
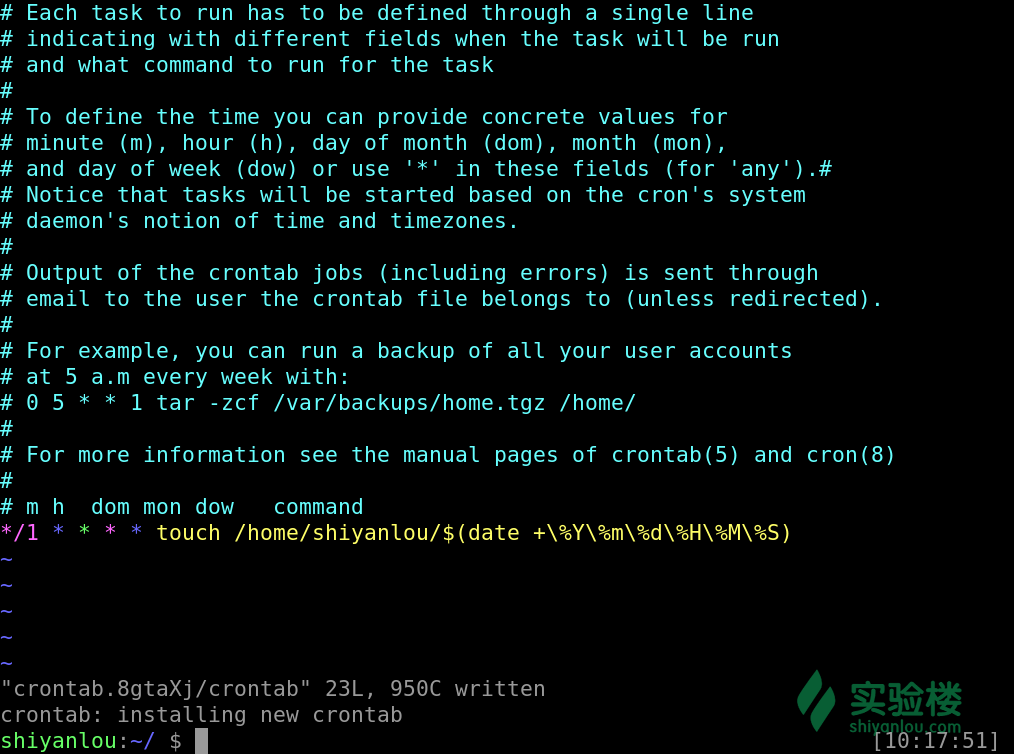
通过这样的一个指令来查看我们添加了哪些任务
crontab -l
但是如果 cron 的守护进程并没有启动,它根本都不会监测到有任务,当然也就不会帮我们执行,我们可以通过以下2种方式来确定我们的 cron 是否成功的在后台启动,默默的帮我们做事,若是没有就得执行上文准备中的第二步了
ps aux | grep cron
# or
pgrep cron
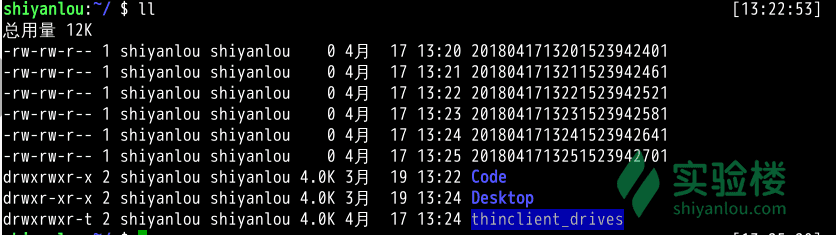
我们通过这样一个命令可以查看到执行任务命令之后在日志中的信息反馈
sudo tail -f /var/log/syslog
从图中我们可以看到分别在13点28、29、30分的01秒为我们在 shiyanlou 用户的家目录下创建了文件
结束 crontab
当我们并不需要这个任务的时候我们可以使用这么一个命令去删除任务
crontab -r
通过图中我们可以看出我们删除之后再查看任务列表,系统已经显示该用户并没有任务哦

深入 crontab
每个用户使用 crontab -e 添加计划任务,都会在 ```/var/spool/cron/crontabs`` 中添加一个该用户自己的任务文档,这样目的是为了隔离。
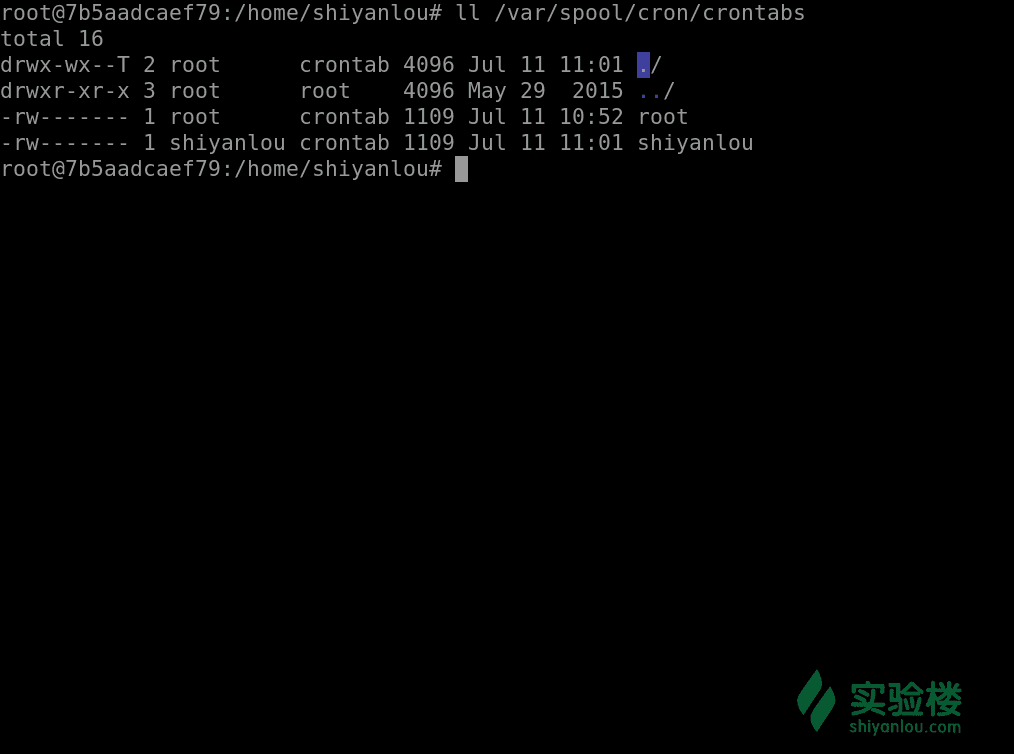
如果是系统级别的定时任务,应该如何处理?只需要以 sudo 权限编辑 /etc/cronta 文件就可以。
cron 服务监测时间最小单位是分钟,所以 cron 会每分钟去读取一次 /etc/crontab 与 /var/spool/cron/crontabs 里面的內容。
在 /etc 目录下,cron 相关的目录有下面几个:
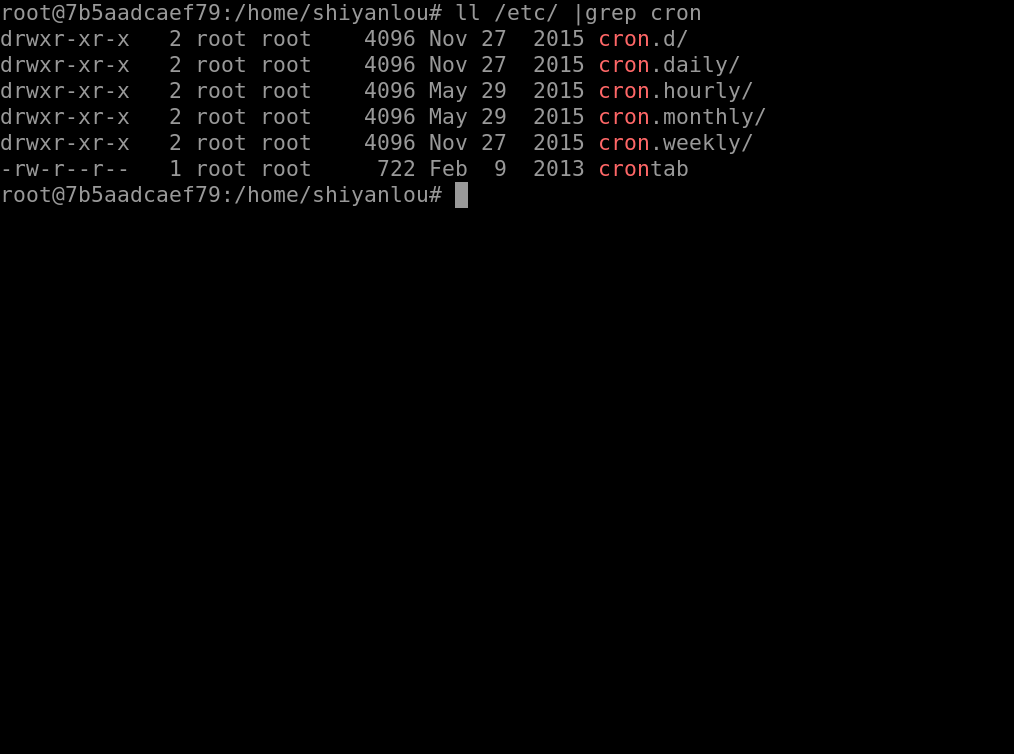
每个目录的作用:(系统默认执行时间可以根据需求进行修改)
/etc/cron.daily,目录下的脚本会每天执行一次,在每天的6点25分时运行;/etc/cron.hourly,目录下的脚本会每个小时执行一次,在每小时的17分钟时运行;/etc/cron.monthly,目录下的脚本会每月执行一次,在每月1号的6点52分时运行;/etc/cron.weekly,目录下的脚本会每周执行一次,在每周第七天的6点47分时运行;
Email TO
MAILTO="email address"
* * * * * echo blaah
cut
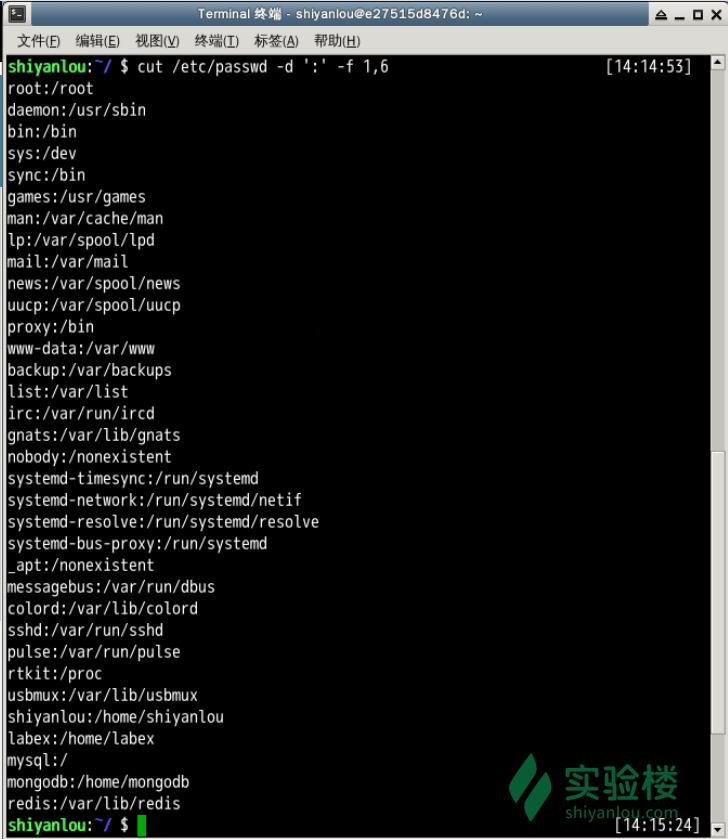
打印/etc/passwd文件中以:为分隔符的第1个字段和第6个字段分别表示用户名和其家目录
| Flag | 说明 |
|---|---|
c |
character, select only these character; cut -c3: 选取第三个字母 |
d |
delimilter, use delimiter instead of TAB as delimiter |
f |
select only these field |
$ cut /etc/passwd -d ':' -f 1,6
打印/etc/passwd文件中每一行的前N个字符:
# 前五个(包含第五个)
cut /etc/passwd -c -5
# 前五个之后的(包含第五个)
cut /etc/passwd -c 5-
# 第五个
cut /etc/passwd -c 5
# 2到5之间的(包含第五个)
cut /etc/passwd -c 2-5
date
used to print out and change system date and time information
date #print 现在系统的时间
date -s "11/20/2003 12:48:00" #设置system time 为 11/20/2003 12:48:00
date +%d%h%y #显示13Jan17
date +%d/%h/%y #显示13-Jan-17
man date #可以显示详细的date format的格式
date "+Date: %m/%d/y%n" #显示01/13/17 %n 是空行线
设置时间格式

dd
dd命令用于转换和复制文件,不过它的复制不同于cp。 Linux 的很重要的一点,一切即文件,在 Linux 上,硬件的设备驱动(如硬盘)和特殊设备文件(如/dev/zero和/dev/random)都像普通文件一样,只是在各自的驱动程序中实现了对应的功能,dd 也可以读取文件或写入这些文件。这样,dd也可以用在备份硬件的引导扇区、获取一定数量的随机数据或者空数据等任务中。dd程序也可以在复制时处理数据,例如转换字节序、或在 ASCII 与 EBCDIC 编码间互换。
dd的命令行语句与其他的 Linux 程序不同,因为它的命令行选项格式为选项=值,而不是更标准的--选项 值或-选项=值 (比如tar -f file)。dd默认从标准输入中读取,并写入到标准输出中,但可以用选项if(input file,输入文件)和of(output file,输出文件)改变。
| 命令 | 说明 |
|---|---|
of |
输出流 |
if |
输入流 |
bs |
block size, 用于指定块大小(缺省单位为 Byte,也可为其指定如’K’,’M’,’G’等单位) |
count |
用于指定块数量 |
| 前面说到dd在拷贝的同时还可以实现数据转换,那下面就举一个简单的例子:将输出的英文字符转换为大写再写入文件: |
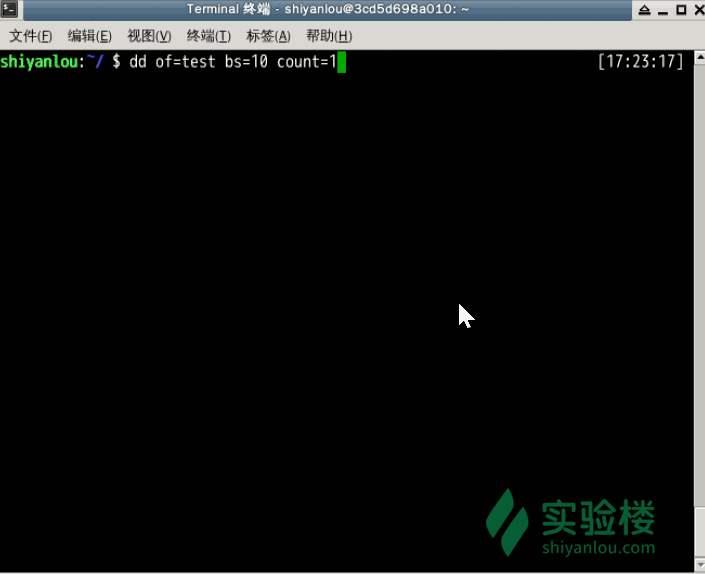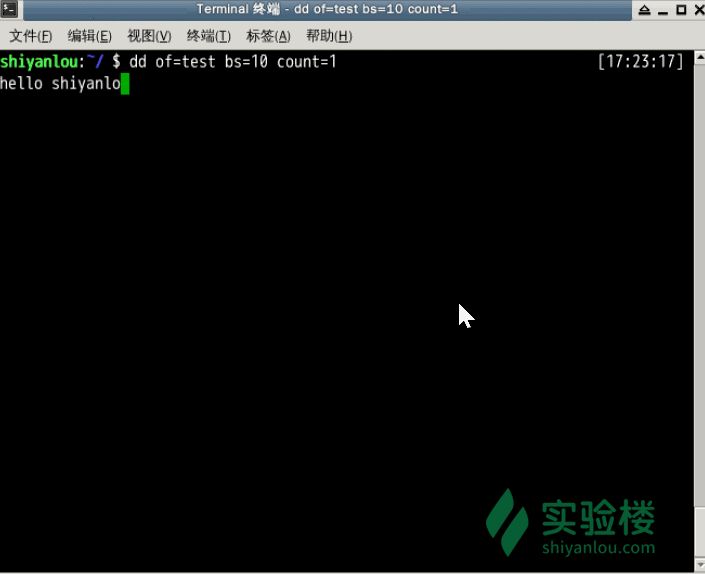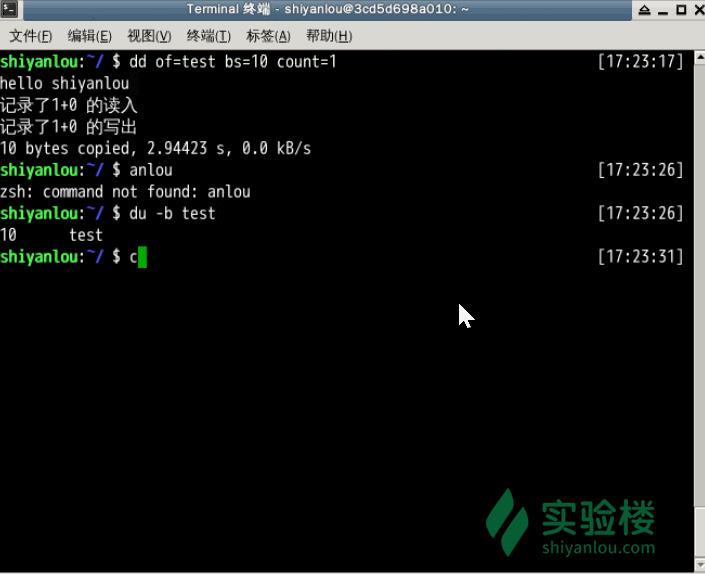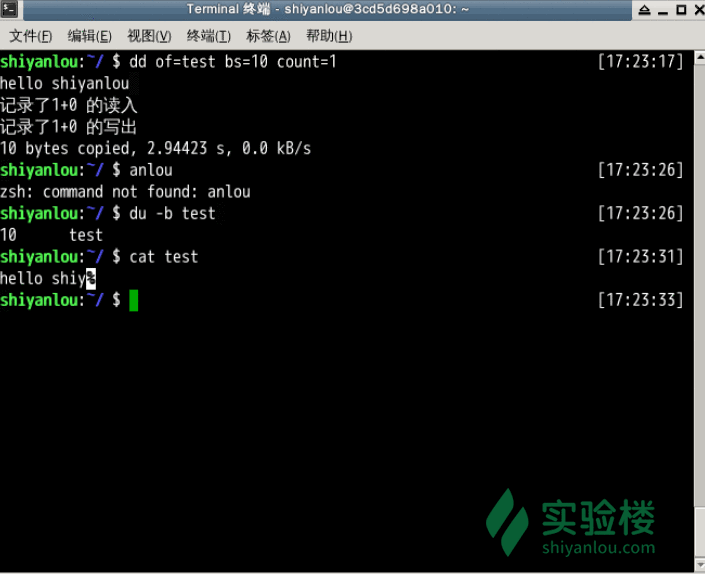
下面两个例子在打完了这个命令后,继续在终端打字,作为你的输入
# 输出到文件
$ dd of=test bs=10 count=1 # 或者 dd if=/dev/stdin of=test bs=10 count=1
# 输出到test 文件, 总共有10 bytes
# 输出到标准输出
$ dd if=/dev/stdin of=/dev/stdout bs=10 count=1
指定只读取总共 10 个字节的数据,当我输入了“hello shiyanlou”之后加上空格回车总共 16 个字节(一个英文字符占一个字节)内容,显然超过了设定大小。使用du和cat命令看到的写入完成文件实际内容确实只有 10 个字节(那个黑底百分号表示这里没有换行符),而其他的多余输入将被截取并保留在标准输入。
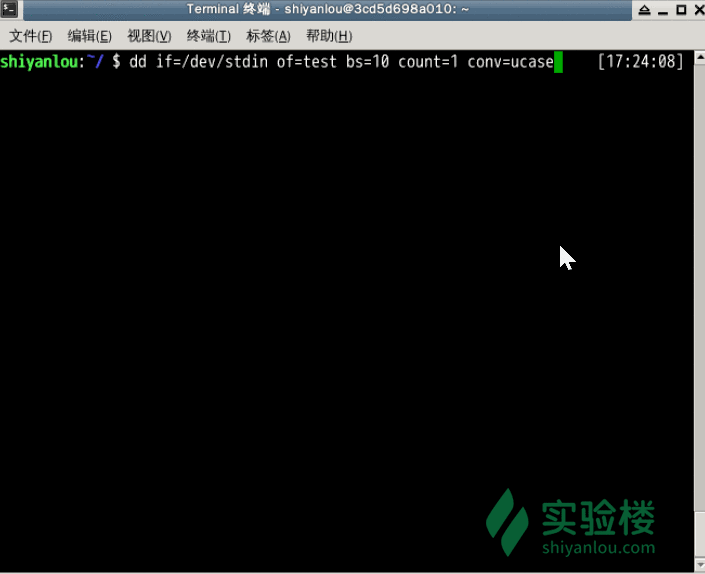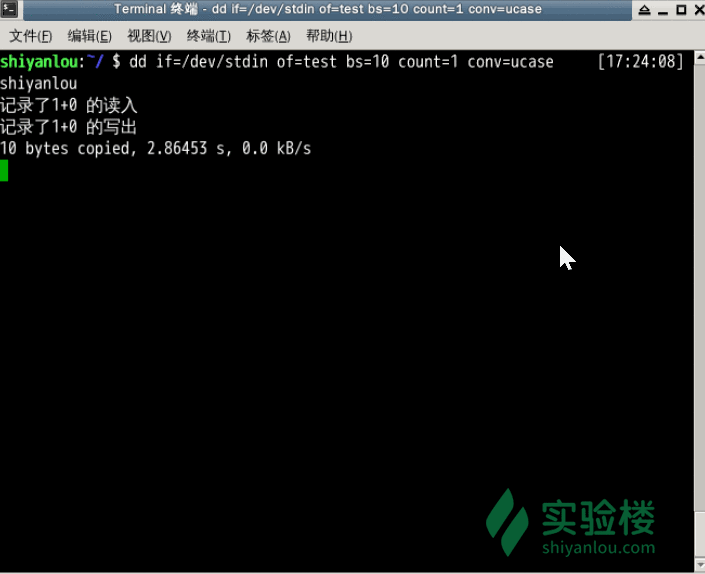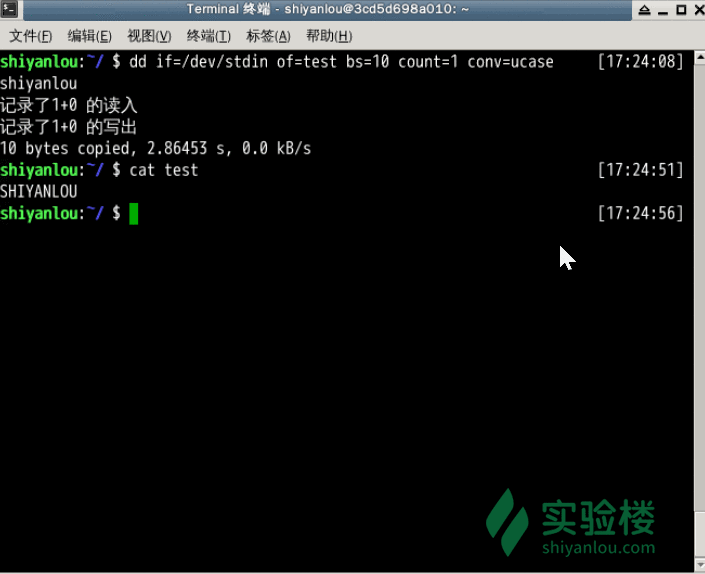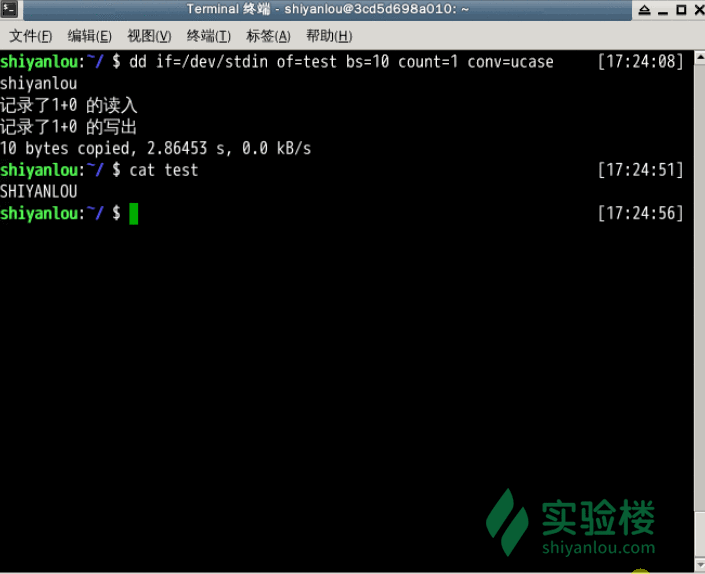
前面说到dd在拷贝的同时还可以实现数据转换,那下面就举一个简单的例子:将输出的英文字符转换 -> 大写再写入文件:
dd if=/dev/stdin of=test bs=10 count=1 conv=ucase
使用 dd 命令创建虚拟镜像文件
从/dev/zero设备创建一个容量为 256M 的空文件:
dd if=/dev/zero of=virtual.img bs=1M count=256
du -h virtual.img
使用 mkfs 命令格式化磁盘(我们这里是自己创建的虚拟磁盘镜像)
你可以在命令行输入 sudo mkfs 然后按下Tab键,你可以看到很多个以 mkfs 为前缀的命令,这些不同的后缀其实就是表示着不同的文件系统,可以用 mkfs 格式化成的文件系统。 我们可以简单的使用下面的命令来将我们的虚拟磁盘镜像格式化为ext4文件系统:
sudo mkfs.ext4 virtual.img
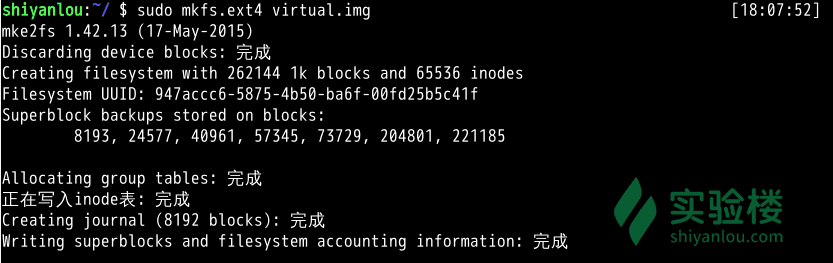
可以看到实际 mkfs.ext4 是使用 mke2fs 来完成格式化工作的。mke2fs 的参数很多,不过我们也不会经常格式化磁盘来玩,所以就掌握这基本用法吧,等你有特殊需求时,再查看 man 文档解决。
更多关于文件系统的知识,请查看wiki: 文件系统 ext3, ext4
如果你想知道 Linux 支持哪些文件系统你可以输入ls -l /lib/modules/$(uname -r)/kernel/fs(我们的环境中无法查看)查看。
使用 mount 命令挂载磁盘到目录树
用户在 Linux/UNIX 的机器上打开一个文件以前,包含该文件的文件系统必须先进行挂载的动作,此时用户要对该文件系统执行 mount 的指令以进行挂载。该指令通常是使用在 USB 或其他可移除存储设备上,而根目录则需要始终保持挂载的状态。又因为 Linux/UNIX 文件系统可以对应一个文件而不一定要是硬件设备,所以可以挂载一个包含文件系统的文件到目录树。
Linux/UNIX 命令行的 mount 指令是告诉操作系统,对应的文件系统已经准备好,可以使用了,而该文件系统会对应到一个特定的点(称为挂载点)。挂载好的文件、目录、设备以及特殊文件即可提供用户使用。
我们先来使用mount来查看下主机已经挂载的文件系统
sudo mount
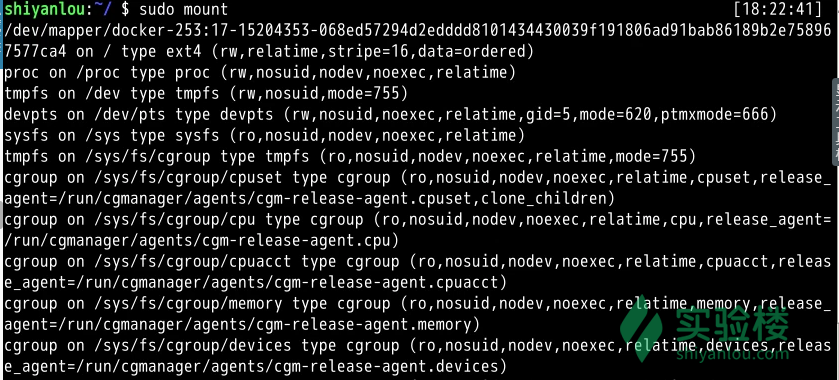
输出的结果中每一行表示一个设备或虚拟设备,每一行最前面是设备名,然后是 on 后面是挂载点,type 后面表示文件系统类型,再后面是挂载选项(比如可以在挂载时设定以只读方式挂载等等)。
那么我们如何挂载真正的磁盘到目录树呢,mount命令的一般格式如下:
mount [options] [source] [directory]
一些常用操作:
mount [-o [操作选项]] [-t 文件系统类型] [-w|--rw|--ro] [文件系统源] [挂载点]
现在直接来挂载我们创建的虚拟磁盘镜像到/mnt目录:
mount -o loop -t ext4 virtual.img /mnt
# 也可以省略挂载类型,很多时候 mount 会自动识别
# 以只读方式挂载
mount -o loop --ro virtual.img /mnt
# 或者mount -o loop,ro virtual.img /mnt
使用 umount 命令卸载已挂载磁盘
# 命令格式 sudo umount 已挂载设备名或者挂载点,如:
sudo umount /mnt
Directory Permission
chmod u-w dir #remove user write permission for directory
#cd 进dir, touch f.txt 显示permission denied
chmod u-r dir #remove read access from user
#cd dir 显示 permission denied
chmod u-x dir #remove execute access from user
#cd dir 或者 ls dir/ 都显示permission denied
dkpg
dpkg 是 Debian 软件包管理器的基础, dpkg 与 RPM 十分相似,同样被用于安装、卸载和供给和 .deb 软件包相关的信息。
dpkg 本身是一个底层的工具。上层的工具,像是 APT,被用于从远程获取软件包以及处理复杂的软件包关系。”dpkg”是”Debian Package”的简写。
我们经常可以在网络上见到以deb形式打包的软件包,就需要使用dpkg命令来安装。 dpkg常用参数介绍:
| 参数 | 说明 |
|---|---|
-i |
安装指定deb包 |
-R |
后面加上目录名,用于安装该目录下的所有deb安装包 |
-r |
remove,移除某个已安装的软件包 |
-I |
显示deb包文件的信息 |
-s |
显示已安装软件的信息 |
-S |
搜索已安装的软件包 |
-L |
显示已安装软件包的目录信息 |
我们先使用apt-get加上-d参数只下载不安装,下载emacs编辑器的deb包:
$ sudo apt-get update
$ sudo apt-get -d install -y emacs
下载完成后,我们可以查看/var/cache/apt/archives/目录下的内容,如下图:

然后我们将第一个deb拷贝到 /home/shiyanlou 目录下,并使用dpkg安装
$ cp /var/cache/apt/archives/emacs24_24.5+1-6ubuntu1.1_amd64.deb ~
# 安装之前参看deb包的信息
$ sudo dpkg -I emacs24_24.5+1-6ubuntu1.1_amd64.deb
# 使用dpkg安装
$ sudo dpkg -i emacs24_24.5+1-6ubuntu1.1_amd64.deb

这个包还额外依赖了一些软件包,这意味着,如果主机目前没有这些被依赖的软件包,直接使用dpkg安装可能会存在一些问题,因为dpkg并不能为你解决依赖关系。
我们将如何解决这个错误呢?这就要用到apt-get了,使用它的-f参数了,修复依赖关系的安装
$ sudo apt-get update
$ sudo apt-get -f install -y
运行安装的软件
eamcs24
查看已安装软件包的安装目录
$ sudo dpkg -L emacs24

du, df, free
du(estimate file space usage)命令与df(report file system disk space usage)
View Resources
df : 查看磁盘容量,
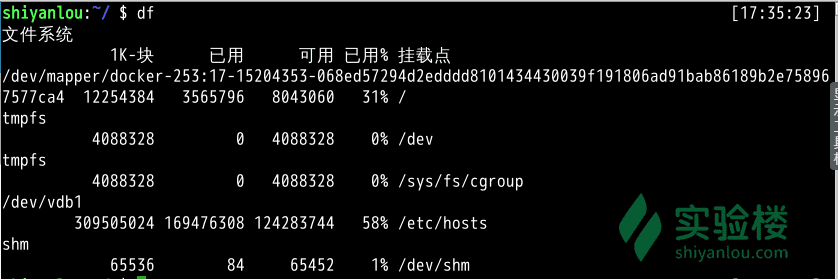
但在实际的物理主机上会更像这样:

物理主机上的 /dev/sda2 是对应着主机硬盘的分区,后面的数字表示分区号,数字前面的字母 a 表示第几块硬盘(也可能是可移动磁盘),你如果主机上有多块硬盘则可能还会出现 /dev/sdb,/dev/sdc 这些磁盘设备都会在 /dev 目录下以文件的存在形式。
接着你还会看到”1k-块”这个陌生的东西,它表示以磁盘块大小的方式显示容量,后面为相应的以块大小表示的已用和可用容量,在你了解 Linux 的文件系统之前这个就先不管吧,我们以一种你应该看得懂的方式展示:
df -h: human reable 显示
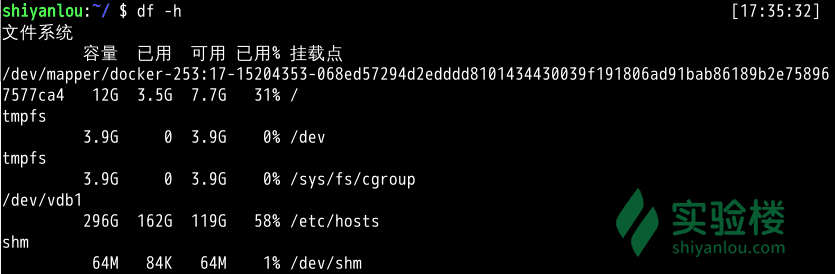
使用 du 命令查看目录的容量
| Flag | 说明 |
|---|---|
-a |
同--all 显示目录中所有文件的大小 |
-d |
参数指定查看目录的深度 |
-h |
同 --human-readable 以K,M,G为单位,提高信息的可读性 |
-s |
#同 --summarize 仅显示总计,只列出最后加总的值 |
# 默认同样以 块 的大小展示
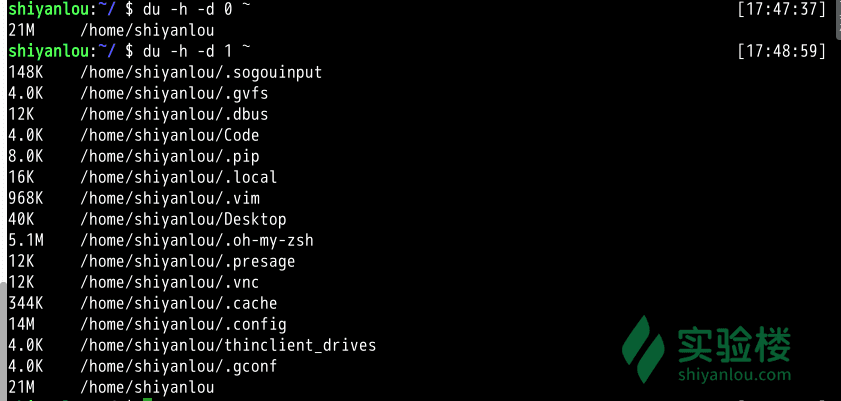
du
# 加上`-h`参数,以更易读的方式展示
du -h
# 只查看1级目录的信息
du -h -d 0 ~
# 查看2级
du -h -d 1 ~
常用参数
du -a #同```--all``` 显示目录中所有文件的大小
du -s #同--summarize 仅显示总计,只列出最后加总的值。
df #the amount of disk space being used by your file system
df -h #the human readable output, 显示多少G, M, k
du #estimate and display the disk space used by files in details
du -h #human readable format
du -sh #-s summary 只给你现在所在directory 文件所占的大小
sudo du -sh #用sudo 原因是因为可能有的file permission denied 需要用sudo
du -sh /etc/ #show summary used space by etc folder
free #display the total amount free and used physical and swap memory in the system as well as buffer in the kernel
free -b #-b btye, -k KB, -m MB, -G GB, -T TB
echo
| 命令 | 解释 |
-n |
打印完后不换行 |
used for bash scripting to print
echo hello world # 在terminal 打印出hello world
echo "hello world" #与上面一样, better use "" for echo
myvar="Mark" #myvar= 不能有空格, assign variable
echo $myvar #print variable
x=10
echo "the value of x is $x" #print the value of x is 10
echo -e 'some \text' #-e use escape, \t -> tab, print: some ext
printf
echo 与 printf 区别
First sentence of entry for echo in the bash man page (emphasis mine):
Output the args, separated by spaces, followed by a newline.
First sentence of the man page entry for printf:
Write the formatted arguments to the standard output under the control of the format.
printf only prints what appears in the format; it does not append an implied newline.
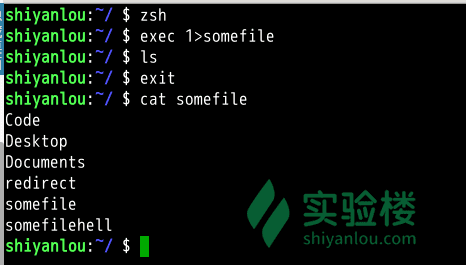
exec
exec命令的作用是使用指定的命令替换当前的 Shell,即使用一个进程替换当前进程,或者指定新的重定向, replace current process image with a new process image
# 先开启一个子 Shell
$ zsh
# 使用exec替换当前进程的重定向,将标准输出重定向到一个文件
$ exec 1>somefile
# 后面你执行的命令的输出都将被重定向到文件中,直到你退出当前子shell,或取消exec的重定向(后面将告诉你怎么做)
$ ls
$ exit
$ cat somefile
file
file 命令查看文件的类型
file /bin/ls
file file.txt
find
find 应该是这几个命令中最强大的了,它不但可以通过文件类型、文件名进行查找而且可以根据文件的属性(如文件的时间戳,文件的权限等)进行搜索
这条命令表示去 /etc/ 目录下面 ,搜索名字叫做 interfaces 的文件或者目录。这是 find 命令最常见的格式,千万记住 find 的第一个参数是要搜索的地方:
sudo find /etc/ -name interfaces
注意 find 命令的路径是作为第一个参数的, 基本命令格式为
find [path] [option] [action]。
与时间相关的命令参数:
| 命令 | 说明 |
|---|---|
-atime |
最后访问时间 |
-ctime |
最后修改文件内容的时间 |
-mtime |
最后修改文件属性的时间 |
下面以 -mtime 参数举例:
-mtime n:n 为数字,表示为在 n 天之前的“一天之内”修改过的文件-mtime +n:列出在 n 天之前(不包含 n 天本身)被修改过的文件-mtime -n:列出在 n 天之内(包含 n 天本身)被修改过的文件-newer file:file 为一个已存在的文件,列出比 file 还要新的文件名
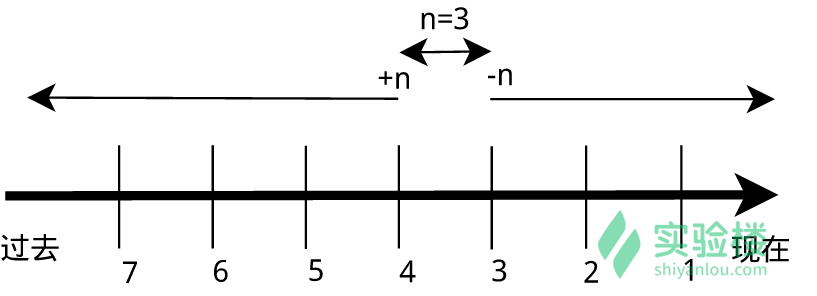
#列出 home 目录中,当天(24 小时之内)有改动的文件:
find ~ -mtime 0
#列出用户家目录下比 Code 文件夹新的文件:
find ~ -newer /home/shiyanlou/Code
find location -name file_name #syntax
find /home/ -name test.sh #-name search by name, return directory
find /home/dir1 -name test.* #search in /home/dir1 folder by name, any file start with test. 可以是.txt, .sh
find /home/dir1 -name *.txt #search any file extension is txt
find / -name dmesg #search in the root directory, 也许有permission error 因为有些directory 不允许access
sudo find / -name dmesg
find /home -mtime -1 #look at the file created 1 days before, 也可以用加号,+1, + 2
gedit
gedit is the default text editor
touch shell.sh
gedit shell.sh #打开shell.sh 文件进行编辑
grep
| 参数 | 说明 |
|---|---|
-E |
POSIX扩展正则表达式,ERE |
-G |
POSIX基本正则表达式,BRE |
-P |
Perl正则表达式,PCRE |
Regular Expression
选择
| 竖直分隔符表示选择,例如 boy|girl可以匹配”boy”或者”girl”
数量限定
+表示前面的字符必须出现至少一次(1次或多次),例如,goo+gle,可以匹配”gooogle”,”goooogle”等;?表示前面的字符最多出现一次(0次或1次),例如,colou?r,可以匹配”color”或者”colour”;*星号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次),例如,0*42可以匹配42、042、0042、00042等。
范围和优先级
()圆括号可以用来定义模式字符串的范围和优先级,这可以简单的理解为是否将括号内的模式串作为一个整体。例如,gr(a|e)y等价于 gray|grey,(这里体现了优先级,竖直分隔符用于选择a或者e而不是gra和ey),(grand)?father匹配father和grandfather(这里体现了范围,?将圆括号内容作为一个整体匹配)。
语法(部分) 正则表达式有多种不同的风格,下面列举一些常用的作为 PCRE 子集的适用于perl和python编程语言及grep或egrep的正则表达式匹配规则:(由于markdown表格解析的问题,下面的竖直分隔符用全角字符代替,实际使用时请换回半角字符)
PCRE(Perl Compatible Regular Expressions中文含义:perl语言兼容正则表达式)是一个用 C 语言编写的正则表达式函数库,由菲利普.海泽(Philip Hazel)编写。PCRE是一个轻量级的函数库,比Boost 之类的正则表达式库小得多。PCRE 十分易用,同时功能也很强大,性能超过了 POSIX 正则表达式库和一些经典的正则表达式库。
| 字符 | 描述 |
|---|---|
\ |
将下一个字符标记为一个特殊字符、或一个原义字符。例如,“n”匹配字符“n”。\n匹配一个换行符。序列\\匹配\而\(则匹配(。 |
^ |
匹配输入字符串的开始位置。 |
$ |
匹配输入字符串的结束位置。 |
{n} |
n是一个非负整数。匹配确定的n次。例如,o{2}不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
{n,} |
n是一个非负整数。至少匹配n次。例如,o{2,}不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。o{1,}等价于o+。o{0,}则等价于o*。 |
{n,m} |
m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,o{1,3}将匹配“fooooood”中的前三个o。o{0,1}等价于o?。请注意在逗号和两个数之间不能有空格。 |
* |
匹配前面的子表达式零次或多次。例如,zo*能匹配z、zo以及zoo。*等价于{0,}。 |
+ |
匹配前面的子表达式一次或多次。例如,zo+能匹配zo以及zoo,但不能匹配z。+等价于{1,}。 |
? |
匹配前面的子表达式零次或一次。例如,do(es)?可以匹配“do”或“does”中的“do”。?等价于{0,1}。 |
? |
当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,o+?将匹配单个“o”,而o+将匹配所有“o”。 |
. |
匹配除\n之外的任何单个字符。要匹配包括\n在内的任何字符,请使用像(.|\n)的模式。 |
(pattern) |
匹配pattern并获取这一匹配的子字符串。该子字符串用于向后引用。要匹配圆括号字符,请使用\(或\)。 |
x|y |
匹配x或y。例如,z|food能匹配“z”或“food”。(z|f)ood则匹配“zood”或“food”。 |
[xyz] |
字符集合(character class)。匹配所包含的任意一个字符。例如,[abc]可以匹配“plain”中的“a”。其中特殊字符仅有反斜线\保持特殊含义,用于转义字符。其它特殊字符如星号、加号、各种括号等均作为普通字符。脱字符^如果出现在首位则表示负值字符集合;如果出现在字符串中间就仅作为普通字符。连字符 - 如果出现在字符串中间表示字符范围描述;如果出现在首位则仅作为普通字符。 |
[^xyz] |
排除型(negate)字符集合。匹配未列出的任意字符。例如,[^abc]可以匹配“plain”中的“plin”。 |
[a-z] |
字符范围。匹配指定范围内的任意字符。例如,[a-z]可以匹配“a”到“z”范围内的任意小写字母字符。 |
[^a-z] |
排除型的字符范围。匹配任何不在指定范围内的任意字符。例如,[^a-z]可以匹配任何不在“a”到“z”范围内的任意字符。 |
\1\2 |
使用上一个pattern, 比如 grep '\([0-9]\)\1' 匹配 11, 22, 33, 44, 55, 66, 77, 88, 99 |
优先级 优先级为从上到下从左到右,依次降低:
| 运算符 | 说明 |
|---|---|
\ |
转义符 |
(), (?:), (?=), [] |
括号和中括号 |
*、+、?、{n}、{n,}、{n,m} |
限定符 |
^、$、\任何元字符 |
定位点和序列 |
| |
选择 |
| Flag | 说明 |
|---|---|
-A n |
n为正整数,表示after的意思,除了列出匹配行之外,还列出后面的n行 |
-B n |
n为正整数,表示before的意思,除了列出匹配行之外,还列出前面的n行 |
-b |
将二进制文件作为文本来进行匹配 |
-c |
统计以模式匹配的数目 |
--color=auto |
将输出中的匹配项设置为自动颜色显示 |
--exclude=GLOB |
skip files whose base name matches GLOB (using wildcard matching). can use *, ?, and [...] as wildcards |
--exclude-from=FILE |
skip files whose matches any FILE can use GLOB |
--exclude-dir=DIR |
Exclude directories matching the pattern DIR from recursive searches |
-E or --extended-regexp |
Interpret Pattern as an extended regular expression |
-I |
忽略binary file , 等于binary-files=without-match option |
-i |
ignore case sensitive 忽略大小写 |
-o or --only-matching |
print only the matched(non-empty) parts of matching line, with each such parts on a separate matching line, 比如file 中有apple, grep -o 'p ', 会把两个单独的p 打印在两行 |
-n |
print the line number,显示匹配文本所在行的行号 |
-v |
Invert sense of matching, only select non-matching line 反选,输出不匹配行的内容 |
-r |
recursively find all files under each directory recursively 递归匹配查找 |
-w or --word-regex |
Select only these lines containing matches that forms whole word grep -w 'the' 不会match there |
| 特殊符号 | 说明 |
|---|---|
\b |
word boundary, e.g. \bthe\b 只需找the 这个词, there 匹配 |
[:alnum:] |
代表英文大小写字母及数字,亦即0-9, A-Z, a-z |
[:alpha:] |
代表任何英文大小写字母,亦即 A-Z, a-z |
[:blank:] |
代表空白键与 [Tab] 按键两者 |
[:cntrl:] |
代表键盘上面的控制按键,亦即包括 CR, LF, Tab, Del.. 等等 |
[:digit:] |
代表数字而已,亦即 0-9 |
[:graph:] |
除了空白字节 (空白键与 [Tab] 按键) 外的其他所有按键 |
[:lower:] |
代表小写字母,亦即 a-z |
[:print:] |
代表任何可以被列印出来的字符 |
[:punct:] |
代表标点符号 (punctuation symbol),亦即:" ' ? ! ; : # $... |
[:upper:] |
代表大写字母,亦即 A-Z |
[:space:] |
任何会产生空白的字符,包括空白键, [Tab], CR 等等 |
[:xdigit:] |
代表 16 进位的数字类型,因此包括: 0-9, A-F, a-f 的数字与字节 |
?注意:之所以要使用特殊符号,是因为上面的[a-z]不是在所有情况下都管用,这还与主机当前的语系有关,即设置在LANG环境变量的值,zh_CN.UTF-8的话[a-z],即为所有小写字母,其它语系可能是大小写交替的如,”a A b B…z Z”,[a-z]中就可能包含大写字母。所以在使用[a-z]时请确保当前语系的影响,使用[:lower:]则不会有这个问题。
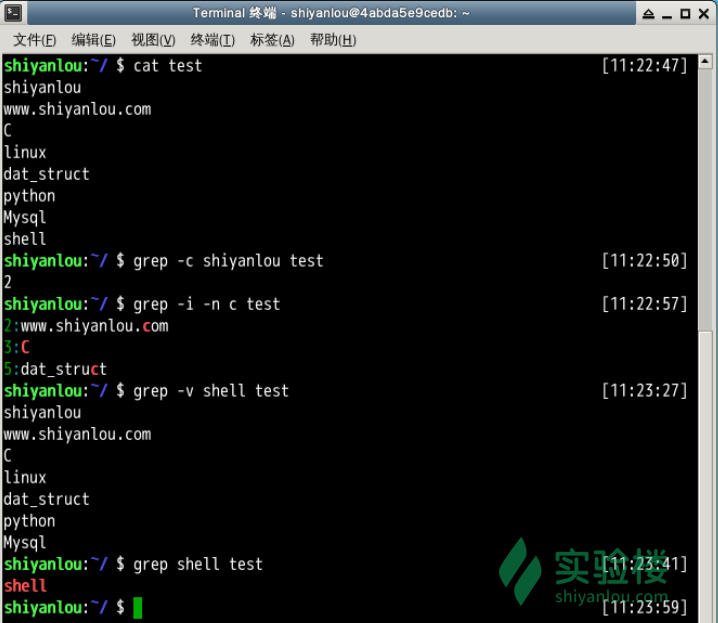
还是先体验一下,我们搜索/home/shiyanlou目录下所有包含”shiyanlou”的文本文件,并显示出现在文本中的行号:
grep -rnI "shiyanlou" ~
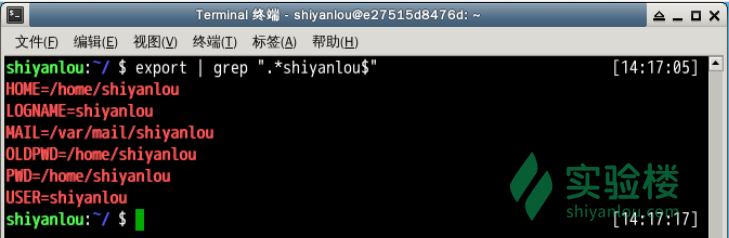
查看环境变量中以”yanlou”结尾的字符串, 其中$就表示一行的末尾。
$ export | grep ".*yanlou$"
regular expression
regular expression 详见Linux 基础regular expression
查找/etc/group文件中以”shiyanlou”为开头的行
grep '^shiyanlou' /etc/group
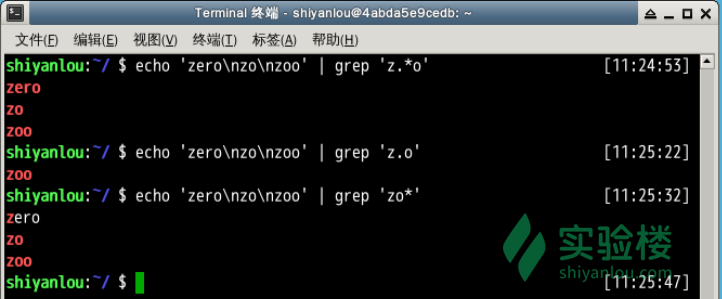
数量
# 将匹配以'z'开头以'o'结尾的所有字符串
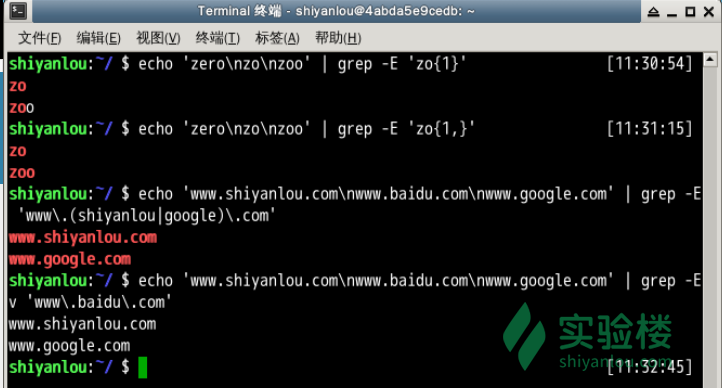
$ echo 'zero\nzo\nzoo' | grep 'z.*o'
# 注意:其中\n为换行符
# 将匹配以'z'开头以'o'结尾,中间包含一个任意字符的字符串
$ echo 'zero\nzo\nzoo' | grep 'z.o'
# 将匹配以'z'开头,以任意多个'o'结尾的字符串
$ echo 'zero\nzo\nzoo' | grep 'zo*'
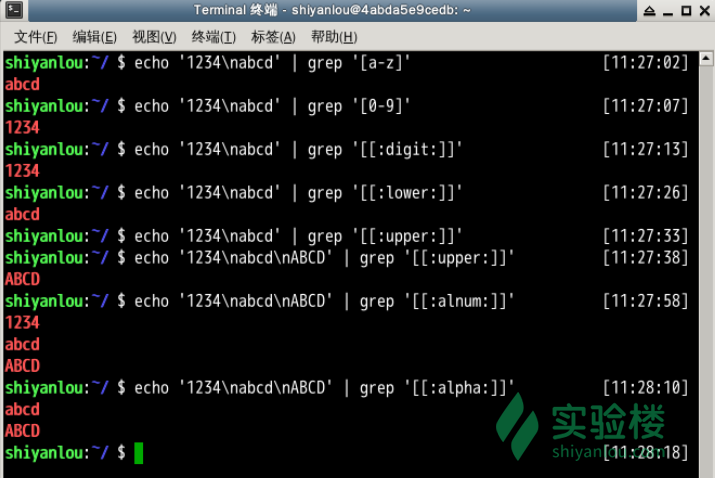
选择
# grep默认是区分大小写的,这里将匹配所有的小写字母
$ echo '1234\nabcd' | grep '[a-z]'
# 将匹配所有的数字
$ echo '1234\nabcd' | grep '[0-9]'
# 将匹配所有的数字
$ echo '1234\nabcd' | grep '[[:digit:]]'
# 将匹配所有的小写字母
$ echo '1234\nabcd' | grep '[[:lower:]]'
# 将匹配所有的大写字母
$ echo '1234\nabcd' | grep '[[:upper:]]'
# 将匹配所有的字母和数字,包括0-9,a-z,A-Z
$ echo '1234\nabcd' | grep '[[:alnum:]]'
# 将匹配所有的字母
$ echo '1234\nabcd' | grep '[[:alpha:]]'
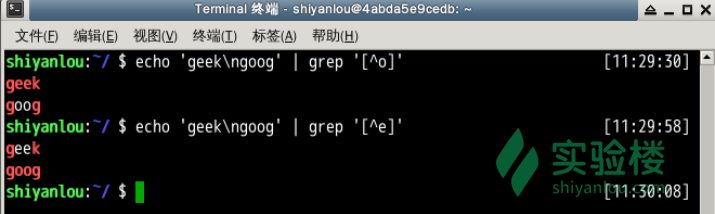
排除字符
$ $ echo 'geek\ngood' | grep '[^o]'
注意:当^放到中括号内为排除字符,否则表示行首。
使用扩展正则表达式,ERE
要通过grep使用扩展正则表达式需要加上-E参数,或使用egrep。
数量
# 只匹配"zo"
$ echo 'zero\nzo\nzoo' | grep -E 'zo{1}'
# 匹配以"zo"开头的所有单词
$ echo 'zero\nzo\nzoo' | grep -E 'zo{1,}'
注意:推荐掌握{n,m}即可,+,?,*,这几个不太直观,且容易弄混淆。
选择
# 匹配"www.shiyanlou.com"和"www.google.com"
$ echo 'www.shiyanlou.com\nwww.baidu.com\nwww.google.com' | grep -E 'www\.(shiyanlou|google)\.com'
# 或者匹配不包含"baidu"的内容
$ echo 'www.shiyanlou.com\nwww.baidu.com\nwww.google.com' | grep -Ev 'www\.baidu\.com'
注意:因为.号有特殊含义,所以需要转义。
#
man tar > file.txt
grep "options" file.txt #keyword I want to search and file name,
#grep 是case sensitive的, 上面的search options 不会search Options,
grep -i "options" file.txt #make search not case sensitive, 也会search Options
grep -n "options" file.txt #在file 中search并显示file.txt的options, 并显示在哪行
grep -n "Some options" file.txt #在file 中search并显示Some options
#used in multiple files
grep -n "Some options" f1.txt, f2.txt f3.txt f4.txt #在多个file 中search并显示Some options
grep -n "Some options" * #在现在folder中的所有file search并显示Some options 的行
grep -nv "Some options" f1.txt #显示f1.txt 不包含Some options的行
grep -help #显示有的flag, options 用grep command
groups, groupadd, groupdel
group show which group is currently user connected to
groups #show which group is currently user connected to
cat /etc/group #show all the group in your system, group <-> user connected to
sudo groupadd Java #add newgroup in system
sudo groupdel Java #delete existing group
#-a add user to group, -d remove user from group
sudo gpasswd -a mark Java # add mark to the Java group
sudo gpasswd -d mark Java #remove user from Group
head / tail
| 命令 | 解释 |
|---|---|
-cN |
打印前N |
-nN or -n+N |
从第N行或者倒数第N行开始打印 |
Head: output the first part of the filetail: output the last part of the file,-f不停的读取某个文件并显示tail -n11ortail -11从 倒数第11 行开始,比如有100行,从90行开始一直到100行tail -n+11从第11行开始,知道结尾, 比如有100行,从11行开始一直到100行
head log.txt #show first 10 line of file
tail log.txt #show last 10 line of file
head -n3 log.txt #show first 3 lines of file
head -3 log.txt #跟上面一样
tail -n3 log.txt #show last 3 lines of file
tail -3 log.txt #跟上面一样
tail -f log.txt #output last 10 lines of file. watch the file, whenever file change, will show last 10 lines of code
ctrl + C #exit
head log.txt kern.log #先print 10 lines of log.txt 再print 10 lines of kern.log
head -3 log.txt kern.log #先print 3 lines of log.txt 再print 3 lines of kern.log
help
zsh 中没有help, 进入bash 中,输入
bash
help ls
help ls 显示error

因为 help 命令是用于显示 shell 内建命令的简要帮助信息, ls是外部命令。帮助信息中显示有该命令的简要说明以及一些参数的使用以及说明,不然就会得到你刚刚得到的结果。
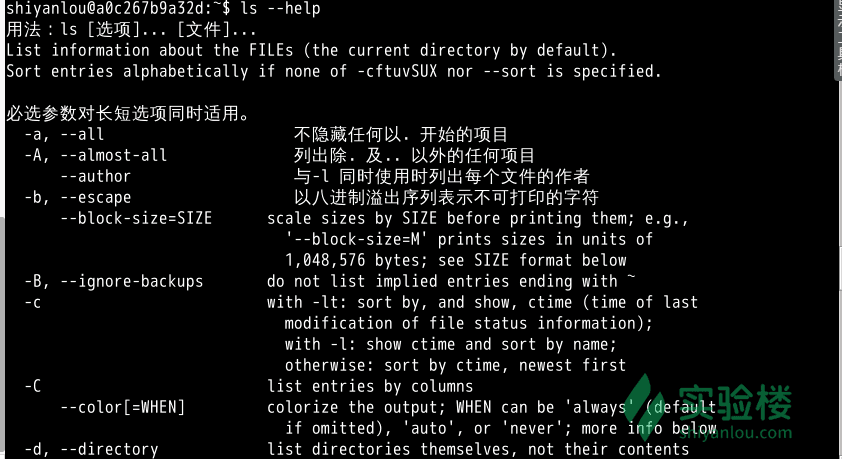
那如果是外部命令怎么办,不能就这么抛弃它呀。其实外部命令基本上都有一个参数--help
ls --help
history
看看最近都执行了什么命令,实际为读取${SHELL}_history文件,如我们环境中的~/.zsh_history文件),
history
info
要是你觉得man显示的信息都还不够,满足不了你的需求,那试试 info 命令.
# 安装 info
sudo apt-get update
sudo apt-get install info
# 查看 ls 命令的 info
info ls
得到的信息是不是比 man 还要多了,info 来自自由软件基金会的 GNU 项目,是 GNU 的超文本帮助系统,能够更完整的显示出 GNU 信息。所以得到的信息当然更多
man 和 info 就像两个集合,它们有一个交集部分,但与 man 相比,info 工具可显示更完整的 GNU 工具信息。若 man 页包含的某个工具的概要信息在 info 中也有介绍,那么 man 页中会有“请参考 info 页更详细内容”的字样。
ifconfig
ifconfig: interface configuration: used to view and change network interface configuration on your system
ifconfig #show you some output
ifconfig eth0 #only show eth0 interface
#up, down to disable internet connection
sudo ifconfig eth0 down #internet connection will be down
sudo ifconfig eth0 up #enable internet
ethO: wired internet cable
WLAN0: wireless internet connection
0: is the first internet interface. 如果有multiple internet interface, 显示eth1, or WLAN2
l0: loop back interface. An interface that system use to communcate to excel
join
学过数据库的用户对这个应该不会陌生,这个命令就是用于将两个文件中包含相同内容的那一行合并在一起。使用方式: join [option]... file1 file2
常用的选项有:
| 选项 | 说明 |
|---|---|
-a NUM |
<span style=”background-color:#FFFF00>默认是inner join</span>, 没有pair上不显示, -a 1 left join, -a 2 right join |
-t 'delimiter' |
指定分隔符,默认为空格 |
-i |
忽略大小写的差异 |
-1 NUM |
第一个file 哪个column 作为join的key, 默认对比第一个字段, |
-2 NUM |
第二个file 哪个column 作为join的key,默认对比第一个字段 |
nocheck-order |
默认情况下会检查file 是不是按照key的顺序sorted,如果不是会report, 这个会不check if sorted |
$ cd /home/shiyanlou
# 创建两个文件
$ echo '1 hello' > file1
$ echo '1 shiyanlou' > file2
$ join file1 file2
# print 1 hello shiyanlou
# 将/etc/passwd与/etc/shadow两个文件合并,指定以':'作为分隔符
$ sudo join -t':' /etc/passwd /etc/shadow
# 将/etc/passwd与/etc/group两个文件合并,指定以':'作为分隔符, 分别比对第4和第3个字段
$ sudo join -t':' -1 4 /etc/passwd -2 3 /etc/group
kill / ps
#kill的使用格式如下
kill -signal %jobnumber
#signal从1-64个信号值可以选择,可以这样查看
kill -l
关于job number, 详见 Linux 基础, 工作管理
其中常用的有这些信号值
| 信号值 | 作用 |
|---|---|
-1 |
重新读取参数运行,类似与restart |
-2 |
如同 ctrl+c 的操作退出 |
-9 |
强制终止该任务 |
-15 |
正常的方式终止该任务 |
注意: 若是在使用kill + 信号值然后直接加 pid,你将会对 pid 对应的进程进行操作
若是在使用kill+信号值然后 %jobnumber,这时所操作的对象是 job,这个数字就是就当前 bash 中后台的运行的 job 的 ID
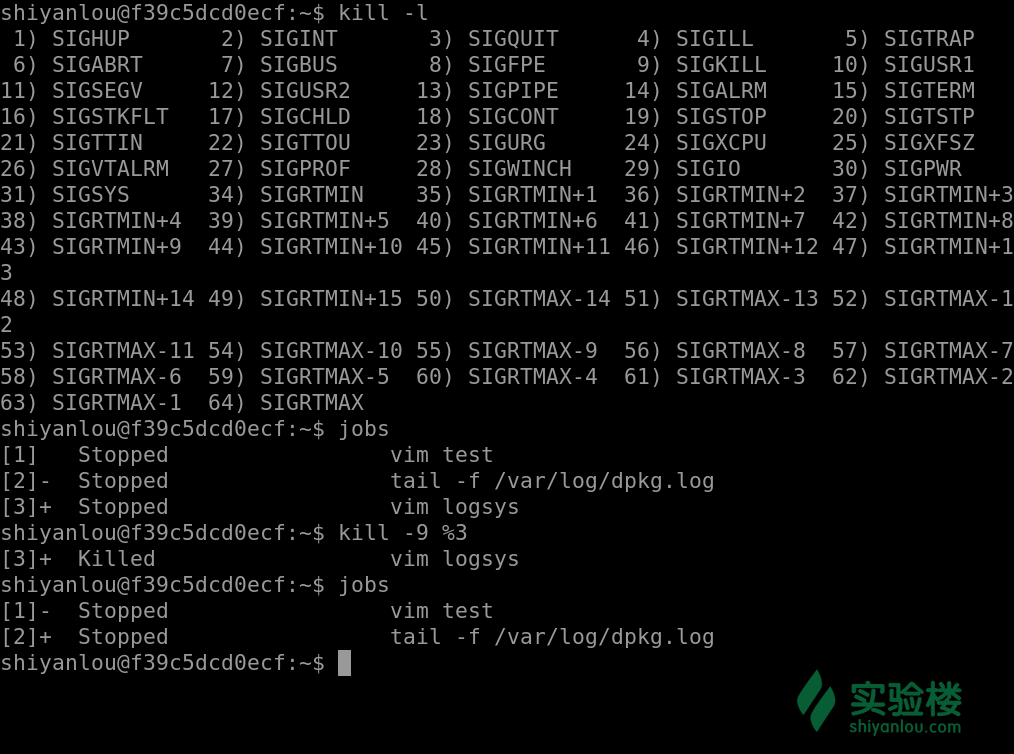
#首先我们使用图形界面打开了 gedit、gvim,用 ps 可以查看到
ps aux
#使用9这个信号强制结束 gedit 进程
kill -9 1608
#我们再查找这个进程的时候就找不到了
ps aux | grep gedit


kill process
kill -flags pid # syntax
pidof unity-control-center #lookup pid by name
kill 3286 # kill pid = 3286 process
kill -KILL 3294 #force to kill process
kill -9 3294 # force to kill process (flag -9)
ps -ux #find pid; give a long list of running process (current user)
ps -aux #find pid; give a long list of all running process (all users)
ps -U Becks #give all process under User Becks
ps -C gnome-terminal #give all process related to program gnome-terminal, 可能连着多个instances
locate
通过“ /var/lib/mlocate/mlocate.db ”数据库查找,不过这个数据库也不是实时更新的,系统会使用定时任务每天自动执行 updatedb 命令更新一次,所以有时候你刚添加的文件,它可能会找不到,需要手动执行一次 updatedb 命令(在我们的环境中必须先执行一次该命令)。它可以用来查找指定目录下的不同文件类型,如查找 /etc 下所有以 sh 开头的文件:(注意,它不只是在 /etc 目录下查找,还会自动递归子目录进行查找)
sudo apt-get update
sudo apt-get install locate
locate /etc/sh
查找 /usr/share/ 下所有 jpg 文件:
$ locate /usr/share/\*.jpg #注意要添加 * 号前面的反斜杠转义,否则会无法找到。
如果想只统计数目可以加上 -c 参数,-i 参数可以忽略大小写进行查找,whereis 的 -b、-m、-s 同样可以使用。
less
read file and search pattern in the file, 比如用cat print整个文件,当文件很大,当print完成,不能显示文件开头,用less,可以看
less big.txt #only show the starting point of the file, 然后用键盘的↓,enter show one more row below at one time
#用键盘的↑,enter show one row above at one time
#键盘的space show page by page below
#键盘的shift+B show page by page above
#键盘的shift+G to the end of file
#键盘先1 + G or g (without shift) to go to the begining of the file
#想找文件从上到下,比如找book, type /book + enter, 找next, type n
#想找文件从下到上,比如找book, type ?book + enter, 找上一个,type n
#想退出less command, press q
more file
#Enter 向下滚动一行
#Space 向下滚动一屏
#h 帮助
#q 退出
man
ls
得到的内容比用 help更多更详细,而且 man 没有内建与外部命令的区分,因为 man 工具是显示系统手册页中的内容,也就是一本电子版的字典,这些内容大多数都是对命令的解释信息,还有一些相关的描述。通过查看系统文档中的 man 也可以得到程序的更多相关信息和 Linux 的更多特性。
是不是好用许多,当然也不代表 help 就没有存在的必要,当你非常紧急只是忘记该用哪个参数的时候,help 这种显示简单扼要的信息就特别实用,若是不太紧急的时候就可以用 man 这种详细描述的查询方式
在尝试上面这个命令时我们会发现最左上角显示“ LS (1)”,在这里,“ LS ”表示手册名称,而“(1)”表示该手册位于第一章节。这个章节又是什么?在 man 手册中一共有这么几个章节
| 章节数 | 说明 |
|---|---|
| 1 | Standard commands (标准命令) |
| 2 | System calls (系统调用) |
| 3 | Library functions (库函数) |
| 4 | Special devices (设备说明) |
| 5 | File formats (文件格式) |
| 6 | Games and toys (游戏和娱乐) |
| 7 | Miscellaneous (杂项) |
| 8 | Administrative Commands (管理员命令) |
| 9 | 其他(Linux特定的), 用来存放内核例行程序的文档 |
打开手册之后我们可以通过 pgup 与 pgdn 或者上下键来上下翻看,可以按 q 退出当前页面
mkdir
mkdir image #生成image directory
mkdir image/pic #生成pic directory inside image directory
mkdir names/mark #当names 不在当前文件夹下,显示error, No such file or directory
mkdir -p names/mark (mkdir --parents names/mark ) #-p means -- parents, 比如当names 不存在的时候,这样可以建立, 如果不加p, 会报错
#-p is the same as --parents
mkdir -p names/{john,tom,bob} #creat several directory inside current directory, 建立三个文件夹,john, tom,bob
# {john,tom,bob} 不能有空格,否则建立的文件夹是 {john,
mv / rename
mv: rename, move
mv options source dest
mv f1.txt f2.txt #rename f1.txt 成f2.txt
mv f1.txt dir1/ #把f1.txt 移动到dir1
#如果dir1 中有f1.txt, move 会overwrite 原有的file 内容
mv f1.txt f2.txt dir1/ #move 多个文件到dir1
mv -i f1.txt dir1 #move f1.txt 到dir1 folder中, 如果要overwrite 会问
mv -i f1.txt dir1/ #与上面一样的
mv dir1 dir2 #把dir1 移动到dir2 中, content 也会move, 不用-R
#dir1就现在文件夹下不存在了,dir1 在dir2中
#tricky,如果当dir3 不存在
mv dir2 dir3 #dir2中的内容移动到dir3中,所以dir3中只含有dir1,dir2也消失了
#如果dir3 也存在,那么dir3 中有dir2, dir2中有dir1
mv -v file3.txt dir3 #V, verb, 显示具体怎么移动的
如果想实现批量重命名, mv 就不行了, 不过它要用 perl 正则表达式来作为参数
touch file{1..5}.txt #批量创建5个文件
# 批量将这 5 个后缀为 .txt 的文本文件重命名为以 .c 为后缀的文件:
rename 's/\.txt/\.c/' *.txt
# 批量将这 5 个文件,文件名和后缀改为大写:
rename 'y/a-z/A-Z/' *.c
nano
nano is a small and friendly text editor, besides it has interactive search, replace, go to line, and indentation
nano file.txt #open txt editor, file open but not show has been created, 因为还没有save
#press ctrl + o, -> means write out
#press ctrl + x -> quit the file
#press ctrl + k -> cut
#press ctrl + u -> paste
nao abc.cpp #会有color, code highlighting, 不光是cpp, 也可以是Java,c
netstat
netstat is to display network connection, routing tables and a number of network interfaces, and view network protocal states
netstat -a #show all connections which are available on your system whether it is TCP or UDP or UNIX connection,
#上面aslo display the status if it connected, listening, or established
# | means after | whatever second command is used will implement the output of the first command
netstat -a | less #use the output of netstat to display with less command
netstat -at | less #-t means just show the TCP connection
netstat -au | less #-u means just show the UDP connection
netstat -l | less #-l means just show listenning state
netstat -lt | less #-lt means just show listening and TCP connection
netstat -lu | less #-lu means just show listenning and UDP connection
netstat -s | less #-s show the statistic of connection, you can see which type of connection it is and properties of the packet what is happening
netstat -st | less #-st show the statistic of TCP connection
netstat -su | less #-su show the statistic of UDP connection
netstat -pt | less #-pt show PID of TCP connection
netstat -px | less #-px show PID of UNIX connection
netstat -n | less #-n show the numeric port of connection
netstat -c # show the connection continuously, it refresh by itself
netstat -ie #-ie extended interface, it is the same output as ifconfig
netstat -an | grep ":80" #-an show numeric port of all conection and search which port has :80
nl
for numbering ines
-b: 指定添加行号的方式,主要有两种:-b a:表示无论是否为空行,同样列出行号(“cat -n”就是这种方式)-b t:只列出非空行的编号并列出(默认为这种方式)
-n: 设置行号的样式,主要有三种:-n ln:在行号字段最左端显示-n rn:在行号字段最右边显示,且不加 0-n rz:在行号字段最右边显示,且加 0-w: 行号字段占用的位数(默认为 6 位)
nl -b a file # 是否空行都列出行号
paste
paste这个命令与join 命令类似,它是在不对比数据的情况下,简单地将多个文件合并一起,以Tab隔开, if no file specified or put - instead of file name, paste reads from standard input and gives output as it is until a interrupt command [Ctrl-c] is given
使用方式: paste [option] file...
常用的选项有:
| 选项 | 说明 |
-d or --delimiters=LIST |
指定合并的分隔符,默认为Tab |
-s or --serial |
不合并到一行,每个文件为一行, paste one file at a time instead of in parallel |
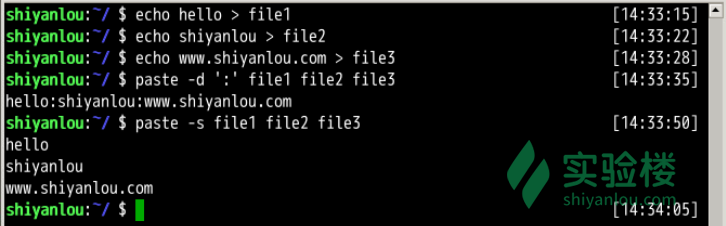
$ echo hello > file1
$ echo shiyanlou > file2
$ echo www.shiyanlou.com > file3
$ paste -d ':' file1 file2 file3
$ paste -s file1 file2 file3
比如有file name, age, profession
Name:
Sally
Jim
John
Age:
22
18
30
Profession:
Student
Worker
Singer
下面将第一个file 用 | 隔开, 第二个File 用 , 隔开
paste -d'|,' name, age, profession
#output
#Sally|22,Student
#Jim|18,Worker
#John|30,Singer
-s 文件会横过来
paste -s name, age, profession
#output
#Sally Jim John
#22 18 30
#Student Worker Singer
Combination of -d and -s:
paste -d","-s name, age, profession
#output
#Sally,Jim,John
#22,18,30
#Student,Worker,Singer
如果file.txt 为
Jim Student
Sally worker
John Student
默认分隔符为\tab
paste -s file.txt
#Jim Student Sally worker John Student
- - Merge a file by pasting the data into 2 columns
cat file.txt | paste -d ';' - - #--mean read from stdin, then read from stdin, you can stack as many of them
#or
paste -d ';' - - < file.txt
#print
#Jim Student;Sally worker
#John Student
10 Use of paste command: 不错的例子
PS / nice /renice
| 内容 | 解释 |
|---|---|
F |
进程的标志(process flags),当 flags 值为 1 则表示此子程序只是 fork 但没有执行 exec,为 4 表示此程序使用超级管理员 root 权限 |
USER |
进程的拥有用户 |
PID |
进程的 ID |
PPID |
其父进程的 PID, TPGID栏写着-1的都是没有控制终端的进程,也就是守护进程 |
SID |
session 的 ID |
TPGID |
前台进程组的 ID |
%CPU |
进程占用的 CPU 百分比 |
%MEM |
占用内存的百分比 |
NI |
进程的 NICE 值 |
VSZ |
进程使用虚拟内存大小 |
RSS |
驻留内存中页的大小 |
TTY |
终端 ID |
S or STAT |
进程状态 |
WCHAN |
正在等待的进程资源 |
START |
启动进程的时间 |
TIME |
进程消耗CPU的时间 |
COMMAND |
命令的名称和参数 |
STAT表示进程的状态,而进程的状态有很多,如下表所示
| 状态 | 解释 |
|---|---|
R |
Running.运行中 |
S |
Interruptible Sleep.等待调用 |
D |
Uninterruptible Sleep.不可中断睡眠 |
T |
Stoped.暂停或者跟踪状态 |
X |
Dead.即将被撤销 |
Z |
Zombie.僵尸进程 |
W |
Paging.内存交换 |
N |
优先级低的进程 |
< |
优先级高的进程 |
s |
进程的领导者 |
L |
锁定状态 |
l |
多线程状态 |
+ |
前台进程 |
其中的 D 是不能被中断睡眠的状态,处在这种状态的进程不接受外来的任何 signal,所以无法使用
kill命令杀掉处于D状态的进程,无论是kill,kill -9还是kill -15,一般处于这种状态可能是进程 I/O 的时候出问题了。
ps 工具有许多的参数,下面给大家解释部分常用的参数
| Flag | 解释 |
|---|---|
-a |
select all processes except both session leaders |
使用 -l 参数可以显示自己这次登录的 bash 相关的进程信息罗列出来
ps -l
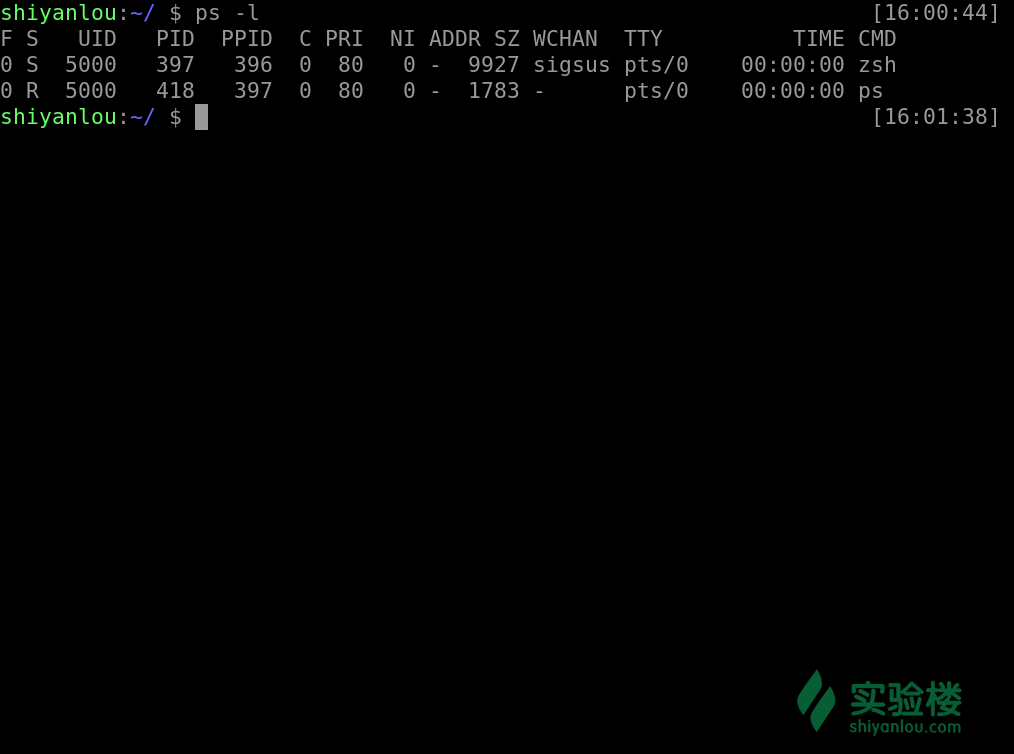
他将会罗列出所有的进程信息
ps aux
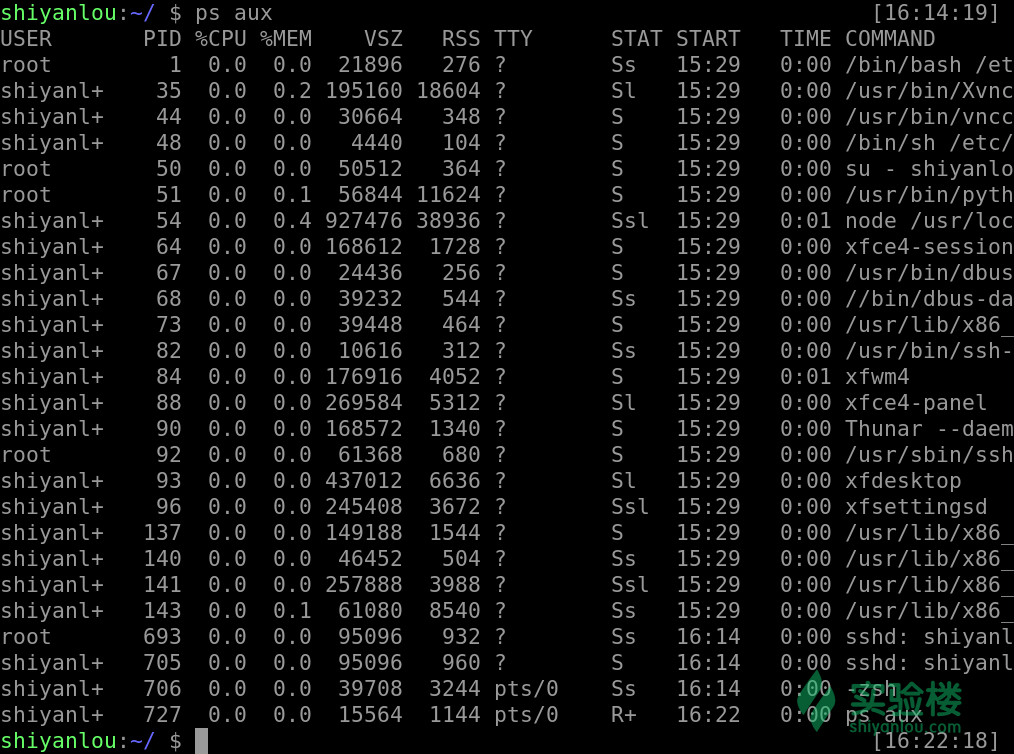
若是查找其中的某个进程的话,我们还可以配合着 grep 和正则表达式一起使用
ps aux | grep zsh
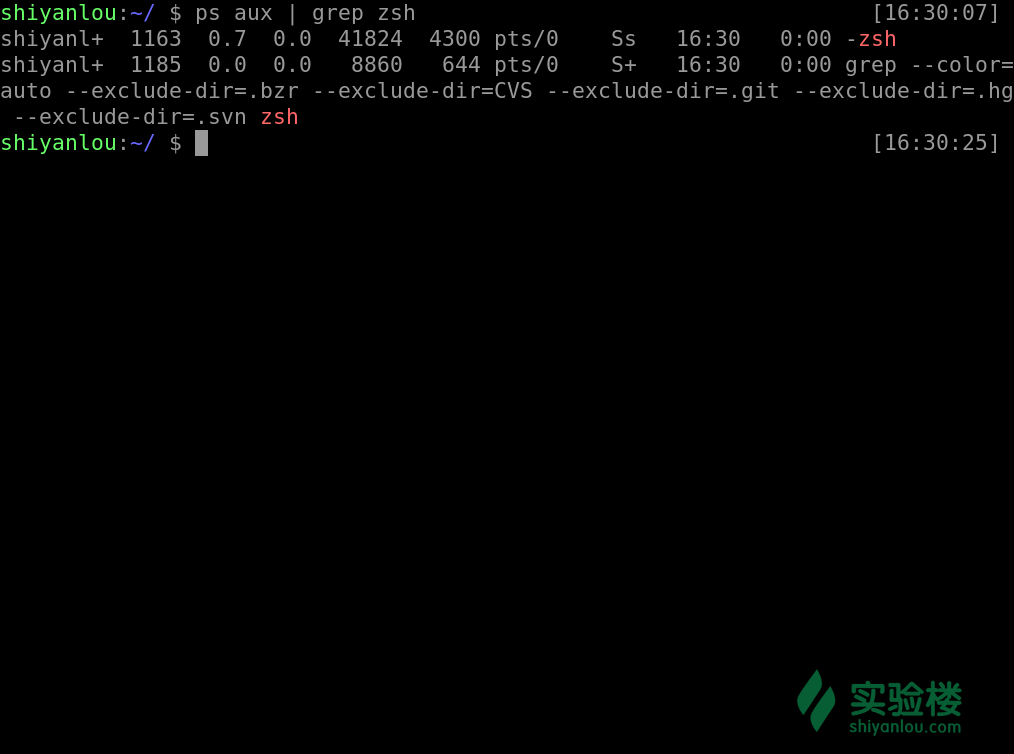
此外我们还可以查看时,将连同部分的进程呈树状显示出来
ps axjf
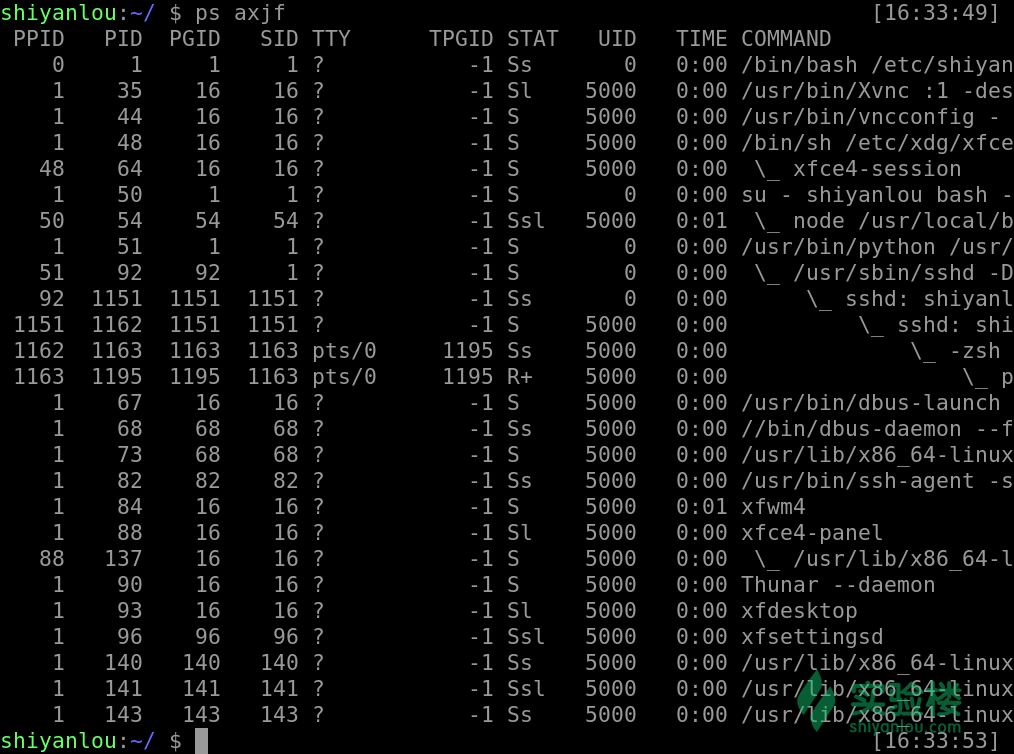
当然如果你觉得使用这样的此时没有把你想要的信息放在一起,我们也可以是用这样的命令,来自定义我们所需要的参数显示
ps -afxo user,ppid,pid,pgid,command
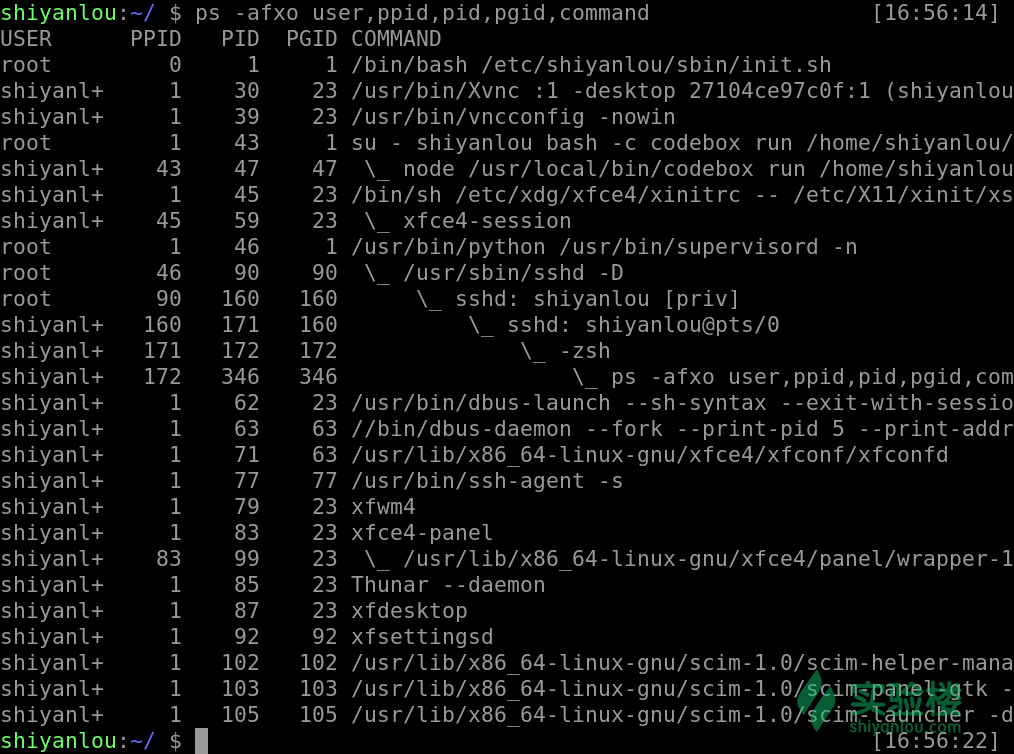
进程的执行顺序
我们在使用 ps 命令的时候可以看到大部分的进程都是处于休眠的状态,如果这些进程都被唤醒,那么该谁最先享受 CPU 的服务,后面的进程又该是一个什么样的顺序呢?进程调度的队列又该如何去排列呢?
当然就是靠该进程的优先级值来判定进程调度的优先级,而优先级的值就是上文所提到的 PR 与 nice 来控制与体现了
而 nice 的值我们是可以通过 nice 命令来修改的,而需要注意的是 nice 值可以调整的范围是 -20 ~ 19,其中 root 有着至高无上的权力,既可以调整自己的进程也可以调整其他用户的程序,并且是所有的值都可以用,而普通用户只可以调制属于自己的进程,并且其使用的范围只能是 0 ~ 19,因为系统为了避免一般用户抢占系统资源而设置的一个限制
#打开一个程序放在后台,或者用图形界面打开
nice -n -5 vim &
#用 ps 查看其优先级
ps -afxo user,ppid,pid,stat,pri,ni,time,command | grep vim
我们还可以用 renice 来修改已经存在的进程的优先级
renice -5 pid
pstree
通过 pstree 可以很直接的看到相同的进程数量,最主要的还是我们可以看到所有进程之间的相关性。
pstree
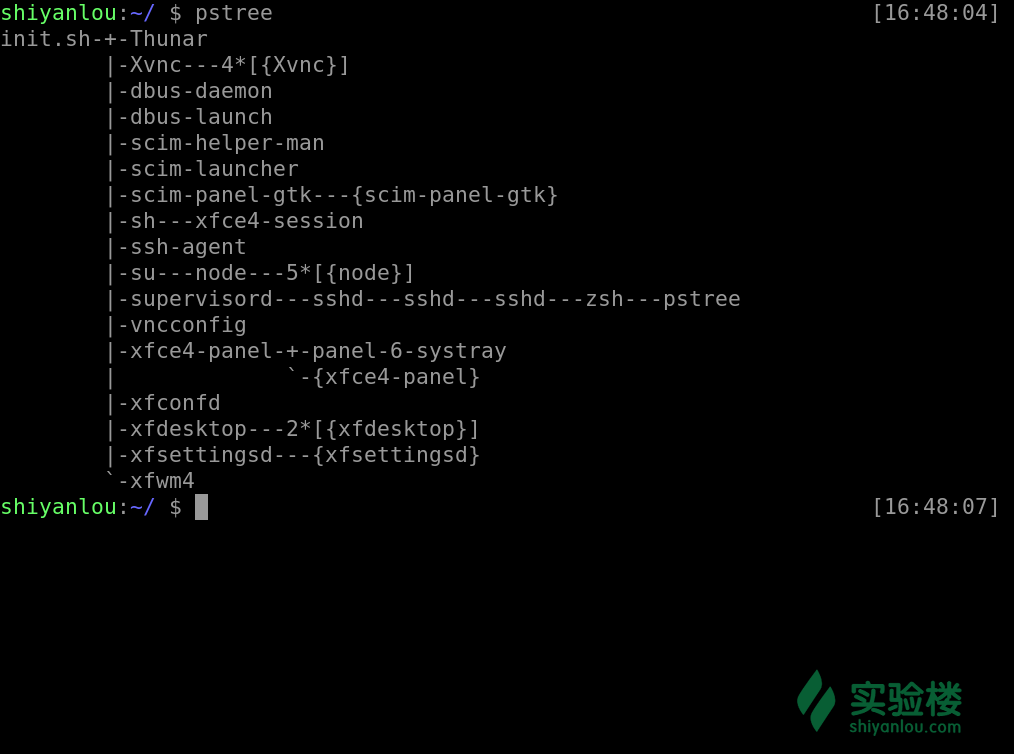
pstree -up
#参数选择:
#-A :各程序树之间以 ASCII 字元來連接;
#-p :同时列出每个 process 的 PID;
#-u :同时列出每个 process 的所屬账户名称。
rm & rmdir
rmdir: remove directory, rm: rmove file and directory
rmdir abc # remove abc的folder
rmdir a/b/c/d/e #只remove 最后e的directory
rmdir -p a/b/c/d/e #remove 所有的directory structure
rmdir -p a/b/c/d/e #remove 所有directory structure,
#如果a/b/c/d/e 每个并不是空的文件夹,会显示error, failed to remove directory a/b: Directory not empty
rm -rv a/b #并显示(verb)remove的进程
rm -rv a #与上面一行作用是一样的,
rm -f file #强制删除文件
rm -i file1 file2 #会询问是否删除
rm -I file1 file2 #如果删除大于3个文件会显示是否删除文件 且只问一次,如果小于3个文件,不会显示
rm * #删除现在文件夹下所有文件
sed
sed工具在 man 手册里面的全名为”sed - stream editor for filtering and transforming text “,意即,用于过滤和转换文本的流编辑器。
在 Linux/UNIX 的世界里敢称为编辑器的工具,大都非等闲之辈,比如前面的”vi/vim(编辑器之神)”,”emacs(神的编辑器)”,”gedit”这些个编辑器。sed与上述的最大不同之处在于它是一个非交互式的编辑器,下面我们就开始介绍sed这个编辑器
| 参数 | 说明 |
-n or --quiet or --slient |
安静模式,只打印受影响的行,默认打印输入数据的全部内容 |
-e script or --expression=script |
add scripts to the command to be executed 用于在脚本中添加多个执行命令一次执行,在命令行中执行多个命令通常不需要加该参数 |
-f filename or --file=filename |
add the contents of script files to the command to be executed指定执行filename文件中的命令 |
-r or --regex-extended |
use extended regular expression 使用扩展正则表达式,默认为标准正则表达式 |
-i[SUFFIX] or --in-place[=SUFFIX] |
edit files in place 将直接修改输入文件内容,而不是打印到标准输出设备 |
sed [参数]... [执行命令] [输入文件]...
# 形如:
$ sed -i 's/sad/happy/' test # 表示将test文件中的"sad"替换为"happy"
sed执行命令格式:
[n1][,n2]command
[n1][~step]command
# 其中一些命令可以在后面加上作用范围,形如:
$ sed -i 's/sad/happy/g' test # g表示全局范围
$ sed -i 's/sad/happy/4' test # 4表示指定行中的第四个匹配字符串
其中n1,n2表示输入内容的行号,它们之间为,逗号则表示从n1到n2行,如果为~波浪号则表示从n1开始以step为步进的所有行;command为执行动作,下面为一些常用动作指令:
| 命令 | 说明 |
s/regexp/pattern |
attempt to match regexp with the pattern space. If successful, replace that portion matched with replacement 行内替换 |
c \text |
replace selected lines with text 整行替换 |
a |
append text 插入到指定行的后面 |
-e |
Append the editing commands specified by the command argument to the list of commands, 把几个command 拆开写(见下面例子) |
i |
insert text 插入到指定行的前面 |
p |
print current pattern 打印指定行,通常与-n参数配合使用 |
d |
delete pattern space 删除指定行 |
打印指定行
# 打印2-5行
$ nl passwd | sed -n '2,5p'
# 打印奇数行
$ nl passwd | sed -n '1~2p'
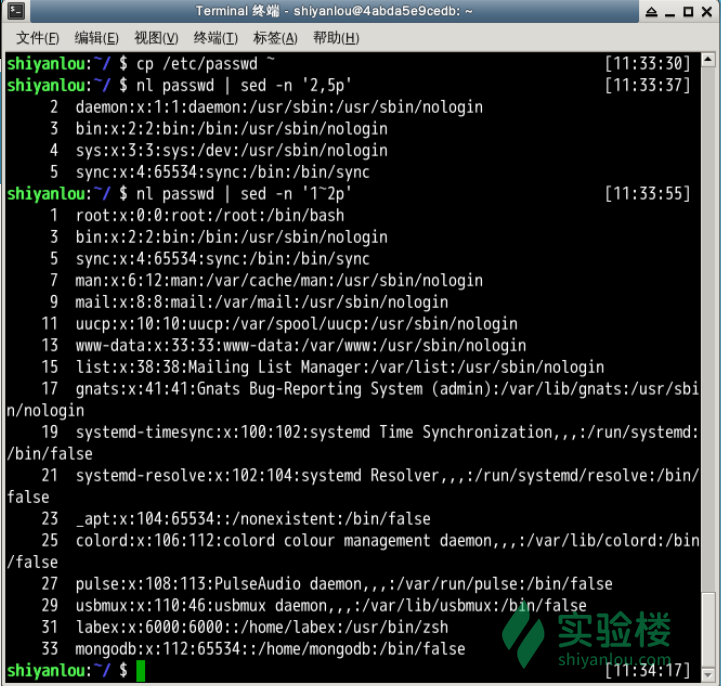
行内替换
# 将输入文本中"shiyanlou" 全局替换为"hehe",并只打印替换的那一行,注意这里不能省略最后的"p"命令
$ sed -n 's/shiyanlou/hehe/gp' passwd
注意: 行内替换可以结合正则表达式使用。
删除某行
$ nl passwd | grep "shiyanlou"
# 删除第30行
$ sed -i '30d' passwd

替换
| 命令 | 说明 |
s |
替换 3s 只替换第三行 3,6s 替换3到6行 sed '/fish/, +3s/This/#/g: 替换fish后(包括fish 行)的连续3行, 一共四行的This 变成 #,如果这四行没有不替换 , sed 's/s/S/1' 替换每一行第一个 sed 's/s/S/2' my.txt 只替换每行第二个match的 sed 's/s/S/3g' my.txt只替换第一行的第3个以后的s: |
g |
替换所有行 |
& |
做被匹配的变量, 在左右加东西, sed 's/my/[&]/g' my.txt 所有的my 会变为 [my], sed 's/my//&123/g' my.txt 所有的my 会变为 my123 |
() |
括号内匹配的可以当变量使用 sed 's/(my) is (good)/\1:\2/g‘ 把my 变成第一个变量, good 做为第二个变量 (\1,\2...), 结果是打印 my:good |
^表示一行的开头。如:/^#/以#开头的匹配。$表示一行的结尾。如:/}$/以}结尾的匹配。\<表示词首。 如:\<abc表示以 abc 为首的詞。\>表示词尾。 如:abc\>表示以abc結尾的詞。.表示任何单个字符。*表示某个字符出现了0次或多次。[ ]字符集合。 如:[abc]表示匹配a或b或c,还有[a-zA-Z]表示匹配所有的26个字符。如果其中有^表示反,如 [^a] 表示非a的字符
E.g.1
比如file 是:
$ cat pets.txt
# This is my my cat
# my cat's name
/g 表示一行上的替换所有的匹配:
sed "s/my/Becks/" pets.txt
# 输出
#This is Becks my cat
# Becks cat's name
sed "s/my/Becks/g" pets.txt
# 输出
#This is Becks Becks cat
# Becks cat's name
上面的sed并没有对文件的内容改变,只是把处理过后的内容输出,如果你要写回文件,你可以使用重定向,如:
sed "s/my/Becks's/g" pets.txt > new_pets.txt
#or
sed -i "s/my/Becks's/g" pets.txt
E.g 2 remove tag
去掉所有的file,比如有file
<b>This</b> is what <span style=text-decoration: underline;>I</span> meant. Understand
$ sed 's/<.*>//g' html.txt #替换<.*> 为空字符
# meant Understand? #会删除tag包含 内所有的内容
# 其中的'[^>]' 指定了除了>的字符重复0次或多次。
$ sed 's/<[^>]*>//g' html.txt
This is what I meant. Understand?
比如有文本
This is my cat, my cat's name is betty
This is my dog, my dog's name is frank
This is my fish, my fish's name is george
This is my goat, my goat's name is adam
E.g 3. 替换指定行
sed "3s/my/your/g" pets.txt #只替换第三行 把my 到 your
sed "3,6s/my/your/g" pets.txt #替换从第三行到第六行所有的my 变成your
E.g 4 多个匹配
如果我们需要一次替换多个模式,可参看下面的示例:(第一个模式把第一行到第三行的my替换成your,第二个则把第3行以后的This替换成了That)
$ sed '1,3s/my/your/g; 3,$s/This/That/g' my.txt
#This is your cat, your cat's name is betty
#This is your dog, your dog's name is frank
#That is your fish, your fish's name is george
#That is my goat, my goat's name is adam
上面的命令等价于:(注:下面使用的是sed的-e命令行参数)
sed -e '1,3s/my/your/g' -e '3,$s/This/That/g' my.txt
我们可以使用&来当做被匹配的变量,然后可以在基本左右加点东西。如下所示:
$ sed 's/my/[&]/g' my.txt
#This is [my] cat, [my] cat's name is betty
#This is [my] dog, [my] dog's name is frank
#This is [my] fish, [my] fish's name is george
#This is [my] goat, [my] goat's name is adam
E.g 5 圆括号匹配
使用圆括号匹配的示例:(圆括号括起来的正则表达式所匹配的字符串会可以当成变量来使用,sed中使用的是\1,\2…)
$ sed 's/This is my \([^,]*\),.*is \(.*\)/\1:\2/g' my.txt
#cat:betty
#dog:frank
#fish:george
#goat:adam
上面这个例子中的正则表达式有点复杂,解开如下(去掉转义字符):
正则为:This is my ([^,]*),.*is (.*)
匹配为:This is my (cat),……….is (betty)
然后:\1就是cat,\2就是betty
N command
把下一行的内容纳入当成缓冲区做匹配,把偶数行纳入奇数行匹配,
file 还是下面形式
This is my cat
my cat's name is betty
This is my dog
my dog's name is frank
This is my fish
my fish's name is george
This is my goat
my goat's name is adam
sed 'N;s/my/your/' pets.txt
#This is your cat
# my cat's name is betty
#This is your dog
# my dog's name is frank
#This is your fish
# my fish's name is george
#This is your goat
# my goat's name is adam
偶数行纳入奇数行,原来file 变成
This is my cat\n my cat's name is betty
This is my dog\n my dog's name is frank
This is my fish\n my fish's name is george
This is my goat\n my goat's name is adam
再比如下面的
$ sed 'N;s/\n/,/' pets.txt
#This is my cat, my cat's name is betty
#This is my dog, my dog's name is frank
#This is my fish, my fish's name is george
#This is my goat, my goat's name is adam
a/i command
- 比如
sed '1 i my pig': 表示第一行前插入my pig - 比如
sed '$ a my pig': 表示最后一行后面插入my pig
现有file
This is my cat, my cat's name is betty
This is my dog, my dog's name is frank
This is my fish, my fish's name is george
This is my goat, my goat's name is adam
# 其中的1i表明,其要在第1行前插入一行(insert)
$ sed "1 i This is my monkey, my monkey's name is wukong" my.txt
#This is my monkey, my monkey's name is wukong
#This is my cat, my cat's name is betty
#This is my dog, my dog's name is frank
#This is my fish, my fish's name is george
#This is my goat, my goat's name is adam
# 其中的$a表明,其要在最后一行后追加一行(append)
$ sed "$ a This is my monkey, my monkey's name is wukong" my.txt
#This is my cat, my cat's name is betty
#This is my dog, my dog's name is frank
#This is my fish, my fish's name is george
#This is my goat, my goat's name is adam
#This is my monkey, my monkey's name is wukong
在每个fish的下一行append 一行 This is my pig
sed "/fish/a This is my pig" del.txt
#This is my cat, my cat's name is betty
#This is my dog, my dog's name is frank
#This is my fish, my fish's name is george
#This is my pig
#This is my goat, my goat's name is adam
在每个my下一行 插入 —-
$ sed "/my/a ----" my.txt
#This is my cat, my cat's name is betty
#----
#This is my dog, my dog's name is frank
#----
#This is my fish, my fish's name is george
#----
#This is my goat, my goat's name is adam
#----
c Command
2 c This is my pig: 把第二行替换为 This is my pig/fish/c This is my pig: 把有fish 的行 替换为 This is my pig
This is my cat, my cat's name is betty
This is my dog, my dog's name is frank
This is my fish, my fish's name is george
This is my goat, my goat's name is adam
$ sed "2 c This is my monkey, my monkey's name is wukong" my.txt
#This is my cat, my cat's name is betty
#This is my monkey, my monkey's name is wukong
#This is my fish, my fish's name is george
#This is my goat, my goat's name is adam
$ sed "/fish/c This is my monkey, my monkey's name is wukong" my.txt
#This is my cat, my cat's name is betty
#This is my dog, my dog's name is frank
#This is my monkey, my monkey's name is wukong
#This is my goat, my goat's name is adam
d Command
删除匹配行
This is my cat, my cat's name is betty
This is my dog, my dog's name is frank
This is my fish, my fish's name is george
This is my goat, my goat's name is adam
#删除含有fish的行
$ sed '/fish/d' my.txt
#This is my cat, my cat's name is betty
#This is my dog, my dog's name is frank
#This is my goat, my goat's name is adam
#删除第二行
$ sed '2d' my.txt
#This is my cat, my cat's name is betty
#This is my fish, my fish's name is george
#This is my goat, my goat's name is adam
#从2行 到结尾 都删除
$ sed '2,$d' my.txt
#This is my cat, my cat's name is betty
p Command
-n只打印符合规定的line. Each line of input is echoed to the standard output
打印命令
# 匹配fish并输出,可以看到fish的那一行被打了两遍,
# 这是因为sed处理时会把处理的信息输出
$ sed '/fish/p' my.txt
#This is my cat, my cat's name is betty
#This is my dog, my dog's name is frank
#This is my fish, my fish's name is george
#This is my fish, my fish's name is george
#This is my goat, my goat's name is adam
# 使用n参数就好了
$ sed -n '/fish/p' my.txt
#This is my fish, my fish's name is george
# 从一个模式到另一个模式
$ sed -n '/dog/,/fish/p' my.txt
#This is my dog, my dog's name is frank
#This is my fish, my fish's name is george
#从第一行打印到匹配fish成功的那一行
$ sed -n '1,/fish/p' my.txt
#This is my cat, my cat's name is betty
#This is my dog, my dog's name is frank
#This is my fish, my fish's name is george
可以使用相对位置, dog 行(包括dog 行) 后面连续三行的替换
# 其中的+3表示后面连续3行
$ sed '/dog/,+3s/^/# /g' pets.txt
#This is my cat
# my cat's name is betty
## This is my dog
## my dog's name is frank
## This is my fish
## my fish's name is george
#This is my goat
# my goat's name is adam
$ sed '/dog/,+3s/This/His/g' pets.txt
This is my cat
# my cat's name is betty
# His is my dog
# my dog's name is frank
# His is my fish
# my fish's name is george
#This is my goat
# my goat's name is adam
命令打包
多个命令可以用分号分开,可以用大括号括起来作为嵌套命令。下面是几个例子:
$ cat pets.txt
This is my cat
my cat's name is betty
This is my dog
my dog's name is frank
This is my fish
my fish's name is george
This is my goat
my goat's name is adam
# 对3行到第6行,执行命令/This/d
$ sed '3,6 {/This/d}' pets.txt
This is my cat
my cat's name is betty
my dog's name is frank
my fish's name is george
This is my goat
my goat's name is adam
# 对3行到第6行,匹配/This/成功后,再匹配/fish/,成功后执行d命令
$ sed '3,6 {/This/{/fish/d}}' pets.txt
This is my cat
my cat's name is betty
This is my dog
my dog's name is frank
my fish's name is george
This is my goat
my goat's name is adam
# 从第一行到最后一行,如果匹配到This,则删除之;如果前面有空格,则去除空格
$ sed '1,${/This/d;s/^ *//g}' pets.txt
my cat's name is betty
my dog's name is frank
my fish's name is george
my goat's name is adam
Hold/Pattern Space
When sed reads a file line by line, the line that has been currently read is inserted into the pattern buffer (pattern space). It is like temporary buffer, the scratchpad where the current information is stored. When you tell sed to print, it prints the pattern buffer.
Hold buffer / hold space is like a long-term storage, such that you can catch something, store it and reuse it later when sed is processing another line.You do not directly process the hold space, instead, you need to copy it or append to the pattern space if you want to do something with it. For example, the print command p prints the pattern space only. Likewise, s operates on the pattern space. Hold Space
| 命令 | 解释 |
g: |
将hold space中的内容拷贝到pattern space中,原来pattern space里的内容清除 |
G: |
将hold space中的内容append到pattern space\n后, |
h: |
将pattern space中的内容拷贝到hold space中,原来的hold space里的内容被清除, 在之前一行的hold 的前面 |
H: |
将pattern space中的内容append到hold space\n后, 这前hold 后面 插入 |
x: |
交换pattern space和hold space的内容, 先读到pattern, 然后同时进行 1. 读的pattern到hold. 2.原始的hold 到 pattern, |
注: 读每行时,先把内容读到pattern, 然后再g, G or H
File
$ cat t.txt
one
two
three
e.g. 1
sed 'x' t.txt
#打印
#
# one
# two
因为
| pattern space | hold space before | pattern space after x | hold space after x |
|---|---|---|---|
| one | one | ||
| two | one | one | two |
| three | two | two | three |
e.g. 2, G 不会把pattern 到 hold, 只会让hold 到pattern
sed 'G' t.txt
#打印
#
# one
# two
# three
sed 'G' t.txt
#打印 三个空行
#
#
#
因为
| pattern space before | hold space before | pattern space after G |
|---|---|---|
| one | `` | one `` |
| two | `` | two `` |
| three | `` | three `` |
E.g. 3
sed 'h' t.txt
#打印
# one
# two
# three
sed 'H' t.txt
#打印
# one
# two
# three
H 操作:
| pattern space | hold space before | hold space after H |
|---|---|---|
| one | `` | `` one |
| two | `` one |
`` one two |
| three | `` one two |
`` one two three |
h 操作:
| pattern space | hold space before | hold space after H |
|---|---|---|
| one | "" |
one |
| two | "" |
two |
| three | "" |
three |
e.g. 4
$ sed 'H;g' t.txt
one
one
two
one
two
three
H 具体见上面操作
g 操作:
| pattern space before | hold space | pattern space after g |
|---|---|---|
| one | `` one |
`` one |
| two | `` one two |
`` one two |
| three | `` one two three |
`` one two three |
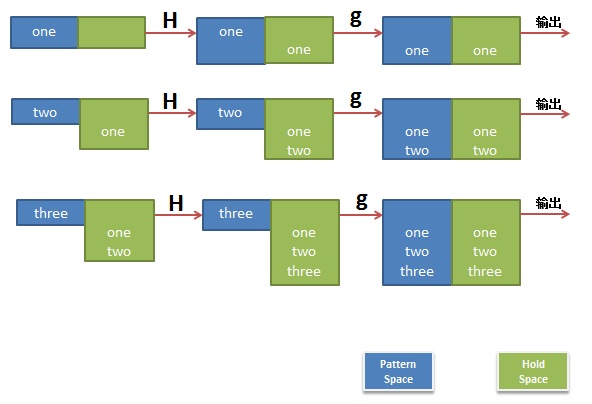
E.g. 5 相当于 tac
sed '1! G;h;\$!d' t.txt
#three
#two
#one
sed -n '1! G;h;$p' t.txt #-n 和 p 只打印最后一行
其中的 ‘1! G;h;\$!d’ 可拆解为三个命令
1! G只有第一行不执行G命令,将hold space中的内容append回到pattern spaceh第一行都执行h命令,将pattern space中的内容拷贝到hold space中\$!d除了最后一行不执行d命令,其它行都执行d命令,删除当前行
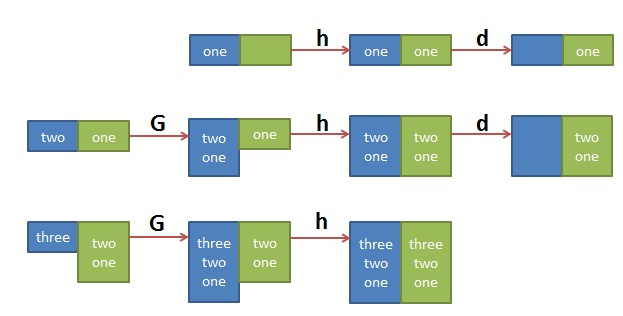
可以拆分上面命令
1! G;h; 操作: 注意这个操作是每行都进行1! G;h 操作 而不是先进行1! G 再进行 h 操作
| pattern space load | pattern space after | hold space before | hold space after | 解释 |
|---|---|---|---|---|
| one | one | "" |
one | 没有 G, 只有h |
| two | two one |
one | two one |
G 先将hold space 带到pattern space, 再复制pattern 到 hold |
| three | three two one |
two one |
three two one |
ssh
在linux 上安装
sudo apt-get install openssh-server
获取ip 地址通过ifconfig, inet 后面有ip
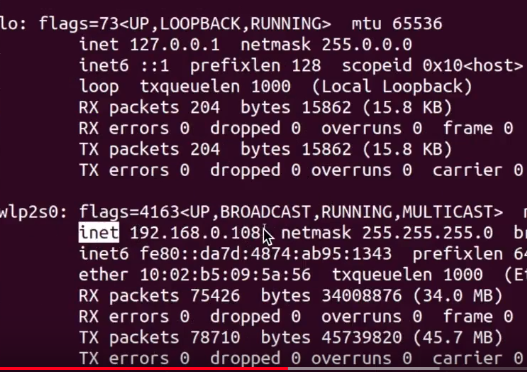
#在mac上
ssh becks@192.168.0.108 #becks 是linux 的用户名
然后mac terminal 就可以控制linux terminal 了

在mac 输入 退出ssh
exit
sort
| flag | 说明 |
|---|---|
-b |
ignore leading blank |
-d |
dictionary order, 只考虑blanks 和 alphabets |
-f |
ignore case 忽略大小写 |
-H |
month sort, 比如 (unknown)’’ < ‘JAN’ < ‘DEC’ |
-h |
Human readable sort, 比如 (2K, 1G) |
-i |
ignore nonprinting 不考虑空格 |
-k |
sort via a key, key gives location and type. e.g. -k 3 表示第三位 |
-n |
compare to string numerical value |
-R |
random sort, shuffle |
-r |
sort on reversed order |
-t --field-separator=SEP |
field separator, use SEP instead of nonblank 注: 如果用escape character 加 $, sort -t$’\t’ -n -k2``` |
-u |
unique |
#认为字典排序:
$ cat /etc/passwd | sort
#反转排序:
$ cat /etc/passwd | sort -r
#按特定字段排序:
$ cat /etc/passwd | sort -t':' -k 3 -n
上面的-t参数用于指定字段的分隔符,这里是以”:”作为分隔符;-k 字段号用于指定对哪一个字段进行排序。这里/etc/passwd文件的第三个字段为数字,默认情况下是以字典序排序的,如果要按照数字排序就要加上-n参数:, 结果按照0,1,3,4,5… 顺序排序, 如果不加-n 按照 0, 100, 10, 101, … 2, 200, 顺序排序
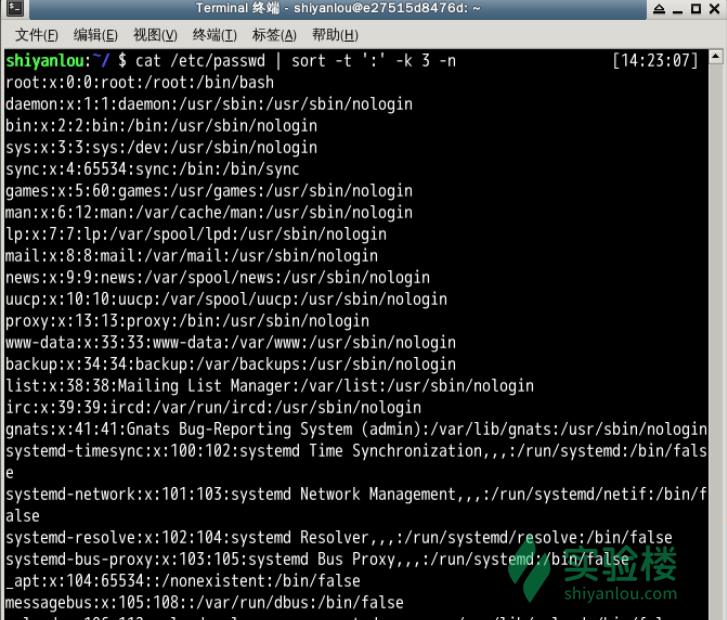
sudo
sudo: superuser do: allow you some priviledge as adminstrator or a power user
有时候比如mkdir dir, show permission denied error, 用sudo tell linux command to execute as administrator
比如install G++, GCC, will ask user priviledge
sudo mkdir dir #需要provide password, run as administrator
sudo apt-get install g++ # apt-get install : install software
sudo -s #change priviledge from local user to root
tar
tar: Tape Archive, compress and extract file
在 Linux 上面更常用的是 tar 工具,tar 原本只是一个打包工具,只是同时还是实现了对 7z、gzip、xz、bzip2 等工具的支持,这些压缩工具本身只能实现对文件或目录(单独压缩目录中的文件)的压缩,没有实现对文件的打包压缩,所以我们也无需再单独去学习其他几个工具,tar 的解压和压缩都是同一个命令,只需参数不同,使用比较方便。
| flag | 说明 |
|---|---|
-c |
创建一个tar包文件 |
-f |
指定创建文件名 注意文件名必须紧跟在 -f 参数之后,比如不能写成 tar -fc shiyanlou.tar,可以写成 tar -f shiyanlou.tar -c ~ |
-v |
可视的的方式输出打包的文件 |
-p |
留文件的属性 |
-h |
备份链接指向的源文件而不是链接本身 |
-x |
解包一个文件 |
-t |
只查看文件不解包 |
-C |
解包到指定目录 |
创建一个 tar 包:
cd /home/shiyanlou
tar -P -cf shiyanlou.tar /home/shiyanlou/Desktop
#上面命令中,-P 保留绝对路径符,-c 表示创建一个 tar 包文件,-f 用于指定创建的文件名,
解包一个文件(-x 参数)到指定路径的已存在目录(-C 参数):
mkdir tardir
tar -xf shiyanlou.tar -C tardir
只查看不解包文件 -t 参数:
tar -tf shiyanlou.tar
保留文件属性和跟随链接(符号链接或软链接),有时候我们使用 tar 备份文件当你在其他主机还原时希望保留文件的属性(-p 参数)和备份链接指向的源文件而不是链接本身(-h 参数):
$ tar -cphf etc.tar /etc
对于创建不同的压缩格式的文件,对于 tar 来说是相当简单的,需要的只是换一个参数
| 压缩文件格式 | 参数 |
|---|---|
*.tar.gz |
-z |
*.tar.xz |
-J |
*tar.bz2 |
-j |
我们只需要在创建 tar 文件的基础上添加 -z 参数,使用 gzip 来压缩文件:
tar -czf shiyanlou.tar.gz /home/shiyanlou/Desktop
解压 *.tar.gz 文件:
tar -xzf shiyanlou.tar.gz
tar -cvf test.tar test #cvf: create verb, f filename, 把test folder compress 成命名为test tar 压缩文件
tar -xvf test.tar #xvf x: extract v verb, f filename, 把test.tar extract 压缩文件
#有时候用 tar.gz gz stands for gzip format
tar -cvfz test.tar.gz f.txt #z 表示生成gz file, z必须在c flag 之后, 压缩文件成tar.gz
tar -xvfz test.tar.gz f.txt #解压 gz 文件
man tar > tar.txt #把tar 的man output 到tar.txt 中
tee
| 选项 | 说明 |
|---|---|
-a |
append to file not overwrite |
read from standard input and write to standard output and file
你可能还有这样的需求,除了需要将输出重定向到文件,也需要将信息打印在终端。那么你可以使用tee命令来实现:
$ echo 'hello shiyanlou' | tee hello
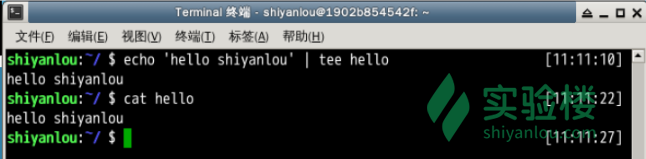
time
显示command 运行时间, 格式:
time command ...
e.g.
time head -1 file.txt
会显示
real: 0.013s
user: 0.001s
sys: 0.005s
top
top 工具是我们常用的一个查看工具,能实时的查看我们系统的一些关键信息的变化, top是一个可以交互的
| 常用交互命令 | 解释 |
|---|---|
q |
退出程序 |
I |
切换显示平均负载和启动时间的信息, when in Irix mode, task’s CPU usage will be divided by the number of CPUs, 比如4个CPU 除以4 |
P |
根据CPU使用百分比大小进行排序 |
M |
根据驻留内存大小进行排序 |
i |
忽略闲置和僵死的进程,这是一个开关式命令 |
k |
终止一个进程,系统提示输入 PID 及发送的信号值。一般终止进程用 15 信号,不能正常结束则使用 9 信号。安全模式下该命令被屏蔽。 |
top 是一个在前台执行的程序,所以执行后便进入到这样的一个交互界面,正是因为交互界面我们才可以实时的获取到系统与进程的信息。在交互界面中我们可以通过一些指令来操作和筛选。在此之前我们先来了解显示了哪些信息。
我们看到 top 显示的第一排,
| 内容 | 解释 |
|---|---|
top |
表示当前程序的名称 |
11:05:18 |
表示当前的系统的时间 |
up 8 days,17:12 |
表示该机器已经启动了多长时间 |
1 user |
表示当前系统中只有一个用户 |
load average: 0.29,0.20,0.25 |
分别对应1、5、15分钟内cpu的平均负载 |
load average 在 wikipedia 中的解释是 the system load is a measure of the amount of work that a computer system is doing 也就是对当前 CPU 工作量的度量,具体来说也就是指运行队列的平均长度,也就是等待 CPU 的平均进程数相关的一个计算值。
我们该如何看待这个load average 数据呢?
假设我们的系统是单 CPU、单内核的,把它比喻成是一条单向的桥,把CPU任务比作汽车。
load = 0的时候意味着这个桥上并没有车,cpu 没有任何任务;load < 1的时候意味着桥上的车并不多,一切都还是很流畅的,cpu 的任务并不多,资源还很充足;load = 1的时候就意味着桥已经被车给占满了,没有一点空隙,cpu 的已经在全力工作了,所有的资源都被用完了,当然还好,这还在能力范围之内,只是有点慢而已;load > 1的时候就意味着不仅仅是桥上已经被车占满了,就连桥外都被占满了,cpu 已经在全力工作,系统资源的用完了,但是还是有大量的进程在请求,在等待。若是这个值大于2、大于3,表示进程请求超过 CPU 工作能力的 2 到 3 倍。而若是这个值 > 5 说明系统已经在超负荷运作了。 这是单个 CPU 单核的情况,而实际生活中我们需要将得到的这个值除以我们的核数来看。我们可以通过以下的命令来查看 CPU 的个数与核心数
来看 top 的第二行数据,基本上第二行是进程的一个情况统计
| 内容 | 解释 |
|---|---|
Tasks: 26 total |
进程总数 |
1 running |
1个正在运行的进程数 |
25 sleeping |
25个睡眠的进程数 |
0 stopped |
没有停止的进程数 |
0 zombie |
没有僵尸进程数 |
来看 top 的第三行数据,这一行基本上是 CPU 的一个使用情况的统计了
| 内容 | 解释 |
|---|---|
Cpu(s): 1.0%us |
用户空间进程占用CPU百分比 |
1.0% sy |
内核空间运行占用CPU百分比 |
0.0%ni |
用户进程空间内改变过优先级的进程占用CPU百分比 |
97.9%id |
空闲CPU百分比 |
0.0%wa |
等待输入输出的CPU时间百分比 |
0.1%hi |
硬中断(Hardware IRQ)占用CPU的百分比 |
0.0%si |
软中断(Software IRQ)占用CPU的百分比 |
0.0%st |
(Steal time) 是 hypervisor 等虚拟服务中,虚拟 CPU 等待实际 CPU 的时间的百分比 |
CPU 利用率是对一个时间段内 CPU 使用状况的统计,通过这个指标可以看出在某一个时间段内 CPU 被占用的情况,而 Load Average 是 CPU 的 Load,它所包含的信息不是 CPU 的使用率状况,而是在一段时间内 CPU 正在处理以及等待 CPU 处理的进程数情况统计信息,这两个指标并不一样。
来看 top 的第四行数据,这一行基本上是内存的一个使用情况的统计了:
| 内容 | 解释 |
|---|---|
8176740 total |
物理内存总量 |
8032104 used |
使用的物理内存总量 |
144636 free |
空闲内存总量 |
313088 buffers |
用作内核缓存的内存量 |
注意 系统中可用的 物理内存最大值并不是 free 这个单一的值,而是 free + buffers + swap 中的 cached 的和
来看 top 的第五行数据,这一行基本上是交换区的一个使用情况的统计了
| 内容 | 解释 |
|---|---|
total |
交换区总量 |
used |
使用的交换区总量 |
free |
空闲交换区总量 |
cached |
缓冲的交换区总量,内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖 |
再下面就是进程的一个情况了
| 列名 | 解释 |
|---|---|
PID |
进程id |
USER |
该进程的所属用户 |
PR |
该进程执行的优先级 priority 值 |
NI |
该进程的 nice 值 |
VIRT |
该进程任务所使用的虚拟内存的总数 |
RES |
该进程所使用的物理内存数,也称之为驻留内存数 |
SHR |
该进程共享内存的大小 |
S |
该进程进程的状态: S=sleep R=running Z=zombie |
%CPU |
该进程CPU的利用率 |
%MEM |
该进程内存的利用率 |
TIME+ |
该进程活跃的总时间 |
COMMAND |
该进程运行的名字 |
注意
NICE 值叫做静态优先级,是用户空间的一个优先级值,其取值范围是-20至19。这个值越小,表示进程”优先级”越高,而值越大“优先级”越低。nice值中的 -20 到 19,中 -20 优先级最高, 0 是默认的值,而 19 优先级最低
PR 值表示 Priority 值叫动态优先级,是进程在内核中实际的优先级值,进程优先级的取值范围是通过一个宏定义的,这个宏的名称是 MAX_PRIO,它的值为 140。Linux 实际上实现了 140 个优先级范围,取值范围是从 0-139,这个值越小,优先级越高。而这其中的 0 - 99 是实时进程的值,而 100 - 139 是给用户的。
其中 PR 中的 100 to 139 值部分有这么一个对应 PR = 20 + (-20 to +19),这里的 -20 to +19 便是nice值,所以说两个虽然都是优先级,而且有千丝万缕的关系,但是他们的值,他们的作用范围并不相同
VIRT 任务所使用的虚拟内存的总数,其中包含所有的代码,数据,共享库和被换出 swap空间的页面等所占据空间的总数
计算load 源代码
#define FSHIFT 11 /* nr of bits of precision */
#define FIXED_1 (1<<FSHIFT) /* 1.0 as fixed-point(定点) */
#define LOAD_FREQ (5*HZ) /* 5 sec intervals,每隔5秒计算一次平均负载值 */
#define CALC_LOAD(load, exp, n) \
load *= exp; \
load += n*(FIXED_1 - exp); \
load >>= FSHIFT;
unsigned long avenrun[3];
EXPORT_SYMBOL(avenrun);
/*
* calc_load - given tick count, update the avenrun load estimates.
* This is called while holding a write_lock on xtime_lock.
*/
static inline void calc_load(unsigned long ticks)
{
unsigned long active_tasks; /* fixed-point */
static int count = LOAD_FREQ;
count -= ticks;
if (count < 0) {
count += LOAD_FREQ;
active_tasks = count_active_tasks();
CALC_LOAD(avenrun[0], EXP_1, active_tasks);
CALC_LOAD(avenrun[1], EXP_5, active_tasks);
CALC_LOAD(avenrun[2], EXP_15, active_tasks);
}
}
top: provide you dynamic real time view of running system. Used to see which program take more of your CPU and which program consuming more of your memory
top #give you view of system, it refreshing every second
s # can update time, 输入1 refresh every 1 second
i # to filter idle process
k # 把鼠标选中PID, press k, kill process
q # quit the top view
PID: process ID, 同一个程序不同时候run pid 可能不一样的
#查看物理CPU的个数
#cat /proc/cpuinfo |grep "physical id"|sort |uniq|wc -l
#每个cpu的核心数
cat /proc/cpuinfo |grep "physical id"|grep "0"|wc -l
touch
Touch is the easist way to create new empty file in Linux. It is also used for changing timestamp on existing file or directory
you cannot create new directory using touch, can only create empty file
不能用于创建folder, 显示error: setting times of foldername, 因为无法创建时间对于folder
touch file6 #建一个新的empty file6
touch f7.txt #建立一个新的txt, 名字是f7
touch file1.txt #修改file1.txt的timestamp, 不修改内容,只修改了timestamp
touch file{1..10}.txt #创建 file1.txt , file2.txt , ... ,file10.txt
tr
tr 命令可以用来删除一段文本信息中的某些文字。或者将其进行转换。translation
使用方式:
tr [option]...SET1 [SET2]
| 选项 | 说明 |
|---|---|
-d or --delete |
删除和set1匹配的字符, 注意不是全词匹配也不是按字符顺序匹配 |
-s or --squeeze-repeat |
去除set1指定的在输入文本中连续并重复的字符 |
[:alnum:] |
全部转为数字或字母 |
[:alpha:] |
全部转为字母 |
[:digit:] |
全部转为数字 |
'[:lower:]' or '[a-z]' |
全部转为小写 |
'[:upper:]' or '[A-Z] |
全部转化为大写 |
# 删除 "hello shiyanlou" 中所有的'o','l','h'
$ echo 'hello shiyanlou' | tr -d 'olh'
# 将"hello" 中的ll,去重为一个l
$ echo 'hello' | tr -s 'l'
# 将输入文本,全部转小写为大写输出
$ echo 'input some text here' | tr '[:lower:]' '[:upper:]'
# 上面的'[:lower:]' '[:upper:]'你也可以简单的写作'[a-z]' '[A-Z]',当然反过来将大写变小写也是可以的
echo 'This is a test ' | tr -s '[a-z]' '9'
# 返回: 'T9 9 9 9 '
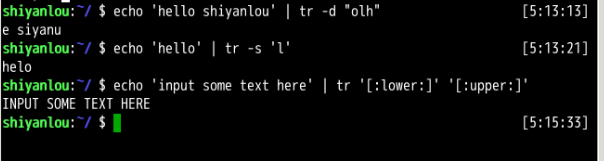
$ tr '{}' '()' < inputfile > outputfile
The above command will read each character from “inputfile”, translate if it is a brace, and write the output in “outputfile”.
type
区分内建命令与外部命令, 详见Linux基础, 内建命令与外部命令
uniq
uniq命令可以用于过滤或者输出重复行。
| flag | 说明 |
|---|---|
-c |
prefix lines by the number of occurence |
-d |
print only duplicated lines, one for each group |
-D |
print all duplicated lines |
-f --skip-fields=N |
avoid comparing first N fields |
-i |
ignore cases when comparing 忽略大小写 |
-s --skip-chars=N |
avoid comparing first N characters |
-u |
print only unique line |
-w --check-chars=N |
compare no more than N characters in lines |
过滤重复行
我们可以使用history命令查看最近执行过的命令,不过你可能只想查看使用了哪个命令而不需要知道具体干了什么,那么你可能就会要想去掉命令后面的参数然后去掉重复的命令:
$ history | cut -c 8- | cut -d ' ' -f 1 | uniq
#cut -c 8- 除去前8 char 的编号 和 空格的对齐
# cut -d ' ' -f 1: 以' '为分界,split 只要第一个,比如echo '123', 只留下echo
uniq命令只能去连续重复的行,不是全文去重,所以要达到预期效果,我们先排序:
$ history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq
# 或者$ history | cut -c 8- | cut -d ' ' -f 1 | sort -u
这就是 Linux/UNIX 哲学吸引人的地方,大繁至简,一个命令只干一件事却能干到最好。
输出重复行
# 输出重复过的行(重复的只输出一个)及重复次数
$ history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq -dc
# 输出所有重复的行
$ history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq -D
useradd /adduser
create user
useradd the_name_of_user #syntax
sudo useradd mark -m -s /bin/bash -g users -c "my comment"
#-m: create default home directory for this user
#-s /bin/bash allow usesr to use shell
#-g assign group, default group is users
#-c "my comment" provide comment to user
#-G assign/give user defined group
#sudo: because you don't want anybody create user, only root can create user
sudo passwd mark #change password for user
adduser 和 useradd 的区别是什么? 答:useradd 只创建用户,创建完了用 当前用户的passwd 去设置新用户的密码。adduser 会创建用户,创建目录,创建密码(提示你设置),做这一系列的操作。其实 useradd、userdel 这类操作更像是一种命令,执行完了就返回。而 adduser 更像是一种程序,需要你输入、确定等一系列操作。
userdel
sudo userdel mark #delete user mark (username, password, data), not delete home directory for user
sudo userdel -r mark #delete user (home directory, username, password, data)
sudo -r /home/mark/ #remove all the data from user
#或者用
sudo deluser mark --remove-home
vim
vim 的6种模式
普通模式(Normal mode)
在普通模式中,用的编辑器命令,比如移动光标,删除文本等等。这也是Vim启动后的默认模式。这正好和许多新用户期待的操作方式相反(大多数编辑器默认模式为插入模式)。
Vim强大的编辑能来自于其普通模式命令。普通模式命令往往需要一个操作符结尾。例如普通模式命令dd删除当前行,但是第一个”d”的后面可以跟另外的移动命令来代替第二个d,比如用移动到下一行的”j”键就可以删除当前行和下一行。另外还可以指定命令重复次数,2dd(重复dd两次),和dj的效果是一样的。用户学习了各种各样的文本间移动/跳转的命令和其他的普通模式的编辑命令,并且能够灵活组合使用的话,能够比那些没有模式的编辑器更加高效地进行文本编辑。
在普通模式中,有很多方法可以进入插入模式。比较普通的方式是按a(append/追加)键或者i(insert/插入)键。
插入模式(Insert mode)
在这个模式中,大多数按键都会向文本缓冲中插入文本。大多数新用户希望文本编辑器编辑过程中一直保持这个模式。
在插入模式中,可以按ESC键回到普通模式。
可视模式(Visual mode)
这个模式与普通模式比较相似。但是移动命令会扩大高亮的文本区域。高亮区域可以是字符、行或者是一块文本。当执行一个非移动命令时,命令会被执行到这块高亮的区域上。Vim的”文本对象”也能和移动命令一样用在这个模式中。
选择模式(Select mode)
这个模式和无模式编辑器的行为比较相似(Windows标准文本控件的方式)。这个模式中,可以用鼠标或者光标键高亮选择文本,不过输入任何字符的话,Vim会用这个字符替换选择的高亮文本块,并且自动进入插入模式。
命令行模式(Command line mode)
在命令行模式中可以输入会被解释成并执行的文本。例如执行命令(:键),搜索(/和?键)或者过滤命令(!键)。在命令执行之后,Vim返回到命令行模式之前的模式,通常是普通模式。
Ex模式(Ex mode)
这和命令行模式比较相似,在使用:visual命令离开Ex模式前,可以一次执行多条命令。 这其中我们常用到就是普通模式、插入模式和命令行模式,本课程也只涉及这三个常用模式的内容
vim test #用vim 创建或打开test 文件
i # 进入插入 模式
a # 进入插入模式 append
ESC or Ctrl + [ #进入普通模式
: #进入命令模式
:w #保存文档 但不会推出
:wq #输入wq 表示 save and exit
:w 文件名 #将文档另存为其他文件名或存到其他路径下
cat test #打印刚写的test file
从普通模式进入命令行模式(Command line mode)
| 命令 | 说明 |
|---|---|
:q! |
强制退出,不保存 |
:q |
退出 |
:wq! |
强制保存并退出 |
:w <文件路径> |
另存为 |
:saveas 文件路径 |
另存为 |
:x |
保存并退出 |
:wq |
保存并退出 |
:set number |
显示行数 |
普通模式 下输入Shift+zz即可保存退出vim
vim #打开vim 编辑器,但不会打开任何文件
:e iphone #创建一个名为iphone的文件
#输入以下:
12345678
abcdefghijk
shiyanlou.com
Esc #进入普通模式
普通模式下移动光标
可以用方向键或者 h,j,k,l 移动光标
| 按键 | 说明 |
|---|---|
h |
左 |
l |
右(小写L) |
j |
下 |
k |
上 |
w |
移动到下一个单词开头 |
e |
到当前单词的结尾 |
b |
到前一个单词的开头 |
ge |
到前一个单词的结尾 |
0或^ |
到行头 |
$ |
到行尾 |
f<字母> |
向后搜索<字母>并跳转到第一个匹配的位置(非常实用),只能是第一个字母 |
F<字母> |
向前搜索<字母>并跳转到第一个匹配的位置 |
t<字母> |
向后搜索<字母>并跳转到第一个匹配位置之前的一个字母(不常用) |
T<字母> |
向前搜索<字母>并跳转到第一个匹配位置之后的一个字母(不常用) |
b |
移动到上一个单词 |
nG(n Shift+g) |
游标移动到第 n 行(如果默认没有显示行号,请先进入命令模式,输入:set nu以显示行号) |
gg |
游标移动到到第一行 |
G(Shift+g) |
到最后一行 |
Ctrl+o |
可以使用 Ctrl+o 快速回到上一次(跳转前)光标所在位置,这个技巧很实用,比如当你在写代码时,忽然想起有个 bug,需要修改,这时候你跳过去改好了,只需要按下 Ctrl+o 就可以回到你之前的位置。 |
普通模式下删除vim文本信息 进入普通模式,使用下列命令可以进行文本快速删除:
| 命令 | 说明 |
|---|---|
x or . |
删除游标所在的字符 |
X |
删除游标所在前一个字符 |
Delete |
同x |
dd |
删除整行(实际上是剪切) |
dw or daw |
删除一个单词(不适用中文), daw delete a word |
dnw |
用具体数字代替n, 表示删除n个单词, e.g. d3w delete 3 words |
d$或D |
删除至行尾 |
d^ |
删除至行首 |
dG |
删除到文档结尾处 |
d1G |
删至文档首部 |
N<command> |
用具体数字代替n 表示重复后面的操作. e.g. 2dd 表示一次删除2行 |
普通模式下复制粘贴 copy & paste
| 命令 | 说明 |
|---|---|
yy |
复制游标所在的整行(3yy表示复制3行) |
y^ or y0 |
制至行首。不含光标所在处字符 |
y$ |
复制至行尾。含光标所在处字 |
yw |
复制一个单词 |
y2w |
复制两个单词 |
yG |
复制至文本末 |
y1G |
复制至文本开头 |
p |
p(小写)代表粘贴至光标后(下) |
P |
P(大写)代表粘贴至光标前(上) |
ddp |
剪切粘贴,交换上下行, 可以先dd 然后到指定行 p, 实现行之间剪切粘贴 |
普通模式下替换 replace 和撤销(Undo)命令
| 命令 | 说明 |
|---|---|
r+<待替换字母> |
将游标所在字母替换为指定字母 |
R |
连续替换,直到按下Esc |
cc |
替换整行,即删除游标所在行,并进入插入模式 |
cw |
替换一个单词,即删除一个单词,并进入插入模式 |
C(大写) |
替换游标以后至行末 |
~ |
反转游标所在字母大小写(小写变大写,或者大写变小写) |
u{n} |
撤销一次或n次操作 |
U(大写) |
撤销当前行的所有修改 |
Ctrl+r |
redo,即撤销undo的操作 |
普通模式下快速调整缩 format
| 命令 | 说明 |
|---|---|
>> |
整行将向右缩进 |
<< |
整行向左回退 |
:set shiftwidth |
进行设置可以控制缩进和回退的字符数 |
:set shiftwidth? |
获取目前的设定值 |
:set shiftwidth=10 |
设置缩进为10个字符 |
:ce |
ce(center)命令使本行内容居中 |
:ri |
ri(right)命令使本行文本靠右 |
:le |
le(left)命令使本行内容靠左 |
vim的功能设定
下面设定值, 设定值退出vim后不会保存。要永久保存配置需要修改vim配置文件。 vim的配置文件~/.vimrc(在/etc/vim/vimrc),可以打开文件进行修改,不过务必小心不要影响vim正常使用
| 命令 | 说明 |
|---|---|
set nu or set number |
显示行数 |
:set或者:se |
显示所有修改过的配置 |
:set al |
l 显示所有的设定值 |
:set option? |
显示option的设定值 |
:set nooption |
取消当前设定值 |
:set autoindent(ai) |
设置自动缩进 |
:set autowrite(aw) |
设置自动存档,默认未打开 |
:set background=dark或light |
,设置背景风格 |
:set backup(bk) |
设置自动备份,默认未打开 |
:set cindent(cin) |
设置C语言风格缩进 |
:syntax on |
语法加“靓”(亮) |
:syntax off |
语法不加“靓”(亮) |
:set cindent |
C 语言自动缩进(可简写为set cin) |
:set sw=8 |
自动缩进宽度(需要set cin才有用) |
:set ts=8 |
设定 TAB 宽度 |
:set number |
显示行号 |
:set nonumber |
不显示行号 |
:setsm |
括号自动匹配 |
普通模式下快速调整缩 find
| 命令 | 说明 |
|---|---|
/ |
/ 键入需要查找的字符串 按回车后就会进行向下查找, n 查找下一个内容, N 查找上一个内容 |
? |
? 与/ 类似,但是是向上查找 |
:noh |
可取消搜索 |
\* |
寻找游标所在处的单词 |
\# |
同上,但 \#是向前(上)找,\*则是向后(下)找 |
g\* |
同\* ,但部分符合该单词即可 |
g\# |
同\# ,但部分符合该单词即可 |
使用 vim 打开文件进行编辑, 搜索有高亮,需要在配置文件 .vimrc 中设置 set hls
普通模式 选择
| 命令 | 说明 |
|---|---|
v |
进入字符选择模式,就可以移动光标,光标走过的地方就会选取。再次按下v后就会取消选取 |
Shift+v |
会把整行选取,可以上下移动光标选更多的行,同样,再按一次 Shift+v 就可以取消选取 |
Ctrl+v |
这是区域选择模式,可以进行矩形区域选择,再按一次 Ctrl+v 取消选取 |
在可视模式下输入 d 删除选取区域内容
在可视模式下输入 y复制选取区域内容
e.g.
- 在普通模式下
9G跳转到第9行,输入Shift+v(小写V),进入可视模式进行行选择,选中5行,按下>>`缩进,将5行整体缩进一个shiftwidth - 在普通模式下输入
Ctrl+v(小写V,进入可视模式进行矩形区域选择,选中第一列字符然后 pressx删除整列
从普通模式进入插入模式
| 命令 | 说明 |
|---|---|
i |
在当前光标处进行编辑 |
I |
在行首插入 |
A |
在行末插入 |
a |
在光标后插入编辑 |
o |
在当前行后插入一个新行 |
O |
在当前行前插入一个新行 |
cw |
替换从光标所在位置后到一个单词结尾的字符 |
普通模式下 多个vim窗口
| 命令 | 说明 |
|---|---|
new |
打开新的vim 窗口 |
:sp 1.txt |
打开新的水平分屏视窗来编辑1.txt |
:vsp 2.txt |
打开新的垂直分屏视窗来编辑2.txt |
Ctrl+w s |
将当前窗口分割成两个水平的窗口 |
Ctrl+w v |
将当前窗口分割成两个垂直的窗口 |
Ctrl+w q |
即 :q 结束分割出来的视窗。如果在新视窗中有输入需要使用强制符!即:q! |
Ctrl+w o |
打开一个视窗并且隐藏之前的所有视窗 |
Ctrl+w j |
移至下面视窗 |
Ctrl+w k |
移至上面视窗 |
Ctrl+w h |
移至左边视窗 |
Ctrl+w l |
移至右边视窗 |
Ctrl+w J |
将当前视窗移至下面 |
Ctrl+w K |
将当前视窗移至上面 |
Ctrl+w H |
将当前视窗移至左边 |
Ctrl+w L |
将当前视窗移至右边 |
Ctrl+w - |
减小视窗的高度 |
Ctrl+w + |
增加视窗的高度 |
使用vim编辑多个文件
vim 1.txt 2.txt #默认进入1.txt
默认进入1.txt文件的编辑界面
- 命令行模式下输入
:n编辑 2.txt 文件,可以加!即:n!强制切换,之前一个文件的输入没有保存,仅仅切换到另一个文件 - 命令行模式下输入
:N编辑 1.txt 文件,可以加!即:N!强制切换,之前文件内的输入没有保存,仅仅是切换到另一个文件
| 命令 | 说明 |
|---|---|
e 3.txt |
打开新文件3.txt |
e# |
#回到前一个文件 |
e! 4.txt |
新打开文件4.txt,放弃正在编辑的文件 |
ls |
可以列出以前编辑过的文档 |
2.txt |
(或者编号)可以直接进入文件2.txt编辑 |
2.txt |
(或者编号)可以删除以前编辑过的列表中的文件项目 |
f |
显示正在编辑的文件名 |
f new.txt |
改变正在编辑的文件名字为new.txt |
vim -r 1.txt 进入文档后, vim -r 1.txt |
因为断电等原因造成文档没有保存,可以恢复 |
创建加密文档
vim -x file1
输入密码 确认密码 这样在下一次打开时,vim就会要求你输入密码
命令模式 vim执行外部命令
在命令行模式中输入!可以执行外部的shell命令
| 命令 | 说明 |
|---|---|
:!ls |
用于显示当前目录的内容 |
:!rm |
FILENAME 用于删除名为 FILENAME 的文件 |
:w |
FILENAME可将当前 VIM 中正在编辑的文件另存为 FILENAME 文件 |
查看帮助
| 命令 | 说明 |
|---|---|
F1 |
普通模式下按F1打开vim自己预设的帮助文档 |
:h shiftwidth |
打开名为shiftwidth的帮助文件 |
:ver |
显示版本及参数 |
watch
run scripts for command at a regular interval or repeatedly
watch free -m #可以看见几秒会更新一次
Ctrl + C #exit watch command
watch -n 1 free -m #让free -m command run every 1 second
watch -n 0,5 free -m #让free -m command run every 0.5 second
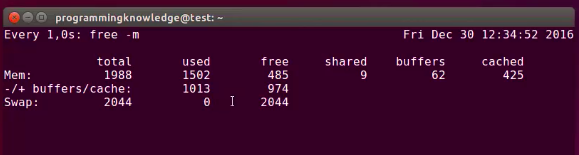
wc
wc: world count, print a count of lines, words and characters for each files
| flag | 说明 |
|---|---|
-c |
print bytes count 字节数 |
-m |
print chars count 字符数 |
-l |
print lines 行数 |
-L |
print max line length 最长行的字节数 |
-w |
print the word count |
注意:对于西文字符来说,一个字符就是一个字节,但对于中文字符一个汉字是大于2个字节的,具体数目是由字符编码决定的
# 行数
wc -l /etc/passwd
# 单词数
wc -w /etc/passwd
# 字节数
wc -c /etc/passwd
# 字符数
wc -m /etc/passwd
# 最长行字节数
wc -L /etc/passwd
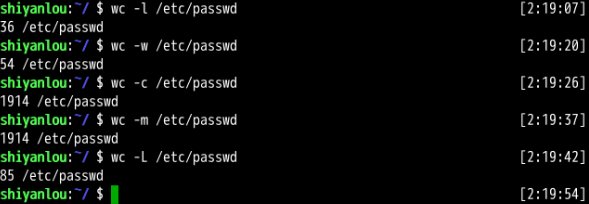
ls -dl /etc/*/ | wc -l #打印ls -dl /etc/*/ 有多少行
wc test.txt #打出#lines, #words, #characters
wc -c test.txt #只打出#characters
wc -l test.txt #只打出#lines
wc -w test.txt #只打出#words
wc -L test.txt #只给出number of character in longest line
1, 6, 42: 1 number of line, 6 number of words, 42 number of characters
whereis
简单快速搜索
whereis who #找who command 来自哪个文件夹
whereis find
你会看到 whereis find 找到了三个路径,两个可执行文件路径和一个 man 在线帮助文件所在路径,这个搜索很快,因为它并没有从硬盘中依次查找,而是直接从数据库中查询。whereis 只能搜索二进制文件(-b),man 帮助文件(-m)和源代码文件(-s)。如果想要获得更全面的搜索结果可以使用 locate 命令。
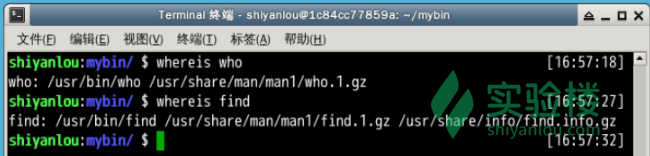
which & what
which 本身是 Shell 内建的一个命令,我们通常使用 which 来确定是否安装了某个指定的软件,因为它只从 PATH 环境变量指定的路径中去搜索命令 :
which: where software/command located
what: display short manual page description
#which ls #give location where ls command located
which firefox # location of bash
which bash # location of bash
whatis ls # short description, to know what ls doing command
whatis grep #short description, to know what is grep command
who
who 显示terminal 信息
| 参数 | Meaning | |
|---|---|---|
| -a | 打印全部 terminal 打开信息,比如 伪终端名称,打开时间. 比如打开了两个terminal, 会显示两行 | |
| -d | 打印死掉的进程 | |
| -m | 同who am i, 显示当前终端打开的信息 | |
| -q | 打印当前所有打开的 terminal 用户数及用户名 | |
| -u | 打印当前所有打开的 terminal 登录用户登录详细信息, 类似 -a | |
| -r | 打印运行等级 |
xargs
| 参数 | Meaning |
|---|---|
-0 or --null |
arguments are separated by null not white space. disable quote and backslash processing and logical EOF processing |
-a |
read arguments from file not standard inputs |
-E or -e |
如果遇到 EOF, ignore 接下来的input |
-n or --max-args=N |
used as N max arguments per command line |
-p or --interactive |
prompt before running command, run command 之前会询问 |
-t or --verbose |
print command before execute them |
xargs 是一条 UNIX 和类 UNIX 操作系统的常用命令。它的作用是将参数列表转换成小块分段传递给其他命令,以避免参数列表过长的问题。
这个命令在有些时候十分有用,特别是当用来处理产生大量输出结果的命令如 find,locate 和 grep 的结果,详细用法请参看 man 文档。
$ cut -d: -f1 < /etc/passwd | sort | xargs echo
上面这个命令用于将/etc/passwd文件按:分割取第一个字段排序后,使用echo命令生成一个列表。
The xargs command in UNIX is a command line utility for building an execution pipeline from standard input. By default xargs reads items from standard input as separated by blanks and executes a command once for each argument 一次执行一个command 从 standard input
echo 'one two three' | xargs mkdir
ls #显示 one two three 3个文件夹
echo 'one two three' | xargs -n1 mkdir
#显示
mkdir one
mkdir two
mkdir three
echo 'one two three' | xargs -t mkdir
#显示
mkdir one two three
echo 'one two three' | xargs -t
#显示
echo 'one two three'
one two three
找到这个folder 下所有文件是 14天前被修改的,然后删除
find /tmp -mtime +14 | xargs rm
zip / unzip
| Flag | 说明 |
|---|---|
-r |
表示递归打包包含子目录的全部内容 |
-q |
参数表示为安静模式,即不向屏幕输出信息 |
-o |
表示输出文件,需在其后紧跟打包输出文件名 |
-[1-9] |
压缩级别 1 表示最快压缩但体积大,9 表示体积最小但耗时最久 |
-e |
使用 -e (encryption) 参数可以创建加密压缩包: |
-l |
解决Windows 系统与 Linux/Unix 在文本文件格式上的一些兼容问题, -l 参数将 LF 转换为 CR+LF 来达到以上目的 |
cd /home/shiyanlou
zip -r -q -o shiyanlou.zip /home/shiyanlou/Desktop
#后面使用 du 命令查看打包后文件的大小
du -h shiyanlou.zip
file shiyanlou.zip
设置压缩级别为 9 和 1(9 最大,1 最小),重新打包:
zip -r -9 -q -o shiyanlou_9.zip /home/shiyanlou/Desktop -x ~/*.zip #~ 表示 home directory
zip -r -1 -q -o shiyanlou_1.zip /home/shiyanlou/Desktop -x ~/*.zip
最后那个 -x 是为了排除我们上一次创建的 zip 文件,否则又会被打包进这一次的压缩文件中(新的压缩文件中没有上次压缩的文件),注意:这里只能使用绝对路径,否则不起作用。
我们再用 du 命令分别查看默认压缩级别、最低、最高压缩级别及未压缩的文件的大小:
h, –human-readable(顾名思义,你可以试试不加的情况)d, –max-depth(所查看文件的深度)
$ du -h -d 0 *.zip ~ | sort #同时显示当前文件下所有zip 和 home directory 文件大小
创建加密 zip 包
zip -r -e -o shiyanlou_encryption.zip /home/shiyanlou/Desktop
注意: 关于 zip 命令,因为 Windows 系统与 Linux/Unix 在文本文件格式上的一些兼容问题,比如换行符(为不可见字符),在 Windows 为 CR+LF(Carriage-Return+Line-Feed:回车加换行),而在 Linux/Unix 上为 LF(换行),所以如果在不加处理的情况下,在 Linux 上编辑的文本,在 Windows 系统上打开可能看起来是没有换行的。如果你想让你在 Linux 创建的 zip 压缩文件在 Windows 上解压后没有任何问题,那么你还需要对命令做一些修改:
$ zip -r -l -o shiyanlou.zip /home/shiyanlou/Desktop
需要加上 -l 参数将 LF 转换为 CR+LF 来达到以上目的。
unzip
| Flag | 说明 |
|---|---|
-q |
参数表示为安静模式,即不向屏幕输出信息 |
-l |
不想解压只想查看压缩包的内容你可以使用 -l 参数 |
-d |
指定路径 |
unzip shiyanlou.zip
#使用安静模式,将文件解压到指定目录:
unzip -q shiyanlou.zip -d ziptest
上述指定目录不存在,将会自动创建。
#如果你不想解压只想查看压缩包的内容你可以使用 -l 参数:
unzip -l shiyanlou.zip
注意: 使用 unzip 解压文件时我们同样应该注意兼容问题,不过这里我们关心的不再是上面的问题,而是中文编码的问题,通常 Windows 系统上面创建的压缩文件,如果有有包含中文的文档或以中文作为文件名的文件时默认会采用 GBK 或其它编码,而 Linux 上面默认使用的是 UTF-8 编码,如果不加任何处理,直接解压的话可能会出现中文乱码的问题(有时候它会自动帮你处理),为了解决这个问题,我们可以在解压时指定编码类型。
使用 -O(英文字母,大写 o)参数指定编码类型:
unzip -O GBK 中文压缩文件.zip
Run Multiple Terminal(; && || )
#; sequence matter
ls; pwd #先run ls 再显示pwd
date; cal ; pwd #先run date, 再run cal, 再pwd
#如果有中间一个command 是错的
date; CAL; pwd #date, pwd run 成功了, CAL 会显示command not found
#&& sequence matter, 顺序一个接一个
ls && pwd && date && cal #先run ls, 再pwd, 再date, 再cal
ls && CAL && pwd #先run ls, CAL error, not run pwd
ls || pwd #如果第一个command 成功了,不会run 第二个command
CAL || pwd #CAL command failure, pwd 会被run
Difference: ; run every command regardless success/failure of each command. && 如果中间的failure, does not go to the next command
FUN
《黑客帝国》电影里满屏幕代码的“数字雨”,在 Linux 里面你也可以轻松实现这样的效果,你只需要一个命令 cmatrix 。
sudo apt-get update; sudo apt-get install cmatrix
装好之后先不要急着执行,为了看到更好的效果,我们需要先修改终端的主题配色,在终端上面的【选项】中修改,修改为黑底绿字:
还可以改变代码的颜色:
cmatrix -C red
火炉
sudo apt-get install libaa-bin
aafire
Space Invaders: 类似在小霸王上面玩的小蜜蜂游戏
sudo apt-get install ninvaders
$ /usr/games/ninvaders

bb
$ sudo apt-get update
$ sudo apt-get install bb
$ /usr/games/bb
