Distributed Data
- Scalability:If your data volume, read load, or write load grows bigger than a single machine can handle, you can potentially spread the load across multiple machines.
- Fault tolerance/high availability: continue working even if one machine (or several machines, or the network, or an entire datacenter) goes down, you can use multiple machines to give you redundancy. When one fails, another one can take over (一个machine off,其他可以用上)
-
Latency: If you have users around the world, you might want to have servers at various locations worldwide so that each user can be served from a datacenter that is geographically close to them. That avoids the users having to wait for network packets to travel halfway around the world (让用户access离的最近的datacenter)
- Vertical Scaling(scaling up): buy more powerful machine,更多的CPU, RAM, Disk
- shared-memory architecture: all the compoents can be treated as a single machine
- cost grows faster than linearly: a machine with twice as many CPUs, twice as much RAM, and twice as much disk capacity as another typically costs significantly more than twice as much
- shared-disk architecture, which uses several machines with independent CPUs and RAM, but stores data on an array of disks that is shared between the machines, which are connected via a fast network.
- used for some data warehousing workloads, but contention and the overhead of locking limit the scalability of the shared-disk approach
- horizontal scaling, scaling out,shared-nothing architectures:
- each machine or virtual machine running the database software is called a node.
- Each node uses its CPUs, RAM, and disks independently. Any coordination between nodes is done at the software level, using a conventional network
- can use whatever machines have the best price/performance ratio
- potentially distribute data across multiple geographic regions, and thus reduce latency for users and potentially be able to survive the loss of an entire datacenter
Replication Versus Partitioning
- Replication: Replication provides redundancy: if some nodes are unavailable, the data can still be served from the remaining nodes
- Partitioning: Splitting a big database into smaller subsets called partitions so that different partitions can be assigned to different nodes (also known as sharding)
Replication
several reasons why you might want to replicate data
- To keep data geographically close to your users (and thus reduce latency)
- To allow the system to continue working even if some of its parts have failed (and thus increase availability)
- To scale out the number of machines that can serve read queries
3种: single-leader, multi-leader, and leaderless replication
Leader and Followers
replica: each nodes that stores a copy of the database
leader-based aopplication:
- One of the replicas is designated the leader (also known as master or primary). When clients want to write to the database, they must send their requests to the leader, which first writes the new data to its local storage.
- The other replicas are known as followers (read replicas, slaves, secondaries, or hot standbys).i Whenever the leader writes new data to its local storage, it also sends the data change to all of its followers as part of a replication log or change stream. Each follower takes the log from the leader and updates its local copy of the database accordingly, by applying all writes in the same order as they were processed on the leader
- When a client wants to read from the database, it can query either the leader or any of the followers. However, writes are only accepted on the leader (the followers are read-only from the client’s point of view) 读可以从leader or follower但写必须是leader
- A built-in feature of many relational databases, such as PostgreSQL, MySQL, Oracle, SQL Server. Aslo used in some nonrelational database, including MongoDB, RethinkDB and Espresso.
Synchronous Versus Asynchronous Replication
- synchronous: the leader
waits until all followers have confirmed that it received the write before reporting success to the user, and before making the write visible to other clients
- Advantage: follower is guaranteed to have an up-to-date copy of the data that is consistent with the leader. If the leader suddenly fails, we can be sure that the data is still available on the follower (保证all followers 跟leader有一样的data, 如果leader fails, data still available on follower)
- Disadvantage: if the synchronous follower doesn’t respond (because it has crashed, or there is a network fault, or for any other reason), the write cannot be processed. The leader must block all writes and wait until the synchronous replica is available again (如果follower 不respond, leader会被blocker)
- Impractical: any one node outage would cause the whole system to grind to a halt (一个follower坏掉,整个system halt)
- asynchronous: the leader sends the message, but doesn’t wait for a response from the follower
- no guarantee of how long it might take. There are circumstances when followers might fall behind the leader by several minutes or more; for example, if a follower is recovering from a failure, if the system is operating near maximum capacity, or if there are network problems between the nodes.
- leader-based replication is configured to be completely asynchronous:if the leader fails and is not recoverable, any writes that have not yet been replicated to followers are lost. 如果leader fail,any writes 还没到replicas就丢失了
- Advantage: leader can continue processing writes, even if all of its followers have fallen behind. leader 可以一直processing 即使follower failed
- semi-synchronous: 一个node sync 其他node async
- If the synchronous follower becomes unavailable or slow, one of the asynchronous followers is made synchronous 当sync的node变慢或者不available, 其他async变成sync
Setup New Followers
- Simply copying data files from one node to another is typically not sufficient: clients are constantly writing to the database, and the data is always in flux, so a standard file copy would see different parts of the database at different points in time.
- Could make the files on disk consistent by locking the database (making it unavailable for writes), but go against our goal of high availability
- process looks like this:
- Take a consistent snapshot of the leader’s database at some point in time—if possible, without taking a lock on the entire database. Most databases have this feature, as it is also required for backups. In some cases, third-party tools are needed, such as innobackupex for MySQL
- Copy the snapshot to the new follower node
- The follower connects to the leader and requests all the data changes that have happened since the snapshot was taken. This requires that the snapshot is associated with an exact position in the leader’s replication log. That position has various names: for example, PostgreSQL calls it the log sequence number, and ySQL calls it the binlog coordinates.
- When the follower has **processed the backlog of data changes since the snapshot **we say it has caught up. It can now continue to process data changes from the leader as they happen
Follower failure
Being able to reboot individual nodes without downtime is a big advantage for operations and maintenance. Thus, our goal is to keep the system as a whole running despite individual node failures, and to keep the impact of a node outage as small as possible.
- On its local disk, each follower keeps a log of the data changes it has received from the leader. 每一个follower都有来自leader的data changes log.
- If a follower crashes and is restarted, or if the network between the leader and the follower is temporarily interrupted, the follower can recover quite easily: from its log, it knows the last transaction that was processed before the fault occurred.
- Thus, the follower can connect to the leader and request all the data changes that occurred during the time when the follower was disconnected. When it has applied these changes, it has caught up to the leader and can continue receiving a stream of data changes as before. (follower知道crash上一个transaction, 去leader那里去要)
Leader failure: Failover
one of the followers needs to be promoted to be the new leader, clients need to be reconfigured to send their writes to the new leader, and the other followers need to start consuming data changes from the new leader. This process is called failover 一个follower变成leader,client需要reconfigure 发送到新leader 其他follower consume data from new leaders
failover consists of following steps:
- Determining that the leader has failed. Many things could potentially go wrong: crashes, power outages, network issues, and more. most systems simply use a timeout: nodes frequently bounce messages back and forth between each other, and if a node doesn’t respond for some period of time—say, 30 seconds—it is assumed to be dead. (If the leader is deliberately taken down for planned maintenance, this doesn’t apply.)
- Choosing a new leader. This could be done through an election process (where the leader is chosen by a majority of the remaining replicas), or a new leader could be appointed by a previously elected controller node. The best candidate for leadership is usually the replica with the most up-to-date data changes from the old leader (to minimize any data loss) 选一个最up-to-date 来减少data loss
- Reconfiguring the system to use the new leader. Clients now need to send their write requests to the new leader . If the old leader comes back, it might still believe that it is the leader, not realizing that the other replicas have forced it to step down. The system needs to ensure that the old leader becomes a follower and recognizes the new leader. 需要reconfig 新的leader 让old leader变成follower
Failover is fraught with things that can go wrong:
- aysnc: new leaeder may not received all writes from old leader before it failed. 如果old leader rejoin after new leader chosen -> conflit. The most common solution for old leader’s unreplicated writes to simply be discarded, which violates clients’ durability expectation.
- Discarding writes is especially dangerous if other storage systems outside of the database need to be coordinated with the database content.
- For example, in one incident at GitHub [13], an out-of-date MySQL follower was promoted to leader. The database used an autoincrementing counter to assign primary keys to new rows, but because the new leader’s counter lagged behind the old leader’s, it reused some primary keys that were previously assigned by the old leader. These primary keys were also used in a Redis store, so the reuse of primary keys resulted in inconsistency between MySQL and Redis, which caused some private data to be disclosed to the wrong users.
- 一些 fault scenarios, it could happen that two nodes both believe that they are the leader. This situation is called split brain, and it is dangerous: if both leaders accept writes, and there is no process for resolving conflicts, data is likely to be lost or corrupted. As a safety catch, some systems have a mechanism to shut down one node if two leaders are detected. However, if this mechanism is not carefully designed, you can end up with both nodes being shut down (两个node 都说他们是leader, 叫做split brain, 最常见的方法是关闭一个node,但有可能两个都关了)
- What is the right timeout before the leader is declared dead? A longer timeout means a longer time to recovery in the case where the leader fails. However, if the timeout is too short, there could be unnecessary failovers. 更长的timeout 表示更久leader fail, 更长recover 如果timeout too short, uncessary failovers
- For example, a temporary load spike could cause a node’s response time to increase above the timeout, or a network glitch could cause delayed packets. If the system is already struggling with high load or network problems, an unnecessary failover is likely to make the situation worse, not better
- There are no easy solutions to these problems. For this reason, some operations teams prefer to perform failovers manually, even if the software supports automatic failover
Implementation of Replication Logs
- Statement-based replication: In the simplest case, the leader logs every write request (statement) that it executes and sends that statement log to its followers. leader 把每个write request 都发给followers
- For SQL, every INSERT, UPDATE, or DELETE statement is forwarded to followers, and each follower parses and executes that SQL statement as if it had been received from a client
- Some problems:
- nondeterministic function, such as
NOW()to get the current date and time orRAND()to get a random number, is likely to generate a different value on each replica - 一些autoincremetning column depend on the existing data in the database (e.g., UPDATE … WHERE
), they must be executed in exactly the same order on each replica, or else they may have a different effect. This can be **limiting when there are multiple concurrently executing transactions**. (一些autoincrementing column 必须execute on the same order) - Statements that have side effects (e.g., triggers, stored procedures, user-defined functions) may result in different side effects occurring on each replica, unless the side effects are absolutely deterministic
- nondeterministic function, such as
- Usage: Statement-based replication was used in MySQL before version 5.1. It is still sometimes used today, as it is quite compact, but by default MySQL now switches to rowbased replication (discussed shortly) if there is any nondeterminism in a statement. VoltDB uses statement-based replication, and makes it safe by requiring transactionsto be deterministic
- Write-ahead log (WAL) shipping:
- Log-structured storage or B-tree append -only sequence of bytes containing all writes to the database. 可以exact same log to build replica on another node.
- besides writing the log to disk, the leader also sends it across the network to its followers. When the follower processes this log, it builds a copy of the exact same data structures as found on the leader
- Disadvantage:log describes the data on a very low level
- makes replication closely coupled to the storage engine. If the database changes its storage format, typically not possible to run different versions of the database software on the leader and the followers 如果database change format 不能run 两种在leader和follower
- 听起来minor implementation, big impact, 如果follower可以有different version than leader, 可以 zero-downtime upgrade of database by first upgrading followers 再performing a failover to 让其中一个follower变成leader. 如果replication protocol does not allow version mismatch -> 这种upgrades 需要downtime
- Logical (row-based) log replication:use different log formats for replication and for the storage engine, whichallows the replication log to be decoupled from the storage engine internals. This kind of replication log is called a logical log, to distinguish it from the storage engine’s (physical) data representation
- A logical log for a relational database is usually a sequence of records describing writes to database tables at the granularity of a row:
- For an inserted row, the log contains the new values of all columns.
- For a deleted row, the log contains enough information to uniquely identify the row that was deleted. Typically this would be the primary key, but if there is no primary key on the table, the old values of all columns need to be logged
- For an updated row, the log contains enough information to uniquely identify the updated row, and the new values of all columns (or at least the new values of all columns that changed).
- a logical log is decoupled from the storage engine internals, it can more easily be kept backward compatible
- easier for external applications to parse
- A logical log for a relational database is usually a sequence of records describing writes to database tables at the granularity of a row:
- Log-structured storage or B-tree append -only sequence of bytes containing all writes to the database. 可以exact same log to build replica on another node.
- Trigger-based replication:上面都没有involve application code, 但有时候want only a subset of data, replicate from one kind of database to another -> move replication up to the application layer.
- Some tools, such as Oracle GoldenGate [19], can make data changes available to an application by reading the database log
- A trigger lets you register custom application code that is automatically executed when a data change (write transaction) occurs in a database system.
- log this change into a separate table. read by external process. External process can apply 任何application logic and replicate the data change to another system.
- has overheads than other method, 更prone to bug
Problems with Replication Lag
read-scaling architecture: increase the capacity for serving read-only requests simply by adding more followers. 只work for async, 如果sync, 一个follower failure or network outage -> make entire system unavailable for writing. -> more nodes, 越unreliable
如果application read from aync follower, 也许outdated information. inconsistencies in the database. if you stop writing to the database and wait a while, the followers will eventually catch up and become consistent with the leader. the delay between a write happening on the leader and being reflected on a follower—the replication lag. 大概几秒not noticable
Reading Your Own Writes
- async, if the user views the data shortly after making a write, the new data may not yet have reached the replica.
- we need read-after-write consistency, also known as read-your-writes consistency. This is a guarantee that if the user reloads the page, they will always see any updates they submitted themselves. It makes no promises about other users.
How to implement?
- When reading something that the user may have modified, read it from the
leader; otherwise, read it from a follower. 需要一定机制know whether modified
- 比如, user profile on social network, 只能owner 修改,a simple rule: always rad the user’s own profile from the leader, any other users’ profile from a follower
- make all reads from the leader. 比如 monitor the replication lag on followers and prevent queries on any follower that is more than one minute behind the reader.
- client can remember the timestamp of most recent write - system can ensure that the replica serving any reads fro that user reflects updates at tleast until that timestamp. 如果replica not up to date, either the read can be handled by another replica or query can wait unitl the replica has caught up. timestamp 可以是logical timestamp or actual system clock
- 如果 replicas distributed across multiple datacenters, additonal complexity, Any request that needs to be served by the leader must routed to the datacenter that contains the leader
cross-device read-after-write consistency: 比如desktop write, view it on another device.If your replicas are distributed across different datacenters, there is no guarantee that connections from different devices will be routed to the same datacenter. 如果replica 是不同的datacenter, 不能保证connection from different device route to the same datacenter
Monotonic reads: they will not read older data after having previously read newer data.
consistent prefix reads. This guarantee says that if a sequence of writes happens in a certain order, then anyone reading those writes will see them appear in the same order. One solution is to make sure that any writes that are causally related to each other are written to the same partition
Multiple-Leader Replication
- allow more than one node to accept writes (multi-leader configuration, also known as master–master or active/active replication)
- Replication still happens in the same way: each node that processes a write must forward that data change to all the other nodes.
- Multi-datacenter operation. 非常rare只有一个datacenter. have a leader in each datacenter
- Within each datacenter, regular leader-follower replication is used; between datacenters, each datacenter’s leader replicates its changes to the leaders in other datacenters.
- Performance:In a single-leader configuration, every write must go over the internet to the datacenter with the leader. This can add significant latency to writes and might contravene the purpose of having multiple datacenters in the first place. In a multi-leader configuration, every write can be processed in the local datacenter and is replicated asynchronously to the other datacenters. Thus, the inter-datacenter network delay is hidden from users, which means the perceived performance may be better
- Tolerance of datacenter outages:each datacenter can continue operating independently of the others, and replication catches up when the failed datacenter comes back online (每个datacenter 都是相互独立的,replication 可以catches up when failed, datacenter可以come back oneline)
- Tolerance of network problems:
- Traffic between datacenters usually goes over the public internet, which may be less reliable than the local network within a datacenter
- A single-leader configuration is very sensitive to problems in this inter-datacenter link. (Single-leader 是非常容易受到inter-datacenter link影响的, 因为write sync over this link)
- A multi-leader configuration with asynchronous replication can usually tolerate network problems better: a temporary network interruption does not prevent writes being processed (暂时的network interruption 不会影响writes being processed)
- Multiple leader database 例子: Tungsten Replicator for MySQL [26], BDR for PostgreSQL [27], and GoldenGate for Oracle
- disadvantage: the same data may be concurrently modified in two different datacenters, and those write conflicts must be resolved
- autoincrementing keys, triggers, and integrity constraints can be problematic. For this reason, multi-leader replication is often considered dangerous territory that should be avoided if possible
需要multi-leader replication if you have an application that needs to continue to work while it is disconnected from the internet. 比如电脑,手机操作是sync的, every device has a local database that acts as a leader -> extremely unreliable
Google doc 多个人editing. changes are instantly applied to their local replica (the state of the document in their web browser or client application) and asynchronously replicated to the server and any other users who are editing the same document. If you want to guarantee that there will be no editing conflicts, the application must obtain a lock on the document before a user can edit it. If another user wants to edit the same document, they first have to wait until the first user has committed their changes and released the lock
Handling Write Conflicts
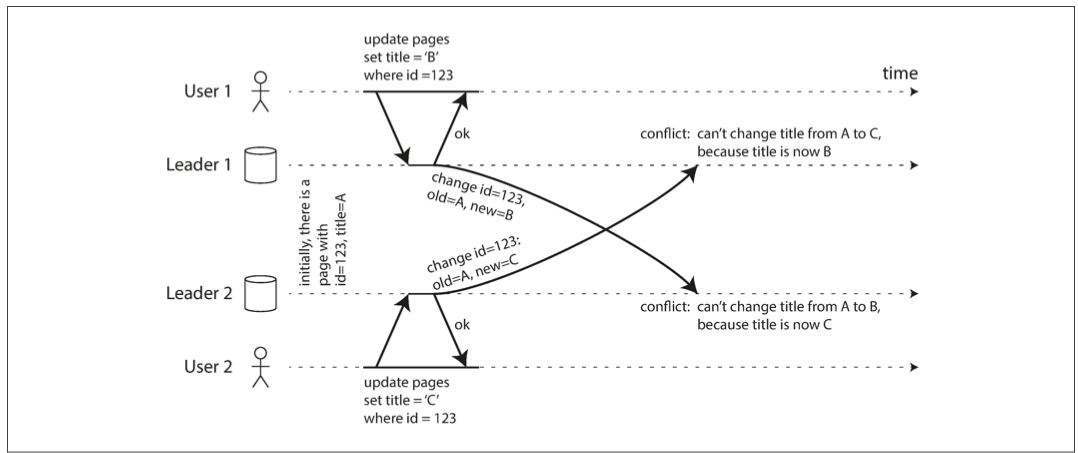
- In a single-leader database, the second writer will either block and wait for the first write to complete, or abort the second write transaction, forcing the user to retry the write. (第二个会等第一个完成)
- in a multi-leader setup, both writes are successful, and the conflict is only detected asynchronously at some later point in time (不会有conflict)
- avoid conflict 最简单的办法: all writes for a particular record go through the same leader, then conflicts cannot occur
- 有时候要change designated leader 因为datacenter failed, 需要reroute traffic to another datacenter 或者 a user move to a different location 现在close to a different datacenter. 这种情况, have to deal with the possibility of concurrent writes on different leaders
几种方式resolve conflict
- Give each write a unique ID, 最高ID as the winner
- If timestamp is used, last write wins (可能会有data loss)
- 给每个replica 一个ID, writes that originated at a higher numbered replica always take precendence over writes that originated at a lower-numbered replica. => implies data loss
- Somehow merge the values together—e.g., order them alphabetically and then concatenate them
- Record the conflict in an explicit data structure that preserves all information,and write application code that resolves the conflict at some later time
Custom conflict resolution logic
- On write: detects a conflict in the log of replicated changes, it calls the conflict handler. This handler typically cannot prompt a user—it runs in a background process and it must execute quickly
- On read: The application may prompt the user or automatically resolve the conflict, and write the result back to the database.比如 CouchDB
Multi-Leader Replication Topologies
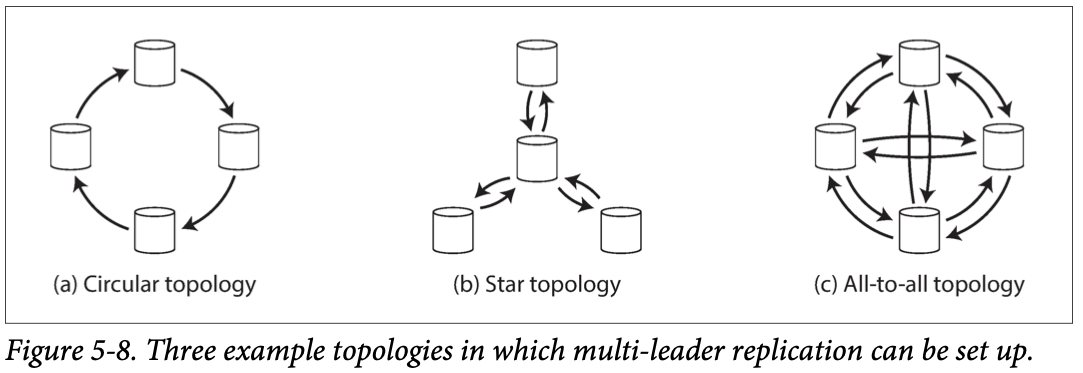
- all-to-all: every leader sends its writes to every other leader.
- 与star和circular相比 没有single points of failure
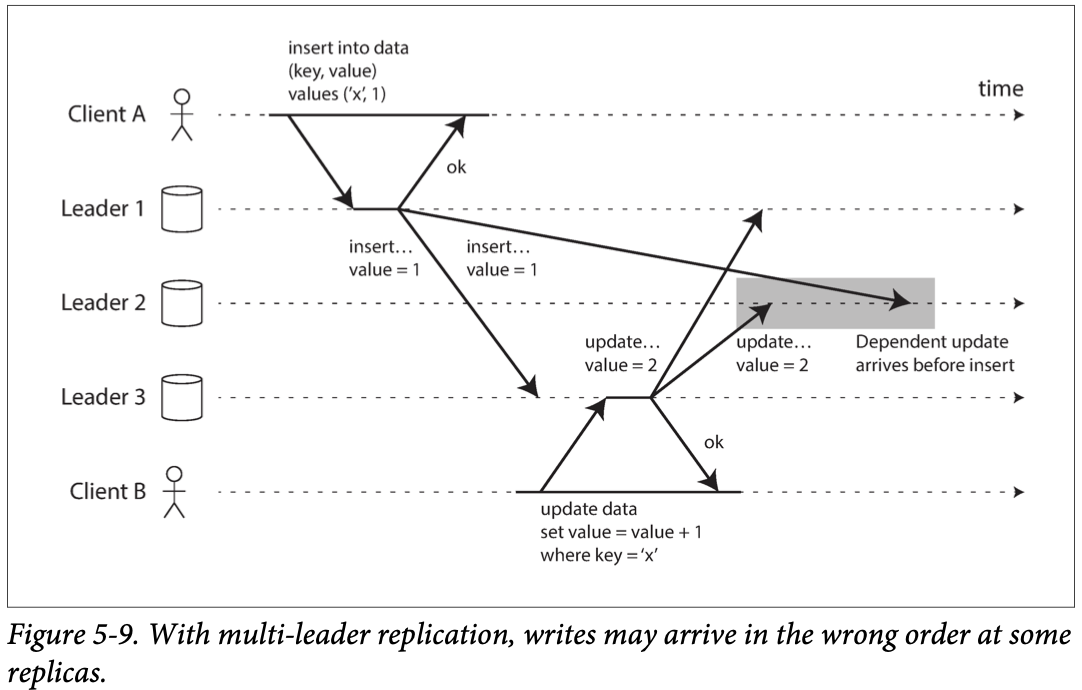
- 但也有问题, ome network links may be faster than others (e.g., due to network congestion), with the result that some replication messages may “overtake” others, as illustrated in 图。leader 2 收到writes in different order
- Consistent Prefix Reads: 需要make sure insert first then update. Simply use timestamp 不行,因为clock cannot be trusted to be sufficiently in sync to correctly order these events at leaders
- circular topology [34], in which each node receives writes from one node and forwards those writes (plus any writes of its own) to one other node.
- To prevent infinite replication loops, each node is given a unique identifier, and in the replication log, each write is tagged with the identifiers of all the nodes it has passed through
- a star:v one designated root node forwards writes to all of the other nodes
A problem with circular and star topologies is that if just one node fails, it can interrupt the flow of replication messages between other nodes, causing them to be unable to communicate until the node is fixed (对于circular 和star, 一个node 坏了可能影响着其他的node)。 The topology could be reconfigured to work around the failed node, but in most deployments such reconfiguration would have to be done manually
Leaderless Replication
Dynamo system (Amazon). Riak, Cassandra, and Voldemort are open source datastores with leaderless replication models inspired by Dynamo, so this kind of database is also known as Dynamo-style
In some leaderless implementations, the client directly sends its writes to several replicas, while in others, a coordinator node does this on behalf of the client. However, unlike a leader database, that coordinator does not enforce a particular ordering of writes (client 直接发给replicas, coordinator node 做这个behalf of client, 不像leader database, coordinator 不会enforce a particular ordering of writes)
failover:
- leader-based configure, 想processing writes, perform a failover
- leaderless configuration. failover 不存在
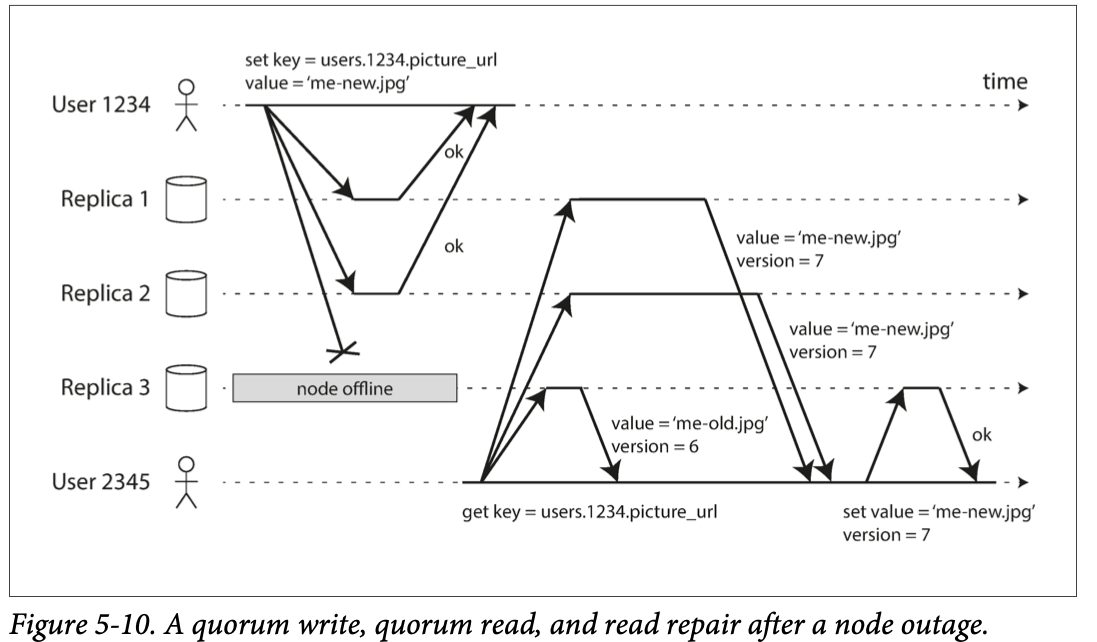
replica 3 miss the write. 当replica 3 back online, 可能有stale data. read requests are also sent to several nodes in parallel. The client may get different responses from different nodes; i.e., the up-to-date value from one node and a stale value from another. Version numbers are used to determine which value is newer.
Read repair and anti-entropy
- Read repair: 比如user read version 1 and 3 from replica 1 and 2. see replica 3 has a stale value, and writes the newer value back to that replica.
- Anti-entropy process: some datastore have a background process 持续看differences in the data between replicas and copies any missing data from one replica to another.
- this anti-entropy process does not copy writes in any particular order, and there maybe a significant delay before data is copied
If there are n replicas, every write must be confirmed by w nodes to be considered successful, and we must query at least r nodes for each read. (In our example, n = 3, w = 2, r = 2.) As long as w + r > n, we expect to get an up-to-date value when reading, because at least one of the r nodes we’re reading from must be up to date. Reads and writes that obey these r and w values are called quorum reads and writes. You can think of r and w as the minimum number of votes required for the read or write to be valid.
In Dynamo-style databases, the parameters n, w, and r are typically configurable. A common choice is to make n an odd number (typically 3 or 5) and to set w = r = (n + 1) / 2 (rounded up)
For example, a workload with few writes and many reads may benefit from setting w = n and r = 1. This** makes reads faster, but has the disadvantage that just one failed node causes all database writes to fail 设置w, n ,r 都是1, 可以make read faster 但是single point of failure**.
w+r>n, exepect every read to return the most recent value written for a key, because the set of nodes to which you’ve written and the set of nodes from which you’ve read must overlap 因read 和write 一定会重合一些node
- If w < n, we can still process writes if a node is unavailable.
- If r < n, we can still process reads if a node is unavailable.
- With n = 3, w = 2, r = 2 we can tolerate one unavailable node.
- With n = 5, w = 3, r = 3 we can tolerate two unavailable nodes
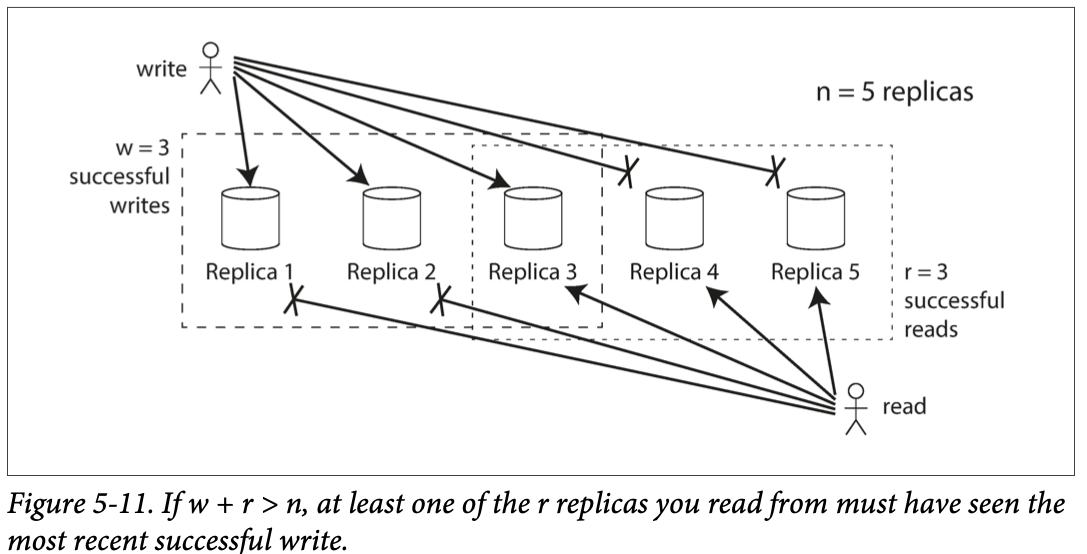
If fewer than the required w or r nodes are available, writes or reads return an error. A node could be unavailable for many reasons: because the node is down (crashed, powered down), due to an error executing the operation (can’t write because the disk is full), due to a network interruption between the client and the node, or for any number of other reasons
Often, r and w are chosen to be a majority (more than n/2) of nodes, because that ensures w + r > n while still tolerating up to n/2 node failures.
may also set w and r to smaller numbers, so that w + r ≤ n (i.e., the quorum condition is not satisfied). In this case, reads and writes will still be sent to n nodes, but a smaller number of successful responses is required for the operation to succeed
- return stale value
- allow lower latency and higher availability
- if there is a network interruption and many replicas become unreachable, there’s a higher chance that you can continue processing reads and writes. Only after the number of reachable replicas falls below w or r does the database become unavailable for writing or reading, respectively
但是 即使 w + r > n 也有edge cases where stale values are returned
- If a sloppy quorum is used, the w writes may end up on different nodes than the r reads, so there is no longer a guaranteed overlap between the r nodes and the w nodes
- If two writes occur concurrently, it is not clear which one happened first. In this case, the only safe solution is to merge the concurrent writes, If a winner is picked based on a timestamp (last write wins), writes can be lost due to clock skew
- If a write happens concurrently with a read, the write may be reflected on only some of the replicas. In this case, it’s undetermined whether the read returns the old or the new value
- If a write succeeded on some replicas but failed on others (for example because the disks on some nodes are full), and overall succeeded on fewer than w replicas, it is not rolled back on the replicas where it succeeded. This means that if a write was reported as failed, subsequent reads may or may not return the value from that write
- If a node carrying a new value fails, and its data is restored from a replica carrying an old value, the number of replicas storing the new value may fall below w, breaking the quorum condition 一个node fail 从old replica 恢复,可能没有新的数据
- Even if everything is working correctly, there are edge cases in which you can get unlucky with the timing
Dynamo-style databases are generally optimized for use cases that can tolerate eventual consistency.
Monitoring staleness
- because writes are applied to the leader and to followers in the same order, and each node has a position in the replication log. By subtracting a follower’s current position from the leader’s current position, you can measure the amount of replication lag.
- Leaderless Replication, there is no fixed order in which writes are applied, which makes monitoring more difficult.
- 如果only use only uses read repair (no anti-entropy), there is no limit to how old a value might be f a value is only infrequently read, the value returned by a stale replica may be ancient.
Sloppy Quorums and Hinted Handoff
- 如果有internet issue, a client that is cut off from the database nodes, they might aslo dead. 很有可能少于w or r个 reachable nodes remain, client no longer reach a quorum.
- Sloppy quorum: accept writes anyway, write them to some nodes that are reachable but aren’t among the n nodes on which the value usually lives
- writes and reads still require w and r successful responses, but those may include nodes that are not among the designated n “home” nodes for a value. 比如你家被锁了,在邻居家暂住一下
- Once the network interruption is fixed, any writes that one node temporarily accepted on behalf of another node are sent to the appropriate “home” nodes 当internet 恢复,the node tempoarily accepted write 被发到原来属于的nodes
- Sloppy quorums are particularly useful for increasing write availability: as long as any w nodes are available, the database can accept writes. However, this means that even when w + r > n, you cannot be sure to read the latest value for a key, because the latest value may have been temporarily written to some nodes outside of n
- a sloppy quorum actually isn’t a quorum at all in the traditional sense. It’s only an assurance of durability, namely that the data is stored on w nodes somewhere. There is no guarantee that a read of r nodes will see it until the hinted handoff has completed
Detecting Concurrent Writes
events may arrive in a different order at different nodes, due to variable network delays and partial failures
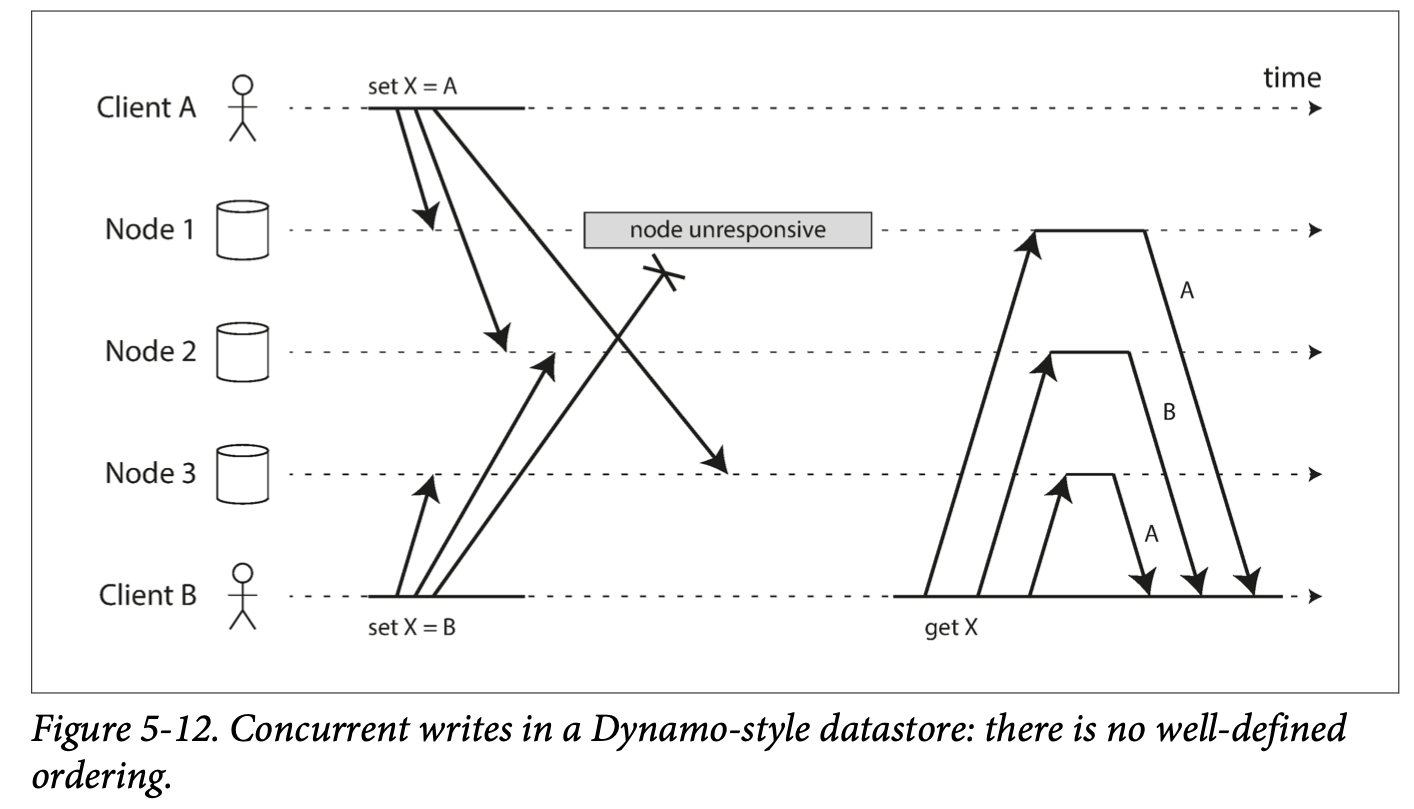
- Node 1 receives the write from A, but never receives the write from B due to a transient outage.
- Node 2 first receives the write from A, then the write from B.
- Node 3 first receives the write from B, then the write from A.
If each node simply overwrote the value for a key whenever it received a write request from a client, the nodes would become permanently inconsistent. 如果一个node 只是简单的接受一个node, node变得inconsistent
Last write wins (discarding concurrent writes) conflict resolution method in Cassandra
- One approach for achieving eventual convergence is to declare that each replica need only store the most “recent” value and allow “older” values to be overwritten and discarded
- 只要有一种方式决定什么是more recent, every writes is eventually copied to every replica, the replicas will 最终converge to the same value
- at the cost of durability:
- several concurrent writes to the same key, even if they were all reported as successful to the client (because they were written to w replicas), only one of the writes (多个write,可能都返回给client成功,最后很有可能只有一个成功) will survive and the others will be silently discarded
- LWW may drop writes that are not concurrent
- only safe way of using a database with LWW is to ensure that a key is only written once and thereafter treated as immutable, thus avoiding any concurrent updates to the same key
Concurrent 表示没有causal dependency. casual dependency 比如 set value = 1, 第二个operation是 value = value + 1, 如果没有value 就不能到第二步
whenever you have two operations A and B, there are three possibilities: either A happened before B, or B happened before A, or A and B are concurrent.
For defining concurrency, exact time doesn’t matter. we simply call two operations concurrent if they are both unaware of each other, regardless of the physical time at which they occurred
algorithm: use version number
- The server maintains a version number for every key, increments the version number every time that key is written, and stores the new version number along with the value written.
- When a client reads a key, the server returns all values that have not been over‐ written, as well as the latest version number. A client must read a key before writing. client必须 reads a key before writing
- When a client writes a key, it must include the version number from the prior read, and it must merge together all values that it received in the prior read. (The response from a write request can be like a read, returning all current values, which allows us to chain several writes like in the shopping cart example.) 当client writes a key, 必须include the version number 从之前的read, 必须merge all values that it received by prior read
- When the server receives a write with a particular version number, it can over‐ write all values with that version number or below (since it knows that they have been merged into the new value), but it must keep all values with a higher version number (because those values are concurrent with the incoming write). 当server 收到一个write with version, 必须overwrite all values <= 它的version number, keep all values with a higher version number
- 如果是remove, take the union may not yield the right result.
- an item cannot simply be deleted from the database when it is removed; instead the system must leave a marker with an appropriate version number to indicate that the item has been removed when merging siblings. Such a deletion marker is known as a tombstone
- use a version number per replica as well as per key. Each replica increments its own version number when processing a write, and also keeps track of the version numbers it has seen from each of the other replicas. 每一个replica的每个key 都有一个version number
- The version vector allows the database to distinguish between overwrites and concurrent writes. version vector 用来区分是overwrites 还是concurrent writes
- 确保了safe to read from one replica and subsequently write back to another replica
Partition
partitions are defined in such a way that each piece of data (each record, row, or document) belongs to exactly one partition.
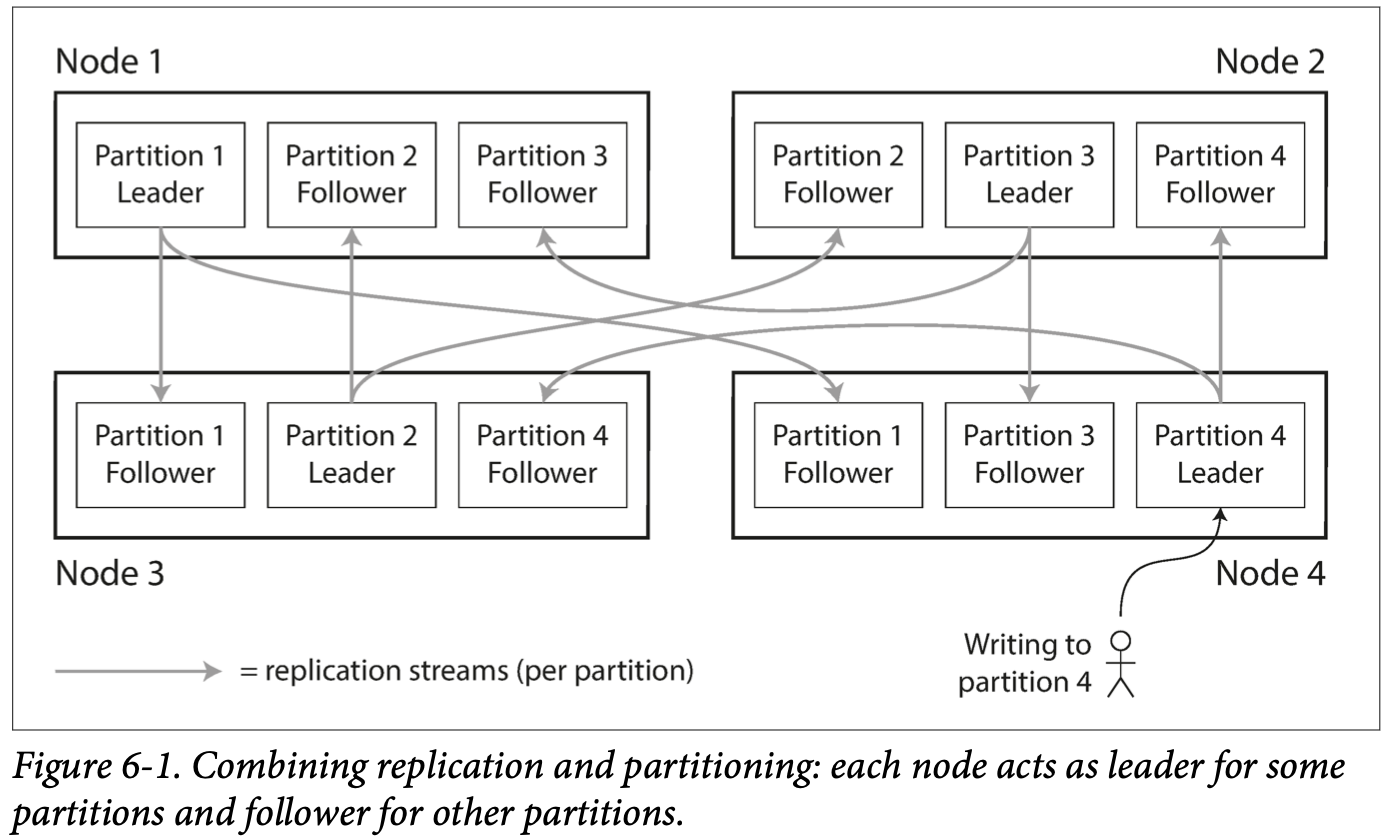
Main reason for wanting to partition data is scalability. Partition usually combine with replication. 表示即使each record belongs to exactly one partition, it may still be stored on several different nodes for fault tolerance.
