Caching
Caches take advantage of the locality of reference principle: recently requested data is likely to be requested again. They are used in almost every computing layer: hardware, operating systems, web browsers, web applications, and more. A cache is like short-term memory: it has a limited amount of space, but is typically faster than the original data source and contains the most recently accessed items.
Caches can exist at all levels in architecture, but are often found at the level nearest to the front end (cache 通常接近front-end), where they are implemented to return data quickly without taxing downstream levels.
Application server cache
Placing a cache directly on a request layer node enables the local storage of response data. Each time a request is made to the service, the node will quickly return locally cached data if it exists. If it is not in the cache, the requesting node will fetch the data from the disk 先检查是否在cache, 如果不在fetch from the disk. The cache on one request layer node could also be located both in memory (which is very fast) and on the node’s local disk (faster than going to network storage) 可以是在memory or local disk.
What happens when you expand this to many nodes? If the request layer is expanded to multiple nodes, it’s still quite possible to have each node host its own cache. However, if your load balancer randomly distributes requests across the nodes, the same request will go to different nodes, thus increasing cache misses. Two choices for overcoming this hurdle are global caches and distributed caches.
针对cache miss的两种方法: global caches and distributed caches.
Content Delivery (or Distribution) Network (CDN)#
CDNs are a kind of cache that comes into play for sites serving large amounts of static media. In a typical CDN setup, a request will first ask the CDN for a piece of static media; the CDN will serve that content if it has it locally available. If it isn’t available, the CDN will query the back-end servers for the file, cache it locally, and serve it to the requesting user. (先看CDN 有没有local cache, 如果没有再query server)
If the system we are building is not large enough to have its own CDN, we can ease a future transition by serving the static media off a separate subdomain (e.g., static.yourservice.com) using a lightweight HTTP server like Nginx, and cut-over the DNS from your servers to a CDN later.
Cache Invalidation
If the data is modified in the database, it should be invalidated in the cache; if not, this can cause inconsistent application behavior. Solving this problem is known as cache invalidation
Write-through cache: Under this scheme, data is written into the cache and the corresponding database simultaneously. The cached data allows for fast retrieval and, since the same data gets written in the permanent storage, we will have complete data consistency between the cache and the storage. Also, this scheme ensures that nothing will get lost in case of a crash, power failure, or other system disruptions. (每次都保持cache 和 DB 的协同,但是high latency for write)
Although, write-through minimizes the risk of data loss, since every write operation must be done twice before returning success to the client, this scheme has the disadvantage of higher latency for write operations.
Write-around cache: This technique is similar to write-through cache, but data is written directly to permanent storage, bypassing the cache. This can reduce the cache being flooded with write operations that will not subsequently be re-read, but has the disadvantage that a read request for recently written data will create a “cache miss” and must be read from slower back-end storage and experience higher latency. (直接写入DB, pass cass,但是higher latency for read recent data, cache misses)
Write-back cache: Under this scheme, data is written to cache alone, and completion is immediately confirmed to the client. The write to the permanent storage is done after specified intervals or under certain conditions. This results in low-latency and high-throughput for write-intensive applications; however, this speed comes with the risk of data loss in case of a crash or other adverse event because the only copy of the written data is in the cache. (全部写入cache, 特定的时间段再写入DB, 有data 丢失的风险)
Cache eviction policies#
- First In First Out (FIFO): The cache evicts the first block accessed first without any regard to how often or how many times it was accessed before.
- Last In First Out (LIFO): The cache evicts the block accessed most recently first without any regard to how often or how many times it was accessed before.
- Least Recently Used (LRU): Discards the least recently used items first.
- Most Recently Used (MRU): Discards, in contrast to LRU, the most recently used items first.
- Least Frequently Used (LFU): Counts how often an item is needed. Those that are used least often are discarded first.
- Random Replacement (RR): Randomly selects a candidate item and discards it to make space when necessary.
What is a CDN?
A content delivery network (CDN) refers to a geographically distributed group of servers which work together to provide fast delivery of Internet content.
A CDN allows for the **quick transfer **of assets needed for loading Internet content including HTML pages, javascript files, stylesheets, images, and videos. The popularity of CDN services continues to grow, and today the majority of web traffic is served through CDNs, including traffic from major sites like Facebook, Netflix, and Amazon.
A properly configured CDN may also help protect websites against some common malicious attacks, such as Distributed Denial of Service (DDOS) attacks.
benefits of using a CDN
- Improving website load times - By distributing content closer to website visitors by using a nearby CDN server (among other optimizations), visitors experience faster page loading times. As visitors are more inclined to click away from a slow-loading site, a CDN can reduce bounce rates and increase the amount of time that people spend on the site. In other words, a faster a website means more visitors will stay and stick around longer.
- Reducing bandwidth costs - Bandwidth consumption costs for website hosting is a primary expense for websites. Through caching and other optimizations, CDNs are able to reduce the amount of data an origin server must provide, thus reducing hosting costs for website owners.
- Increasing content availability and redundancy - Large amounts of traffic or hardware failures can interrupt normal website function. Thanks to their distributed nature, a CDN can handle more traffic and withstand hardware failure better than many origin servers.
- Improving website security - A CDN may improve security by providing DDoS mitigation, improvements to security certificates, and other optimizations.
How does a CDN work?
At its core, a CDN is a network of servers linked together with the goal of delivering content as quickly, cheaply, reliably, and securely as possible. In order to improve speed and connectivity, a CDN will place servers at the exchange points between different networks (Server 放在所有network 中间).