A node may store than one partition. 如果leader-follower replication model is used, combination of parittiong and replication can look like below. Each partitions’s leader is assigned to one node, and its followers are assigned to other nodes. 每个node maybe the leader for some partitions and a follower for other parition
skewed: if partition is unfair, some partitions have more data or queries than others. Skewed 出现makes partitiong much less effective. A partition with disproportionately high load is called a hot spot.
避免hot spot最简单的方法就是assign records to nodes randomly, 有disadvantage: 当read a particular item, have no way of knowing which node it is on, 必须query all nodes in parallel.
Partitioning by Key Range
assign a continuous range of keys (从最小到最大) to each partition, 像百科全书一样. If you know the boundaries bewteen ranges, can easily determin which partion contains a given key. 如果知道which partition is assigned to which node, 可以make your request directly to the appropriate node.

simple having one volume per two letters of alphabet 导致 some volumes being much bigger than others. 为了distribute the data evenly, the parition boundaries need to adapt to the data.
the downside of key range partitioning is that certain access patterns can lead to hot spots
Partitioning by Hash of Key
Because of the risk of skew and hot spots, many distributed datastores 使用a hash function to determine the partition for a given key. A good hash function takes skewed data and make it uniformly distributed.
Once you have a suitable hash function for keys, you can assign each partition a range of hashes (rather than a range of keys), and every key whose hash falls within a partition’s range will be stored in that partition.

Consistent Hashing: is a way of evenly distributing load across an internet-wide system of caches such as a content delivery network (CDN). It randomly chosen partition boundaries to avoid the need for central control or distributed consensus. (consistent here has nothing to do with replica consistency or ACID consistency). Describes a particular approach to rebalancing.
Downside of hash: lose a nice property of key-range partition: do efficent range queries. Keys that were once adjacent are now scattered across all the partitions. sort order is lost.
Cassandra achieves a compromise between the two partitioning strategies. Cassandra can be declared with a compound primary key consisting of several columns. Only the first part of that key is hashed to determine the partition, but the other columns are used as a concatenated index for sorting the data in Cassandra’s SSTables. A query therefore cannot search for a range of values within the first column of a compound key, but if it specifies a fixed value for the first column, it can perform an efficient range scan over the other columns of the key. 第一个key决定partition, 第二个key 决定sorted order
比如Cassandra, primary key for update (user_id, update_timestamp). 可以efficiently retrieve all updates made by a particular user within some time interval, sorted by timestamp. 不同的user may be stored on different partitions, 但是within each user, updates are stored ordered by timestamp on a single partition
Skewed Workloads and Relieving Hot Spots
- 比如名人的twitter, application responsibility to reduce the skew. 比如一个key too hot, add a random number to hte beginning or end of the key. 比如两个random number 可以writs to the key evenly across 1000 different keys
- Read has addtional work. have to read the data from all 100 keys and combine it -> 需要additional bookkeeping. Only make sense to append the random number for small number of hot keys. 对于大多数keys with low write throughput, 将会是overhead.
- need trade-off for applicaiton
Partition by document 是 each partition holds a subset of the entire collection of documents. Partition by term (global indexing) 表示index itself is parititoned
Partitioning and Secondary Indexes
A secondary index usually doesn’t identify a record uniquely but rather is a way of searching for occurrences of a particular value
The problem with secondary indexes is that they don’t map neatly to partitions. There are two main approaches to partitioning a database with secondary indexes: document-based partitioning and term-based partitioning
Partitioning Secondary Indexes by Document
Each listing has a unique ID—call it the document ID—and you partition the database by the document ID
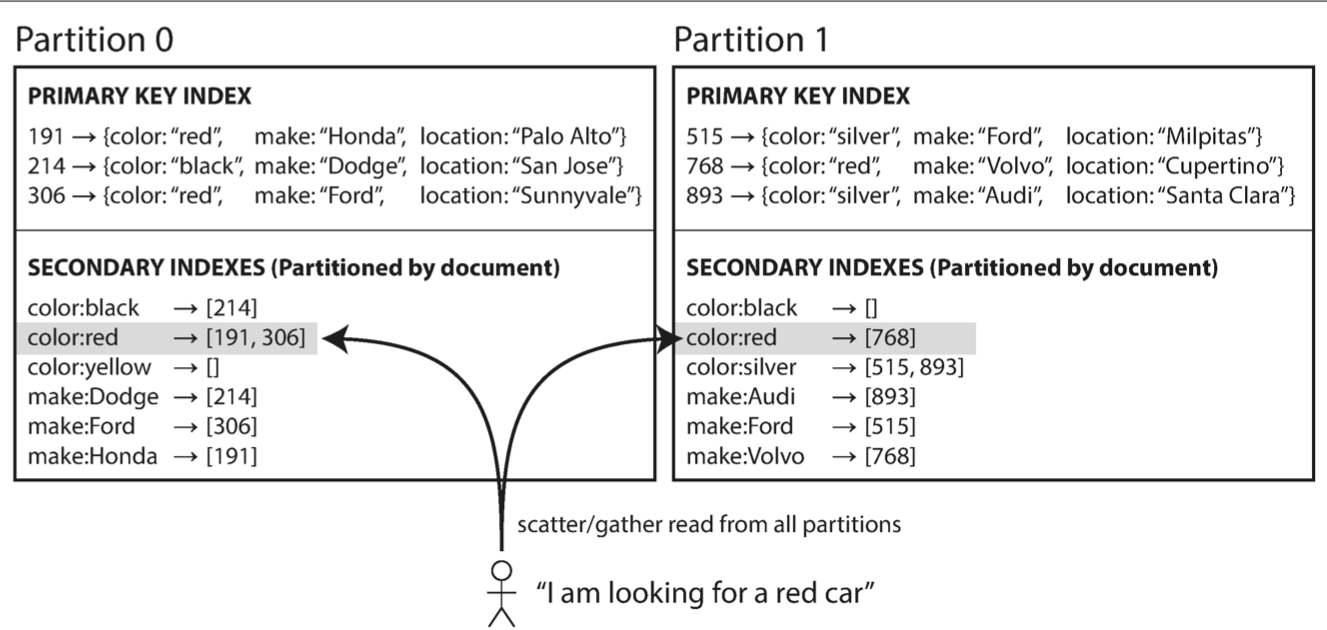
However, reading from a document-partitioned index requires care: unless you have done something special with the document IDs, there is no reason why all the cars with a particular color or a particular make would be in the same partition. In Figure 6-4, red cars appear in both partition 0 and partition 1. Thus, if you want to search for red cars, you need to send the query to all partitions, and combine all the results you get back
querying a partitioned database is sometimes known as scatter/gather, and it can make read queries on secondary indexes quite expensive. Even if you query the partitions in parallel, scatter/gather is prone to tail latency amplification. Querying partition database是expensive and latency
it is widely used: MongoDB, Riak, Cassandra, Elasticsearch, SolrCloud, and VoltDB all use document-partitioned secondary indexes
Partitioning Secondary Indexes by Term
Rather than each partition having its own secondary index (a local index), we can construct a global index that covers data in all partitions. 不能只存一个node, global index 必须也是partitioned, can be partitioned differently from the primary key index
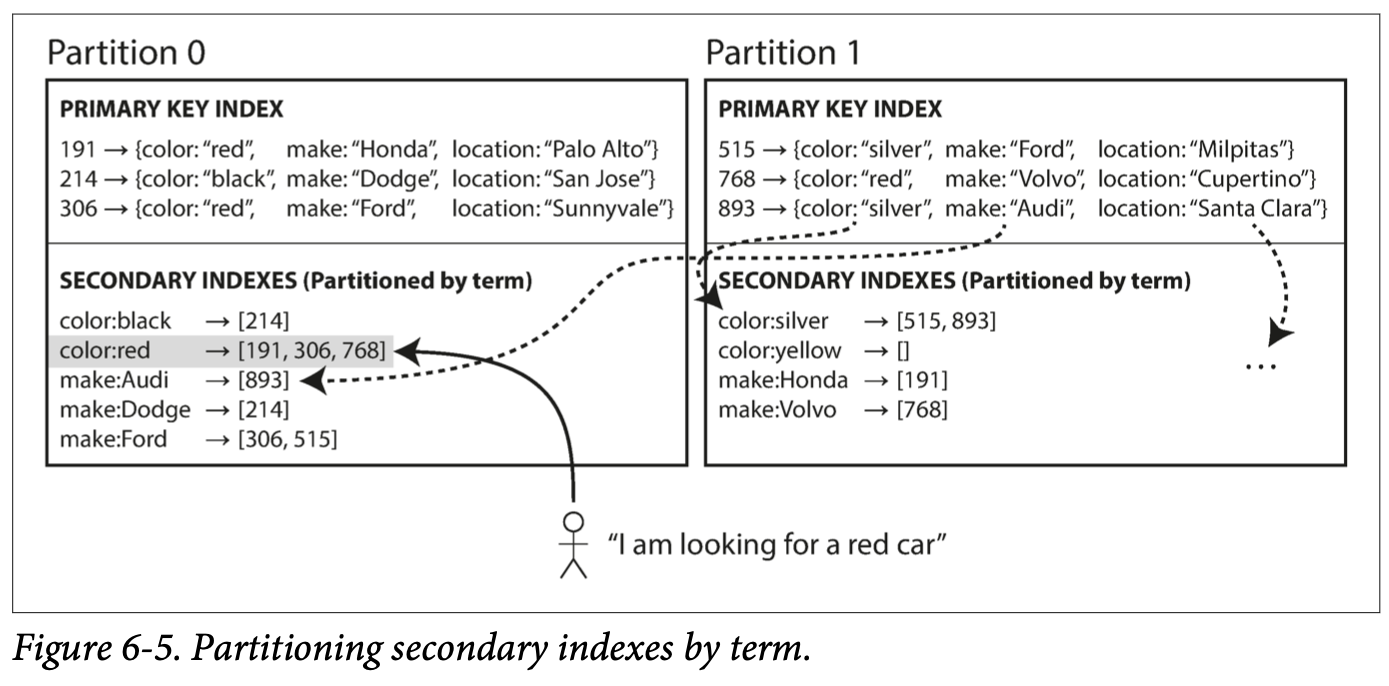
letter a-r 是partition 0, letter s-z 是 partition 1. called term-partitioned, because the term we’re looking for determines the partition of the index
Partitioning by the term itself can be useful for range scans (e.g., on a numeric property, such as the asking price of the car), whereas partitioning on a hash of the term gives a more even distribution of load. partition by term itself 用于range scans, partition on hash 给一个更even distribution of load
Advantage: over a document-partitioned, make reads more efficient (rather than doing scatter/gather over all partitions, a client only needs to make a request to the partition containing the term that it wants)
Downside: slower and complicated, a write to single document may affect multiple partitions of the index ((every term in the document might be on a different partition, on a different node) 因为每个term 可能在不同的partition
In an ideal world, the index would always be up to date, and every document written to the database would immediately be reflected in the index. However, in a term- partitioned index, that would require a distributed transaction across all partitions affected by a write, which is not supported in all databases
** updates to global secondary indexes are often asynchronous**
Rebalancing Partitions
Over time, things change in a database:
- The query throughput increases, so you want to add more CPUs to handle the load.
- The dataset size increases, so you want to add more disks and RAM to store it.
- A machine fails, and other machines need to take over the failed machine’s responsibilities
moving load from one node in the cluster to another is called rebalancing
rebalancing 需要 meet some minimum requirements:
- After rebalancing, the load (data storage, read and write requests) should be shared fairly between the nodes in the cluster. load需要平均分配
- While rebalancing is happening, the database should continue accepting reads and writes. 当rebalance发生, database 需要接受reads和writes
- No more data than necessary should be moved between nodes, to make rebalancing fast and to minimize the network and disk I/O load. 只move necessary data,不多move
Strategies for Rebalancing
How not to do it: hash mod N
为什么不用 hash(key) mode 10 return a number between 0 and 9 因为number of nodes N changes, most of key 需要move from one node to another.
Fixed number of partitions
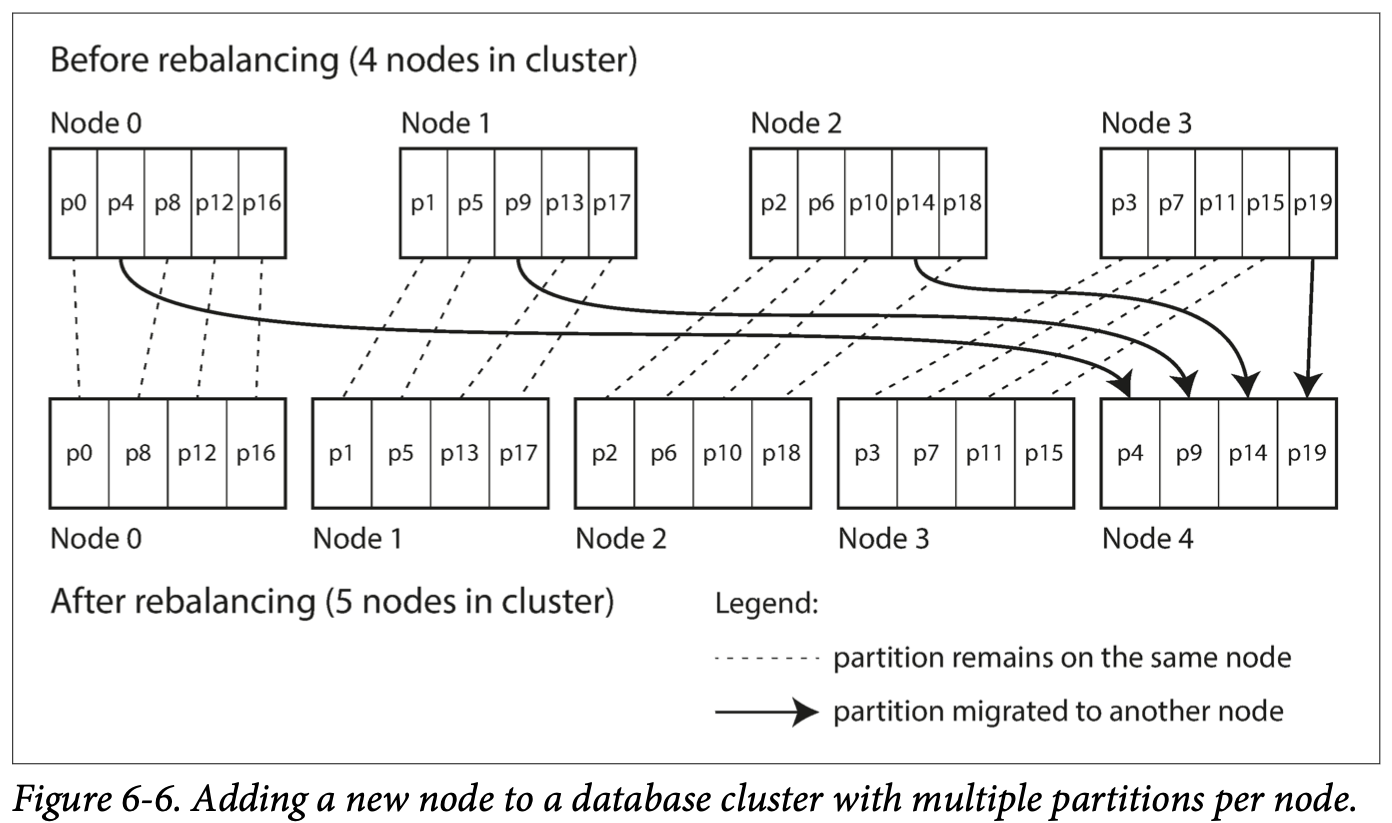
If a node is added to the cluster, the new node can steal a few partitions from every existing node until partitions are fairly distributed once again. the same happens in reverse
The only thing that changes is the assignment of partitions to nodes.** This change of assignment is not immediate**— it takes some time to transfer a large amount of data over the network.
the number of partitions is usually fixed when the database is first set up and not changed afterward.
Choosing the right number of partitions is difficult if the total size of the dataset is highly variable (选择对的partition 数是很困难的如果total size of the dataset 是highly variable) Since each partition contains a fixed fraction of the total data, the size of each partition grows proportionally to the total amount of data in the cluster. If partitions are very large, rebalancing and recovery from node failures become expensive. But if partitions are too small, they incur too much overhead. 如果partition 太大, rebalance and recovery from node failure 是非常expensive, 如果partition 太小, incur too much overhead. “just right,” neither too big nor too small, which can be hard to achieve if the number of partitions is fixed but the dataset size varies.
Dynamic partitioning
- if you got the boundaries wrong, you could end up with all of the data in one partition and all of the other partitions empty. Reconfiguring the partition boundaries manually would be very tedious
- For that reason, key range–partitioned databases such as HBase and RethinkDB create partitions dynamically
- When a partition grows to exceed a configured size (on HBase, the default is 10 GB), it is split into two partitions so that approximately half of the data ends up on each side of the split **超过configured size, 自动split成两个partitions **。
- 同理,如果lots of data deleted, a partition shrinks below some threshold, it can be merged with an adjacent partition
- 每个partition assigned to one node, and each node 可以handle 多个partitions. After a large partition has been split, one of its two halves can be transferred to another node in order to balance the load. In the case of HBase, the transfer of partition files happens through HDFS, the underlying distributed filesystem
- Advantage: the number of partitions adapts to the total data volume
- If there is only a small amount of data, a small number of parti‐ tions is sufficient, so overheads are small; if there is a huge amount of data, the size of each individual partition is limited to a configurable maximum
- empty database start with single partition. 因为没有priori information to draw boundary
- until it hits the point at which the first partition is split—all writes have to be processed by a single node while the other nodes sit idle
- To mitigate this issue, HBase and MongoDB allow an initial set of partitions to be configured on an empty database (this is called pre-splitting 有一个初始的partition). In the case of key-range partitioning, pre-splitting requires that you already know what the key distribution is going to look like
- 适用于 key range–partitioned data, 和 hash-partitioned data
Partitioning proportionally to nodes
With dynamic partitioning, the number of partitions is proportional to the size of the dataset, since the splitting and merging processes keep the size of each partition between some fixed minimum and maximum. On the other hand, with a fixed number of partitions, the size of each partition is proportional to the size of the dataset. Inboth of these cases, the number of partitions is independent of the number of nodes. (两种情况,number of partitions 都独立于number of nodes)
A third option, used by Cassandra and Ketama, is to make the number of partitions proportional to the number of nodes—in other words, to have a fixed number of partitions per node (让partition数量与node 成比例) The size of each partition grows proportionally to the dataset size while the number of nodes remains unchanged, but when you increase the number of nodes, the partitions become smaller again. 当dataset size增加,partition 含有数据增加,当增加number nodes, -> partition 数量减少。 Since a larger data volume generally **requires a larger number of nodes **to store, this approach also keeps the size of each partition fairly stable
当a new node join the cluster, randomly choose a fixed number of exisiting partitions to split, 之后take ownership of one half of each of those split partitions while leave the other half of each partition in place. The randomization can produce unfair splits, but when averaged over a larger number of partitions, the new node ends up taking a fair share of the load from the existing nodes. Cassandra 3.0 introduced an alternative rebalancing algorithm that avoids unfair splits 新的node 进来会有unfair spilt, Cassandra 3,0 介入解决了unfair split
Operations: Automatic or Manual Rebalancing
Fully manual: the assignment of partitions to nodes is explicitly con‐ figured by an administrator, and only changes when the administrator explicitly reconfigures it.
For example, Couchbase, Riak, and Voldemort generate a suggested partition assignment automatically, but require an administrator to commit it before it takes effect.
Fully automated rebalancing
- convenient, less operational work for normal maintenance.
- 但是不可预测. Rebalancing 是 expensive operation, 因为需要rerouting requests and moving a large amount of data from one node to another.
- 如果不是done carefully, overload the network or the nodes, and harm perforamnce of other request while rebalancing in process
- can be dangerous in combination with automatic failure detection. 比如 one node is overloaded and is temporarily slow to respond to requests. The other nodes conclude that the overloaded node is dead, and automatically rebalance the cluster to move load away from it -> puts additional load on the overloaded node, other nodes, and the network—making the situation worse and potentially causing a cascading failure
- can be a good thing to have a human in the loop for rebalancing. It’s slower than a fully automatic process, but it can help prevent operational surprises
Request Routing
比如want to read or write the key, which IP address and port number do I need to connect to. -> a problem called service discovery. 任何software that accessiable over a network has this problem 特别是aim for high availability.
on high level, a few different approaches to this problem
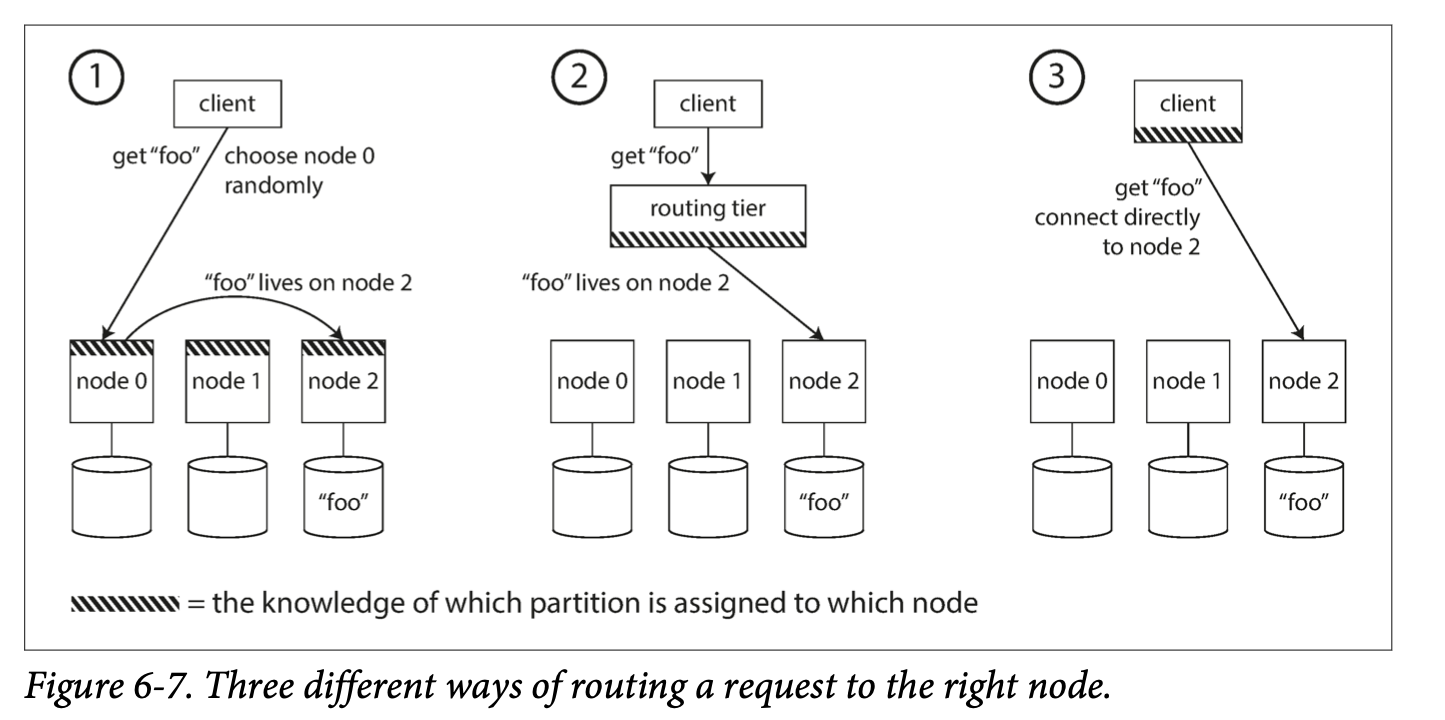
- Allow clients to contact any node (e.g., via a round-robin load balancer). If that node coincidentally owns the partition to which the request applies, it can handle the request directly; otherwise, it forwards the request to the appropriate node, receives the reply, and passes the reply along to the client.
- Send all requests from clients to a routing tier first, which determines the node that should handle each request and forwards it accordingly. This routing tier does not itself handle any requests; it only acts as a partition-aware load balancer. 都先发到routing tier
- Require that clients be aware of the partitioning and the assignment of partitions to nodes. In this case, a client can connect directly to the appropriate node, without any intermediary.
the key problem is: how does the component making the routing decision (which may be one of the nodes, or the routing tier, or the client) learn about changes in the assignment of partitions to nodes?
it is important that all participants agree— otherwise requests would be sent to the wrong nodes and not handled correctly. There are protocols for achieving consensus in a distributed system, but they are hard to implement correctly
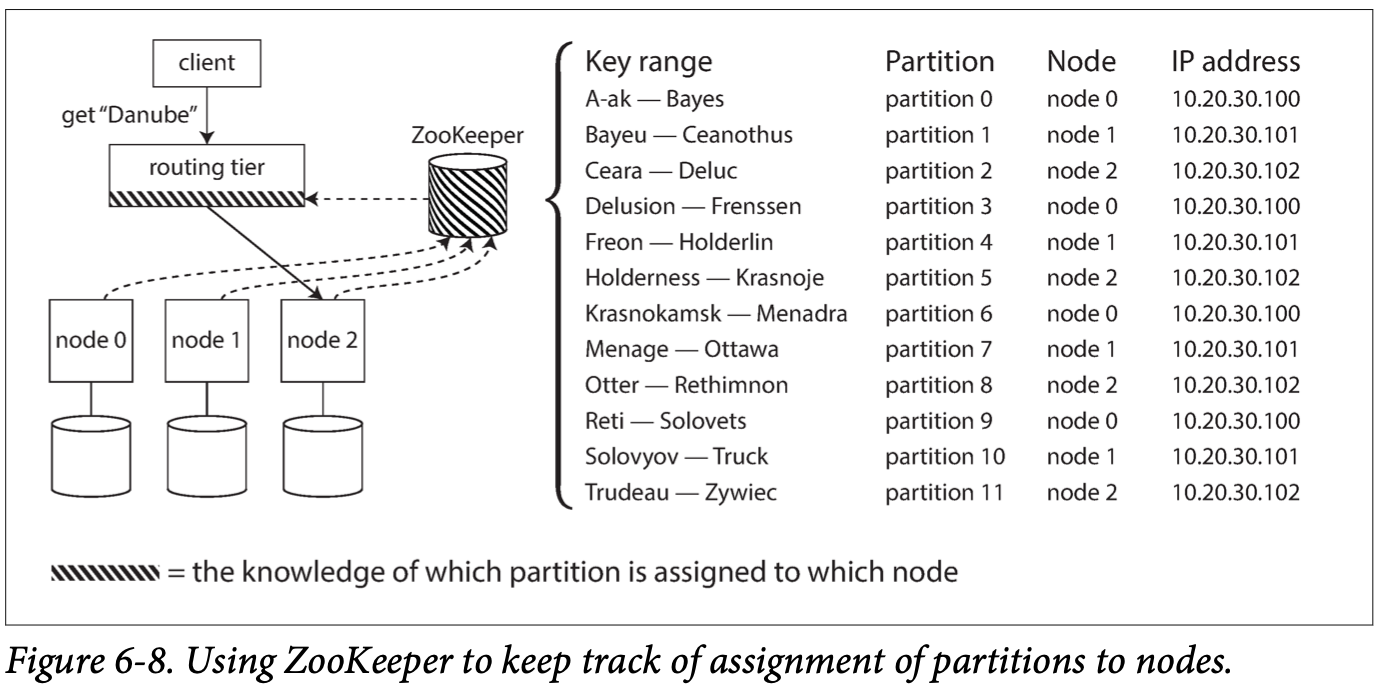
- Many distributed data systems rely on a separate coordination service such as Zoo‐ Keeper to keep track of this cluster metadata
- Each node registers itself in ZooKeeper, and ZooKeeper maintains the authoritative mapping of partitions to nodes. 每个node 都register iteslf zookeeper maintain data mapping
- Whenever a partition changes ownership, or a node is added or removed, ZooKeeper notifies the routing tier so that it can keep its routing information up to date. 当partition, nodes发生改变 会notify routing tier
- For example, LinkedIn’s Espresso uses Helix for cluster management (which in turn relies on ZooKeeper), implementing a routing tier as shown in Figure 6-8. HBase, SolrCloud, and Kafka also use ZooKeeper to track partition assignment. MongoDB has a similar architecture, but it relies on its own config server implementation and mongos daemons as the routing tier
Cassandra and Riak take a different approach
- gossip protocol among the nodes to disseminate any changes in cluster state. Requests can be sent to any node request可以发到任何的node, and that node forwards them to the appropriate node for the requested partition(approach 1 in Figure 6-7).
- This model puts more complexity in the database nodes but avoids the dependency on an external coordination service such as ZooKeeper
- Couchbase does not rebalance automatically, which simplifies the design. Normally it is configured with a routing tier called moxi, which learns about routing changes from the cluster nodes
- When using a routing tier or when sending requests to a random node, clients still need to find the IP addresses to connect to. These are not as fast-changing as the assignment of partitions to nodes, so it is often sufficient to use DNS for this purpose
Parallel Query Execution
- massively parallel processing (MPP) relational database products
- A typical data warehouse query contains several join, filtering, grouping, and aggregation operations.
- The MPP query optimizer breaks this complex query into a number of execution stages and partitions, many of which can be executed in parallel on different nodes of the database cluster. MPP把query 变成number of execution stages, executed in parallel.
- Queries that involve scanning over large parts of the dataset particularly benefit from such parallel execution
Transactions
A transaction is a way for an application to group several reads and writes together into a logical unit. Conceptually, all the reads and writes in a transaction are executed as one operation: either the entire transaction succeeds (commit) or it fails(abort, rollback). If it fails, the application can safely retry. With transactions, error handling becomes much simpler for an application, because it doesn’t need to worry about partial failure. 一个transcation 要么全部成功,要么全部失败
The Meaning of ACID
Atomicity, Consistency, Isolation, and Dura‐bility
Atomicity:
- atomic refers to something that cannot be broken down into smaller parts.
- if one thread executes an atomic operation, that means there is no way that another thread could see the half-finished result of the operation. The system can only be in the state it was before the operation or after the operation, not something in between.
- not about concurrency. not describe what happens if several processes try to access the same data at the same time, because that is covered under the letter I, for isolation
- ACID atomicity describes what happens if a client wants to make several writes, but a fault occurs after some of the writes have been processed—for example, a process crashes, a network connection is interrupted, a disk becomes full, or some integrity constraint is violated. If the writes are grouped together into an atomic transaction, and the transaction cannot be completed (committed) due to a fault 如果writes group together into atomic transaction不能完成因为fault, then the transaction is aborted and the database must discard or undo any writes it has made so far in that transaction.
- Without atomicity, 如果有error ocurrs partway through making 多个chagnes, 不知道which changes taken effect and which haven’t. 如果重试,risk making the same change twice, leading to duplicate or incorrect data.
- Atomicity simplifies this problem: if a transaction was aborted, the application can be sure that it didn’t change anything, so it can safely be retried.
- The ability to abort a transaction on error and have all writes from that transaction discarded is the defining feature of ACID atomicity **如果有一个错误,全部丢弃 **
Consistency
• In Chapter 5 we discussed replica consistency and the issue of eventual consistency that arises in asynchronously replicated systems (see “Problems with Replication Lag” on page 161). • Consistent hashing is an approach to partitioning that some systems use for rebalancing (see “Consistent Hashing” on page 204). • In the CAP theorem (see Chapter 9), the word consistency is used to mean linearizability
- In the context of ACID, consistency refers to an application-specific notion of the database being in a “good state“
- this idea of consistency depends on the application’s notion of invariants(data), and it’s the application’s responsibility to define its transactions correctly so that they preserve consistency. This is not something that the database can guarantee: if you write bad data that violates your invariants, the database can’t stop you (some 可以被检查,比如foreign key constraint or uniqueness constraint)
- Atomicity, isolation, and durability are properties of the database, whereas consistency (in the ACID sense) is a property of the application
Isolation
- accessing the same database records, 可能有concurrency problems
- Isolation in the sense of ACID means that concurrently executing transactions are isolated from each other 同时的statement是相互独立的。 cannot step on each other’s toes
- The classic database textbooks formalize isolation as serializability, which means that each transaction can pretend that it is the only transaction running on the entire database (每个transaction 都假设是only transaction running on entire database)
- The database ensures that when the transactions have committed, the result is the same as if they had run serially (one after another), even though in reality they may have run concurrently 数据库确保transaction committed, result是一样的就像run serially
- in practice, serializable isolation is rarely used, because it carries a performance penalty. 实际上serializable isolation很少被用,因为performance原因
- Oracle implement called snapshot isolation, eaker guarantee than serializability.
Durability
- Durability is the promise that once a transaction has committed successfully, any data it has written will not be forgotten, even if there is a hardware fault or the database crashes (Durability 保证当transaction commited, 任何data都不会被丢失, 即使database crash)
- In a single-node database, durability typically means that the data has been written to nonvolatile storage such as a hard drive or SSD
- 通常invole write-ahead log or similar, which allows recovery in the event that the data structures on disk are corrupted.
- In a replicated database, durability may mean that the data has been successfully copied to some number of nodes 表示data 成功被复制到一些node. 为了提供durability guarantee, a database必须wait until these writes or replications are complete before a transaction as succesfully committed.
- perfect durability does not exist: if all your hard disks and all your backups are destroyed at the same time, there’s obviously nothing your database can do to save you
The truth is, nothing is perfect. In practice, there is no one technique that can provide absolute guarantees. various risk-reduction techniques, including writing to disk, replicating to remote machines, and backups—and they can and should be used together. ** 不可能提供absolute的保证,只能尽可能提供risk-reduction techniques 包括writing to disk, 复制到remote machine 和back-up**
比如
- if write to disk and machine dies, 数据没有丢失 但是inaccessible, either fix machine or transfer the disk to another machine
- A correlated fault: a power outage or a bug that crashes every node on partiular input - can knock out all replicas at once
- asynchronously replicated system, recent writes may be lost when the leader becomes unavailable
- When the power is suddenly cut, SSD show sometimes violate the guarantee that they provide: even
fsync(write all modified data for a given file to the disk) isn’t guaranteed to work correctly. - subtle interactions between storage enigne and filesystem implementation can lead to bugs that are hard to track down.
- Data on disk become corrupted wihtout being detected. 如果data corrupted for some time, replicas and recent backups 可能也corrupted
- One study of SSDs found that between 30% and 80% of drives develop at least one bad block during the first four years of operation. Magnetic hard drives have a lower rate of bad sectors, but a higher rate of complete failure than SSD
- If an SSD is disconnected from power, it can start losing data within a few weeks, depending on the temperature
Single-Object and Multi-Object Operations
Atomicity
If an error occurs halfway through a sequence of writes, the transaction should be aborted, and the writes made up to that point should be discarded. In other words, the database saves you from having to worry about partial failure, by giving an all-or-nothing guarantee.
Isolation
Concurrently running transactions shouldn’t interfere with each other. For example, if one transaction makes several writes, then another transaction should see either all or none of those writes, but not some subset.
下图 illustrates the need for atomicity: if an error occurs somewhere over the course of the transaction, the contents of the mailbox and the unread counter might become out of sync. In an atomic transaction, if the update to the counter fails, the transaction is aborted and the inserted email is rolled back.
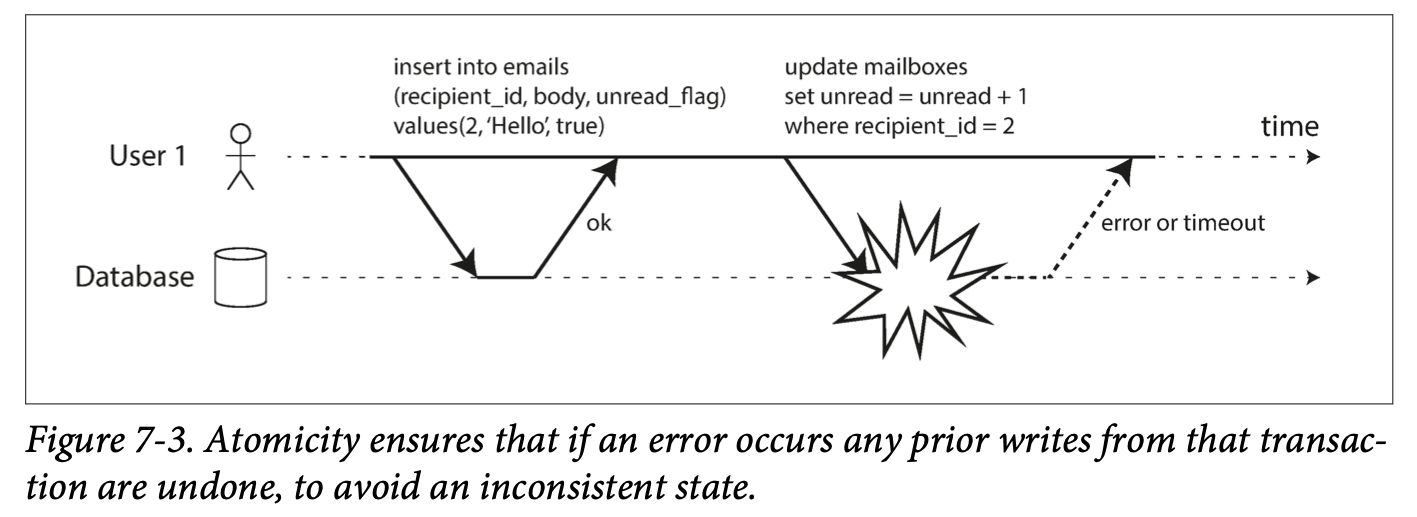
Multi-object transactions require some way of determining which read and write operations belong to the same transaction. In relational database, typically done based on the client’s TCP connection to the database server. on any particular connection, everything between a BEGIN TRANSACTION and a COMMIT statement is considered to be part of the same transaction (This is not ideal. If the TCP connection is interrupted, the transaction must be aborted. If the interruption happens after the client has requested a commit but before the server acknowledges that the commit happened, the client doesn’t know whether the transaction was committed or not. To solve this issue, a transaction manager can group operations by a unique transaction identifier that is not bound to a particular TCP connection)
对于nonrelational database, don’t have such a way of grouping operations together. Even if there is a multi-object API. that doesn’t necessarily mean it has transaction semantics. Command 可能成功for some keys and fail for others, leaving database in partially updated state.
Single-object writes
storage engines almost universally aim to provide atomicity and isolation on the level of a single object on one node.
Handling errors and aborts
A key feature of a transaction is that it can be aborted and safely retried if an error occurred. If the database is in danger of violating its guarantee of atomicity, isolation, or durability, it would rather abandon the transaction entirely than allow it to remain half-finished.
Not all systems follow that philosophy, 比如leaderless replication - will do as much as it can, and if it runs into error, won’t undo something it has already done. - it’s application’s responsibility to recover from errors
retrying an aborted transaction is a simple and effective error handling 但不是perfect
- 如果transaction succeed, but network failed while server tried to ack successful commit to client, retrying the transaction cuase it to be performed twice - unless you have application level dedup mechansim
- If error due to overload, retrying transaction make problem worse. To avoid such feedback cycles, limit the number of retries, use exponential backoffs, and handle overload-related errors differently from other errors
- only worth retrying after transient errors (比如deadlock, isolation violation, temporary network interruptions, and failover). After a permanent error, a retry pointless
- If the transaction also has side effects outside of the database, those side effects may happen even if the transaction is aborted. 比如发送邮件,不想send email again everyt time you retry the transaction
- If client process fails while retrying, any data it was trying to write to the database is lost
Weak Isolation Levels
If two transactions don’t touch the same data, they can safely be run in parallel, because neither depends on the other.
因为concurrency issue 很难reproduce, databases have long tried to hide concurrency issues from application developers by providing transaction isolation.
In practice, isolation is unfortunately not that simple. Serializable isolation has a performance cost, and many databases don’t want to pay that price. It’s therefore common for systems to use weaker levels of isolation, which protect against some concurrency issues, but not all.
Read Committed
makes two guarantees
- When reading from the database, you will only see data that has been committed(no dirty reads).
- When writing to the database, you will only overwrite data that has been committed (no dirty writes).
No dirty reads
Imagine a transaction has written some data to the database, but the transaction has not yet committed or aborted. Can another transaction see that uncommitted data? If yes, that is called a dirty read
Transaction running at read committed isolation level must prevent dirty reads. Any writes by a transaction only become visible to others when that transaction commits.
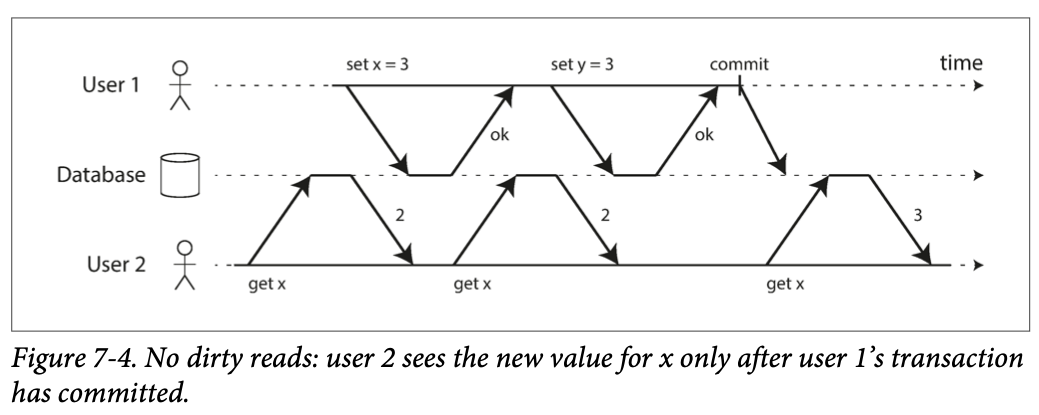
比如上图 where user 1 has set x = 3, but user 2’s get x still returns the old value, 2, while user 1 has not yet committed
- If a transaction needs to update several objects, a dirty read means that another transaction may see some of the updates but not others. Seeing the database in a partially updated state is confusing to users and may cause other transactions to take incorrect decisions.
- If a transaction aborts, any writes it has made need to be rolled back. If the database allows dirty reads, that means a transaction may see data that is later rolled back—i.e., which is never actually committed to the database. Reasoning about the consequences quickly becomes mind-bending.
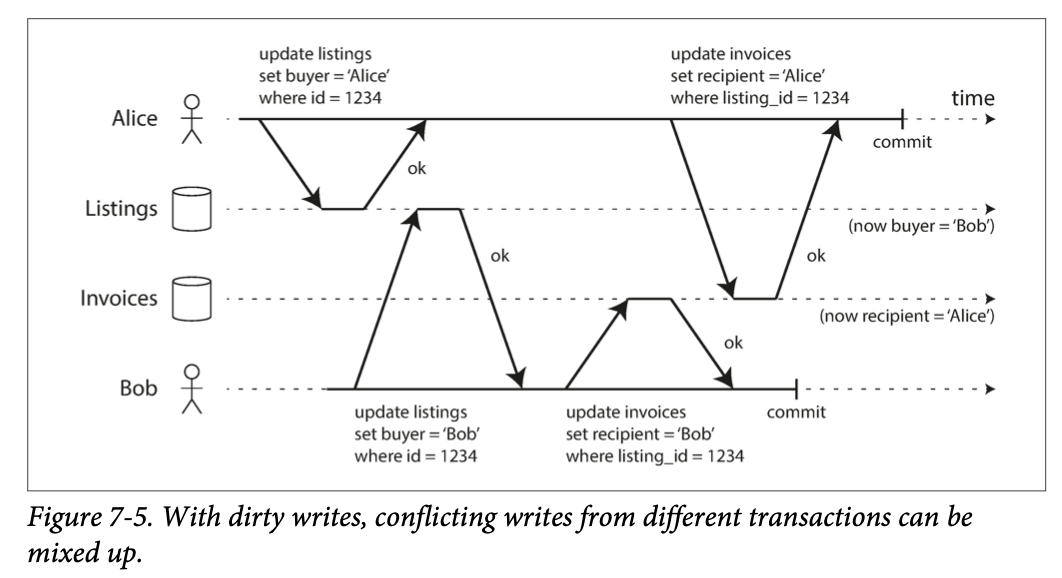
No dirty writes
if the earlier write is part of a transaction that has not yet committed, so the later write overwrites an uncommitted value? This is called a dirty write. Transactions running at the read committed isolation level must prevent dirty writes, usually by delaying the second write until the first write’s transaction has committed or aborted.
Implementing read committed
- Read committed is a very popular isolation level. It is the default setting in Oracle 11g, PostgreSQL, SQL Server 2012, MemSQL, and many other databases
- prevent dirty writes by using row-level locks: 当想要modify a particular object,** 必须acquire a lock. 必须hold the lock 知道transaction completed or aborted**.
- only one transaction can hold the lock for any given object; if another transaction wants to write to the same object, 必须wait until the first transaction is committed or aborted bfore acquire the lock
- This locking is done automatically by databases in read committed mode (or stronger isolation levels)
- How to prevent direty reads? use the same lock, require any transaction that wants to read an object to acquire lock and release it after reading. 可以确保read couldn’t happen while an object an dirty, uncommitted value. (因为 lock held by the write transaction)
- 这个方法并不work well. one long-running write transaction can force many read-only transactions to wait until the long-running transaction has completed (一个长的write 可以force 许多read 等待)
- This harms the response time of read-only transactions and is bad for operability: a slowdown in one part of an application can have a knock-on effect in a completely different part of the application, due to waiting for locks
For above reason, 需要database prevent dirty reads using the approach as belwo
For every object written, database 记住old committed value and new value set by transaction that currently holds the write lock. While the transaction is ongoing, any other transactions that read the object are simply given the old value. Only when the new value is committed do transactions switch over to reading the new value. 记住两个值,一个old 一个新的还没commited的值,当read时候,给old值,直到value committed, switch to new value
Snapshot Isolation and Repeatable Read
Read committed isolation, does
- it allows aborts (required for atomicity), it prevents reading the incomplete results of transactions
- it prevents concurrent writes from getting intermingled.
还有ways which you can have concurrency bugs when using this isolation level. 比如a problem can occur with read committed
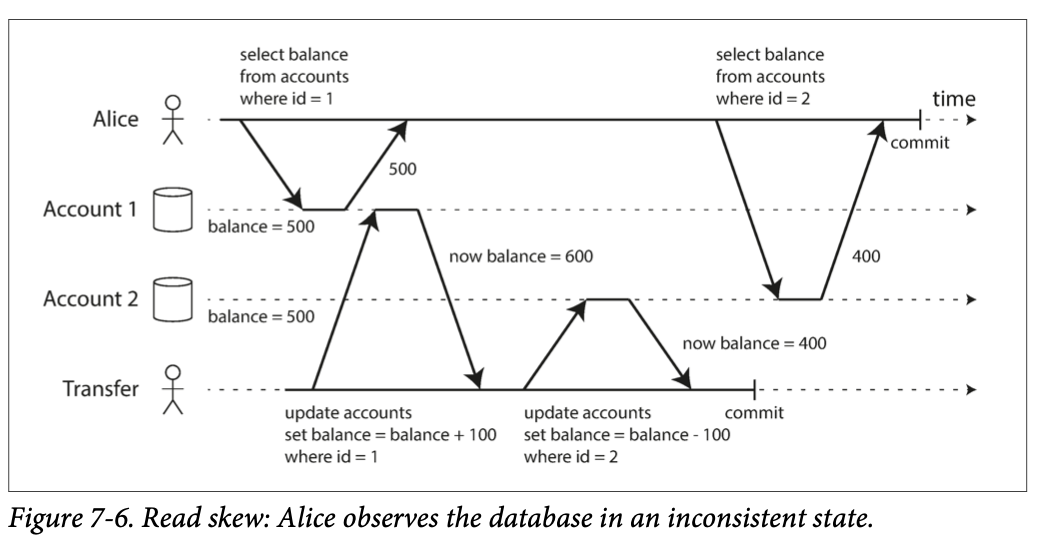
比如alice transfer account balance 从一个账户到另一个 (500 each in two accounts),如果transfer time和她look at account balance time重合,可能看到账户里少了100(1000 -> 900). This anomaly is called a nonrepeatable read or read skew. Read skew is considered acceptable under read committed isolation (read skew是被允许的在committed isolation)
some situations cannot tolerate such temporary inconsistency:
- Backups: take a back 需要make a copy of entire database, may take hours on a large database. During the time that backup is running, writes will made to the database. End with 一些backup containing old version of data, other parts containing new version. 如果需要store from backup, inconsistencies become permanent.
- Analytic queries and integrity checks. run a query that scans over large parts of database. These queries 很有可能return nonsensical results if they observe parts of database at different points in time
Snapshot isolation 最常见的solution to this problem. Each transaction reads from a consistent snapshot of the database, transaction sees all the data that was committed in the database at the start of the transaction. Even if the data 随后改变, each transaction sees only the old data from that particular point in time.
Snapshot isolation is a popular feature: it is supported by PostgreSQL, MySQL with the InnoDB storage engine, Oracle, SQL Server, and others
Implementing snapshot isolation
Implementation of snapshot isolation 通常使用write lock to prevent dirty writes. a transaction that makes a write can block the progress of another transaction that writes to the same object. 但是read 不需要任何block, a key principle of snapshot isolation is readers never block writers, and writers never block readers. allows a database to handle long-running read queries on a consistent snapshot at the same time as processing writes normally, without any lock contention between the two
Database 必须keep serveral committed version, because various in-progress transaction may need to see the state of database at different points in time. 因为maintain several version, 叫做multi-version concurrency control (MVCC)
如果只提供read committed isolation 而不是snapshot isolation, sufficient to keep two version: committed version and the overwritten-but-not-yet-committed version. storage engines that support snapshot isolation typically use MVCC for their read committed isolation level as well. A typical approach is that read committed uses a separate snapshot for each query, while snapshot isolation uses the same snapshot for an entire transaction. Read committed 是不同的snapshot for each query, 但是snapshot isolation use the same snapshot
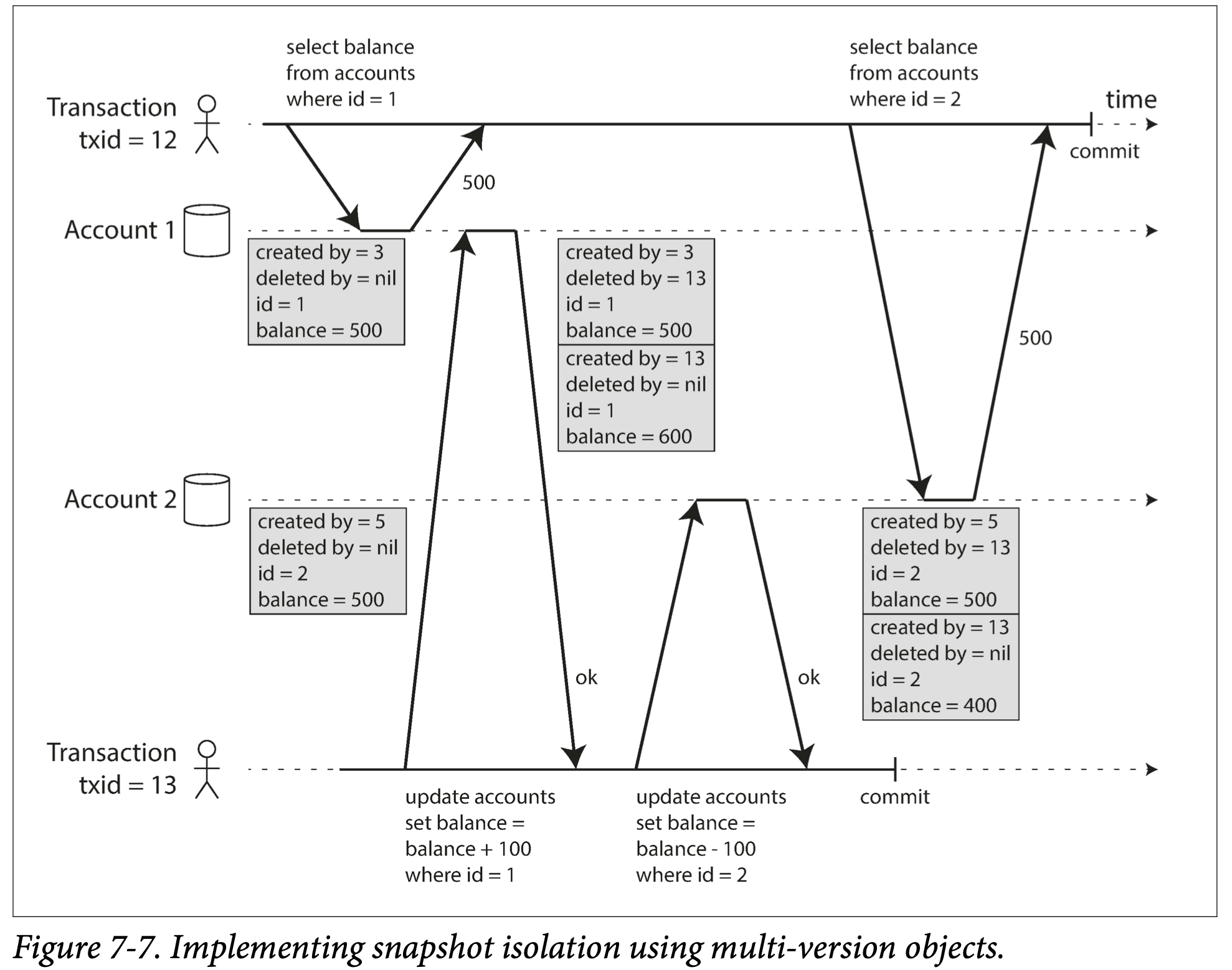
上面解释how MVCC-based snapshot isolation implemented in Post-greSQL. When a transaction is started, it is given a unique, always-increasing transaction ID (txid). Whenever a transaction writes anything to the database, the data it writes is tagged with the transaction ID of the writer. (当transaction开始,给一个unique transaction ID, 当transaction 写进DB, tagged with writer的transaction id)
Each row in a table has a created_by field, containing the ID of the transaction that inserted this row into the table. Moreover, each row has a deleted_by field, which is initially empty. If a transaction deletes a row, the row isn’t actually deleted from the database, but it is marked for deletion by setting the deleted_by field to the ID of the transaction that requested the deletion. 上图的balance 减100 分成两步,delete account balance as 500, a created balance as 400
Visibility rules for observing a consistent snapshot
When a transaction reads from the database, transaction IDs are used to decide which objects it can see and which are invisible. defining visibility rules, database can present a consistent snapshot of the database to the application: (当read transaction, visibility rule defined如下)
- At the start of each transaction, the database makes a list of all the other transactions that are in progress (not yet committed or aborted) at that time. Any writes that those transactions have made are ignored, even if the transactions subsequently commit. 一个transaction 之前的所有query都被忽略
- Any writes made by aborted transactions are ignored. 所有被abort的transaction被ignored
- Any writes made by transactions with a later transaction ID (i.e., which started after the current transaction started) are ignored, regardless of whether those transactions have committed. (所有在read 之后的write都被忽略,不管是否committed 成功)
- All other writes are visible to the application’s queries.
an object is visible if both of the following conditions are true:
- At the time when the reader’s transaction started, the transaction that created the object had already committed. 当read 时候,write已经被committed
- The object is not marked for deletion, or if it is, the transaction that requested deletion had not yet committed at the time when the reader’s transaction started. read时候 deletion object not committed
By never updating values in place but instead creating a new version every time a value is changed, the database can provide a consistent snapshot while incurring only a small overhead.
Indexes and snapshot isolation
multi-version database:
- One option is to have the index simply point to all versions of an object and require an index query to filter out any object versions that are not visible to the current transaction. When garbage collection removes old object versions that are no longer visible to any transaction, the corresponding index entries can also be removed.
- PostgreSQL has optimizations for avoiding index updates if different versions of the same object can fit on the same page
- Another approach is used in CouchDB, Datomic, and LMDB. Although they also use B-trees (see “B-Trees” on page 79), they use an** append-only/copy-on-write variant**that does not overwrite pages of the tree when they are updated, but instead creates a new copy of each modified page. Parent pages, up to the root of the tree, are copied and updated to point to the new versions of their child pages. Any pages that are not affected by a write do not need to be copied, and remain immutable
- every write transaction (or batch of transactions) creates a new B-tree root, and a particular root is a consistent snapshot of the database at the point in time when it was created. There is no need to filter out objects based on transaction IDs because subsequent writes cannot modify an existing B-tree; they can only create new tree roots. However, this approach also requires a background process for compaction and garbage collection.
Snapshot isolation is a useful isolation level, especially for read-only transactions. many databases that implement it call it by different names. In Oracle it is called serializable, and in PostgreSQL and MySQL it is called repeatable read (命名不同 因为SQL standard doesn’t have the concept of snapshot isolation,). PostgreSQL and MySQL call their snapshot isolation level repeatable read
Preventing Lost Updates
The lost update problem can occur if an application reads some value from the database, modifies it, and writes back the modified value (a read-modify-write cycle). If two transactions do this concurrently, one of the modifications can be lost, because the second write does not include the first modification. (We sometimes say that the later write clobbers the earlier write.) . 比如两个user modify wiki page at the same time
Atomic write operations
Atomic operations are usually implemented by taking an exclusive lock on the object when it is read so that no other transaction can read it until the update has been applied. This technique is sometimes known as cursor stability. Another option is to simply force all atomic operations to be executed on a single thread.
Unfortunately, object-relational mapping frameworks make it easy to accidentally write code that performs unsafe read-modify-write cycles instead of using atomic operations provided by the database (虽然更好写,但更容易有bug)
Explicit locking
如果没有built-in atomic operation, is for application to explicitly lock objects that are going to be updated. 有lock后 Then application 可以执行read-modify-write cycle, 如果any other transaction tries to concurrently read the same object, 必须forced to wait until the first read-modify-write cycle has completed
Automatically detecting lost updates
An alternative is to allow them to execute in parallel and, if the transaction manager detects a lost update, abort the transaction and force it to retry its read-modify-write cycle
advantage: perform this check efficiently in conjunction with snapshot isolation.
PostgreSQL’s repeatable read, Oracle’s serializable, and SQL Server’s snapshot isolation levels automatically detect when a lost update has occurred and abort the offending transaction. However, MySQL/InnoDB’s repeatable read does not detect lost updates (Postgre, Oracle 有自动检测lost update, MySQL和innoDB 没有自动检测). MySQL does not provide snapshot isolation under this definition
Compare-and-set
write时候 compare the value with last read, 如果不match, 不update, read-modify-write cycle must be retried (concurrent updating)
Conflict resolution and replication
对于multi-leader or leaderless replication, **允许concurrent writes to create sveral conflicting versions and replicate async, then use application code or special data structure to resolve and merge these versions **
the last write wins (LWW) conflict resolution method is prone to lost updates
Write Skew and Phantoms
write skew- It is neither a dirty write nor a lost update (因为是concurrent write).write skew as a generalization of the lost update problem. write skew 的发生是因为two transaction read the same objects, and then update some of those objects
With write skew, our options are more restricted:
- Atomic single-object operations don’t help, as multiple objects are involved.
- The automatic detection of lost updates that you find in some implementations of snapshot isolation unfortunately doesn’t help either: write skew is not auto‐ matically detected
- If you can’t use a serializable isolation level, the second-best option in this case is probably to explicitly lock the rows that the transaction depends on.
snapshot isolation does not prevent another user from concurrently inserting a conflicting meeting
比如在write时候一直read,当write之后,read结果发生改变。This effect, where a write in one transaction changes the result of a search query in another transaction, is called a phantom (一个werite 影响另一个search query结果)。 Snapshot isolation avoids phantoms in read-only queries, but in read-write transactions, phantoms can lead to particularly tricky cases of write skew
Serializable Isolation
Serializable isolation is usually regarded as the strongest isolation level. It guarantees that even though transactions may execute in parallel, the end result is the same as if they had executed one at a time, serially, without any concurrency. (即使可能concurrent, 但是结果和execute one at a time是一样的)
three techniques:
- Literally executing transactions in a serial order
- Two-phase locking (see “Two-Phase Locking (2PL)” on page 257), which for several decades was the only viable option
- Optimistic concurrency control techniques such as serializable snapshot isolation
With stored procedures and in-memory data, executing all transactions on a single thread becomes feasible. As they don’t need to wait for I/O and they avoid the overhead of other concurrency control mechanisms, they can achieve quite good throughput on a single thread.
Whether transactions can be single-partition depends very much on the structure of the data used by the application
Partitioning
In order to scale to multiple CPU cores, and multiple nodes, you can potentially partition your data. each partition can have its own transaction processing thread running independently from the others. In this case, you can give each CPU core its own partition, which allows your transaction throughput to scale linearly with the number of CPU cores
The stored procedure needs to be performed in lock-step across all partitions to ensure serializability across the whole system.
Summary of serial execution
- Every transaction must be small and fast, because it takes only one slow transaction to stall all transaction processing.
- It is limited to use cases where the active dataset can fit in memory. Rarely accessed data could potentially be moved to disk, but if it needed to be accessed in a single-threaded transaction, the system would get very slow.x
- Write throughput must be low enough to be handled on a single CPU core, or else transactions need to be partitioned without requiring cross-partition coordination.
- Cross-partition transactions are possible, but there is a hard limit to the extent to which they can be used.
Two-Phase Locking (2PL)
- 只要没有write,可以多个concurrent read. 但只要有想write an object, exclusive access是需要的
- If transaction A has read an object and transaction B wants to write to that object, B must wait until A commits or aborts before it can continue. (This ensures that B can’t change the object unexpectedly behind A’s back.) 写在read之后完成
- If transaction A has written an object and transaction B wants to read that object, B must wait until A commits or aborts before it can continue。A 写了一个数据,B read需要A commit or abort
- In 2PL, writers don’t just block other writers; they also block readers and vice versa.
- 但snapshot isolation, reader不会block writers, writer never block read
- 2 PL protects against all the race conditions, including lost updates and write skew
The lock can either be in shared mode or in exclusive mode
- 如果想read object, 必须acquire lock in shared mode. 多个transaction可以同时有shared mode 但如果另一个transaction 已经有exclusive lock, transaction 必须wait
- 如果想write, 必须acquire the lock in exclusive mode. 不能同时有多个transaction 是exclusive mode, 如果有existing lock, transaction必须wait • **如果先read, 再write, 可以upgrade shared lock to exclusive lock. Update works same as getting an eclusive **
- 再拥有lock后,可以hold the lock until transaction结束. Two phase:第一个phase是 when locks are acquire, 第二个是when all the locks are released
可能会有deadlock, database detect自动between transaction, 然后abort one of transaction。Abort transaction需要retry
performance downside是performance. transaction throughput and response times of queries are significantly worse under two-phase locking than under weak isolation. partly due to the overhead of acquiring and releasing all those locks, but more importantly due to reduced concurrency. 还有deadlock问题,被aborted, 就需要retry, do the work again
Predicate locks
- 如果transaction A想要read oject, 必须acquire a shared-mode predicate lock. 如果transaction B has an exclusive lock on any object matching conditions. A 必须等B release before acquire the lock
- 如果transaction A想要insert, update, delete. 必须check whether either old or new value matches any existing predicate lock. 如果有predict lock held by transaction B, A必须等待直到 B committed or aborted
- **key idea here is that a predicate lock applies even to objects that do not yet exist in the database, but which might be added in the future **
- predicate locks do not perform well: if there are many locks by active transactions, checking for matching locks becomes time-consuming
index-range locking
- simplified approximation of predicate locking
- provided protection against phantoms and write skew
- lower overhead, good compromise
Serializable Snapshot Isolation (SSI)
- **full serializability, but has only a small performance penalty compared to snapshot isolation **
- used both in single-node databases (PostgreSQL since version 9.1) and distributed databases
- Serial execution: it is essentially equivalent to each transaction having an exclusive lock on the entire database.
- optimistic concurrency control technique
- if there is enough spare capacity, and if contention between transactions isnot too high, optimistic concurrency control techniques tend to perform better than pessimistic ones
Two-phase locking is a so-called pessimistic concurrency control mechanism: it is based on the principle that if anything might possibly go wrong (as indicated by a lock held by another transaction), it’s better to wait until the situation is safe again before doing anything
Detecting writes that affect prior reads
When a transaction writes to the database, it must look in the indexes for any other transactions that have recently read the affected data ; lock as a tripwire: it simply notifies the transactions that the data they read may no longer be up to date.
上图 transaction 43 notifies transaction 42 that its prior read is outdated, and vice versa. Transaction 42 is first to commit, and it is successful: although transaction 43’s write affected 42, 43 hasn’t yet committed, so the write has not yet taken effect. However, when transaction 43 wants to commit, the conflicting write from 42 has already been committed, so 43 must abort.
big advantage of serializable snapshot isolation is that one transaction doesn’t need to block waiting for locks held by another transaction (一个transaction 不会block waiting for locks held by another transaction. Like under snapshot isolation, writers don’t block readers, and vice versa. This design principle makes query latency much more predictable and less variable.
The rate of aborts significantly affects the overall performance of SSI. For example, a transaction that reads and writes data over a long period of time is likely to run into conflicts and abort, so SSI requires that read-write transactions be fairly short (long-running read-only transactions may be okay). However, SSI is probably less sensitive to slow transactions than two-phase locking or serial execution
Summary
- Dirty reads: One client reads another client’s writes before they have been committed. The read committed isolation level and stronger levels prevent dirty reads. (在commit 前读取)
- Dirty writes: One client overwrites data that another client has written, but not yet committed. Almost all transaction implementations prevent dirty writes. (一个覆写了另一个record)
- Read skew (nonrepeatable reads) A client sees different parts of the database at different points in time (不同时间看见的不同的数据). This issue is most commonly prevented with snapshot isolation, which allows a transaction to read from a consistent snapshot at one point in time. It is usually implemented with multi-version concurrency control (MVCC).
- Lost updates Two clients concurrently perform a read-modify-write cycle. One overwrites the other’s write without incorporating its changes, so data is lost 一个覆写了另一个record 造成数据丢失. Some implementations of snapshot isolation prevent this anomaly automatically, while others require a manual lock (SELECT FOR UPDATE).
- Write skew A transaction reads something, makes a decision based on the value it saw, and writes the decision to the database. However, by the time the write is made, the premise of the decision is no longer true. Only serializable isolation prevents this anomaly.
- Phantom reads A transaction reads objects that match some search condition. Another client makes a write that affects the results of that search. Snapshot isolation prevents straightforward phantom reads, but phantoms in the context of write skew require special treatment, such as index-range locks.
The Trouble with Distributed Systems
The difficulty is that partial failures are nondeterministic:. some parts of the system that are broken in some unpredictable way, even though other parts of the system are working fine
If we want to make distributed systems work, we must accept the possibility of partial failure and build fault-tolerance mechanisms into the software. we need to build a reliable system from unreliable components
If you send a request and expect a response, many things could go wrong (some of which are illustrated in Figure 8-1):
- Your request may have been lost (perhaps someone unplugged a network cable).
- Your request may be waiting in a queue and will be delivered later (perhaps the network or the recipient is overloaded).
- The remote node may have failed (perhaps it crashed or it was powered down).
- The remote node may have temporarily stopped responding (perhaps it is experiencing a long garbage collection pause; see “Process Pauses” on page 295), but it will start responding again later.
- The remote node may have processed your request, but the response has been lost on the network (perhaps a network switch has been misconfigured).
- The remote node may have processed your request, but the response has been delayed and will be delivered later (perhaps the network or your own machine is overloaded).
The usual way of handling this issue is a timeout. when a timeout occurs, still don’t know whether the remote node got your request or not
It may make sense to deliberately trigger network problems and test the system’s response
A load balancer needs to stop sending requests to a node that is dead (i.e., take it out of rotation)
Timeouts and Unbounded Delays
A long timeout means a long wait until a node is declared dead (and during this time, users may have to wait or see error messages). A short timeout detects faults faster, but carries a higher risk of incorrectly declaring a node dead when in fact it has only suffered a temporary slowdown
When a node is declared dead, its responsibilities need to be transferred to other nodes, which places additional load on other nodes and the network. If the system is already struggling with high load, declaring nodes dead prematurely can make the problem worse. Transferring its load to other nodes can cause a cascading failure
every packet is either delivered within some time d, or it is lost, but delivery never takes longer than d. Furthermore, assume that you can guarantee that a non- failed node always handles a request within some time r. In this case, you could guarantee that every successful request receives a response within time 2d + r—and if you don’t receive a response within that time, you know that either the network or the remote node is not working. If this was true, 2d + r would be a reasonable timeout to use
most systems we work with have neither of those guarantees: asynchronous networks have unbounded delays (that is, they try to deliver packets as quickly as possible, but there is no upper limit on the time it may take for a packet to arrive
Network congestion and queueing
When driving a car, travel times on road networks often vary most due to traffic congestion. Similarly, the variability of packet delays on computer networks is most often due to queueing
- 太多发到一个destination. eventually queue fills up. packet dropped -> need to resend
- all CPU cores are currently busy , incoming request queued by OS until application ready to handle
- In virtualized environments, a running operating system is often paused for tens of milliseconds while another virtual machine uses a CPU core. During this time, the VM cannot consume any data from the network, so the incoming data is queued (buffered) by the virtual machine monitor [26], further increasing the variability of network delays.
- TCP performs flow control in which a node limits its own rate of sending in order to avoid overloading a network link or the receiving node (发送的node自己限流). This means additional queueing at the sender before the data even enters the network
TCP considers a packet to be lost if it is not acknowledged within some timeout (which is calculated from observed round-trip times), and lost packets are automatically retransmitted (TCP 如果timeout内没有ack, 认为lost, 重新发送lost的 packet,). -> resulting delay
TCP Versus UDP
- trade-off between reliability and variability of delays
- **UDP does not perform flow control and does not retransmit lost packets,it avoids some of the reasons for variable network delays **
- UDP is a good choice in situations where delayed data is worthless
- 比如 VoIP phne call. isn’t enough time to retransmit a lost packet before its data is due to be played over the loudspeakers (retry happens at the human layer instead.)
- While a TCP connection is idle, it doesn’t use any bandwidth (TCP dynamically adapts the rate of data transfer to the available network capacity)
- 对于 circuit network, 即使slot unused, still allocated the same fixed amount of bandwidth
determine an appropriate trade-off between failure detection delay and risk of premature timeouts
更好的是 rather than using configured constant timeouts, systems can continually measure response times and their variability (jitter), and automatically adjust timeouts 更好的是自动调节timeout according to the observed response time distribution