These Internet exchange points (IXPs) are the primary locations where different Internet providers connect in order to provide each other access to traffic originating on their different networks. By having a connection to these high speed and highly interconnected locations, a CDN provider is able to reduce costs and transit times in high speed data delivery.
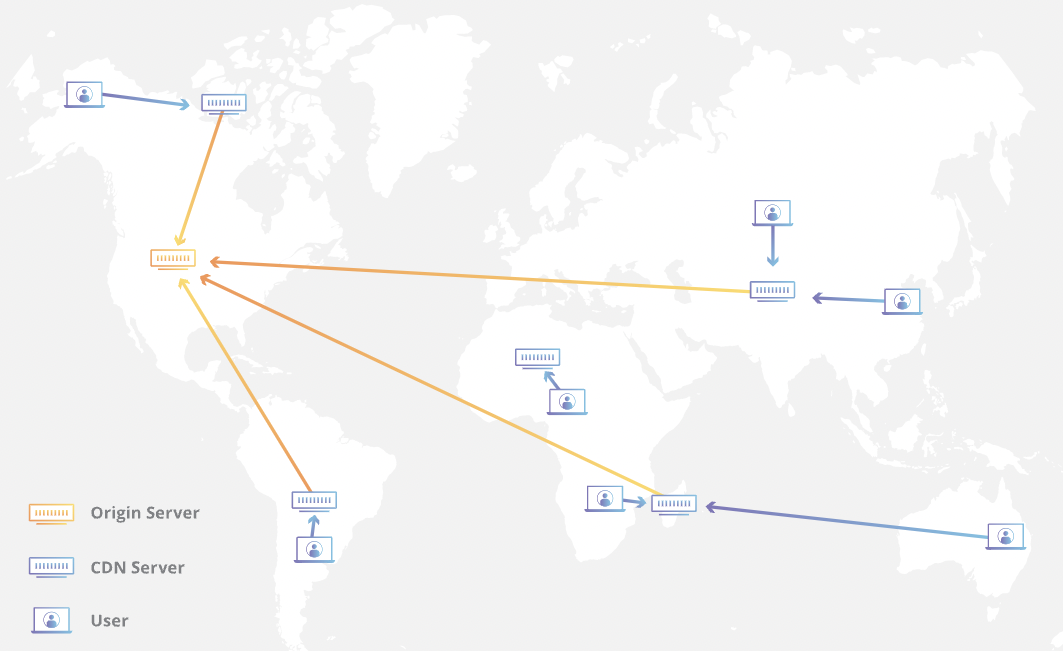
Beyond placement of servers in IXPs, a CDN makes a number of optimizations on standard client/server data transfers. CDNs place Data Centers at strategic locations across the globe, enhance security, and are designed to survive various types of failures and Internet congestion.
Latency - How does a CDN improve website load times?
- The globally distributed nature of a CDN means reduce distance between users and website resources (减少user 和website resource 距离). Instead of having to connect to wherever a website’s origin server may live, a CDN lets users connect to a geographically closer data center. Less travel time means faster service.
- Hardware and software optimizations such as efficient load balancing and solid-state hard drives can help data reach the user faster.
- CDNs can reduce the amount of data that’s transferred by reducing file sizes using tactics such as minification and file compression. Smaller file sizes mean quicker load times.
- CDNs can also speed up sites which use TLS/SSL certificates by optimizing connection reuse and enabling TLS false start.
Reliability and Redundancy - How does a CDN keep a website always online?
Uptime is a critical component for anyone with an Internet property. Hardware failures and spikes in traffic, as a result of either malicious attacks or just a boost in popularity, have the potential to bring down a web server and prevent users from accessing a site or service. A well-rounded CDN has several features that will minimize downtime:
- Load balancing distributes network traffic evenly across several servers (Load balancing evenly), making it easier to scale rapid boosts in traffic.
- Intelligent failover provides uninterrupted service even if one or more of the CDN servers go offline due to hardware malfunction; the failover can redistribute the traffic (可以redistribute traffic 到背的server) to the other operational servers.
- In the event that an entire data center is having technical issues, Anycast routing transfers the traffic to another available data center (如果一个data center 有问题,transfer 到另外一个), ensuring that no users lose access to the website.
Data Security - How does a CDN protect data?
Information security is an integral part of a CDN. a CDN can keep a site secured with fresh TLS/SSL certificates which will ensure a high standard of authentication, encryption, and integrity. Investigate the security concerns surrounding CDNs, and explore what can be done to securely deliver content. Learn about CDN SSL/TLS security
Data Partitioning
Data partitioning is a technique to break a big database (DB) into many smaller parts. It is the process of splitting up a DB/table across multiple machines to improve the manageability, performance, availability, and load balancing of an application. The justification for data partitioning is that, after a certain scale point, it is cheaper and more feasible to scale horizontally by adding more machines than to grow it vertically by adding beefier servers.
1. Partitioning Methods#
Horizontal Partitioning: In this scheme, we put different rows into different tables. For example, if we store different places in a table, we can decide that locations with ZIP codes less than 10000 are stored in one table and places with ZIP codes greater than 10000 are stored in a separate table. This is also called range-based Partitioning as we are storing different ranges of data in separate tables. Horizontal Partitioning is also known as Data Sharding.
The key problem with this approach is that if the value whose range is used for Partitioning isn’t chosen carefully, then the partitioning scheme will lead to unbalanced servers. In the previous example, splitting locations based on their zip codes assume that places will be evenly distributed across the different zip codes. This assumption is not valid as there will be a lot of places in a thickly populated area like Manhattan as compared to its suburb cities.
Vertical Partitioning: