AMQP
RabbitMQ is a implementation of AMQP (Advanced Message Queueing Protocol) message model.
AMQP uses a remote procedure call to allow one computer to execute programs or methods on another computer(比如broker). Two way communication (both broker and client can use rpc to run programs or call each others). 和Object-oriented programing一样,rabbitmq use commands which consists of classes and methods to communicate between clients and brokers
AMQP (Advanced Message Queuing Protocol) is a standardized protocol used for asynchronous, secure, and reliable message exchange between applications. It enables systems to communicate and exchange messages in a way that’s robust, interoperable, and scalable.
Key aspects of AMQP:
- Interoperability: AMQP allows different applications, even those written in different programming languages, to communicate effectively.
- Asynchronous Communication: AMQP facilitates asynchronous messaging, where a sender can send a message without waiting for immediate acknowledgement from the receiver. This is achieved through message brokers and queues.
- Reliability: AMQP provides mechanisms for ensuring that messages are delivered reliably, even if there are network issues or errors.
- Security: AMQP supports secure communication through protocols like TLS.
- Routing and Queuing: AMQP uses message brokers, exchanges, and queues to route messages to the correct recipients.
- Open Standard: AMQP is an open standard defined by OASIS and ISO - International Organization for Standardization.
Components of AMQP:
- Message Brokers: AMQP relies on brokers to act as intermediaries between senders and receivers, handling message routing and delivery.
- Producer and Consumer
- Producer sends messages to the broker.
- Consumer receives messages from the broker.
- Exchanges: Exchanges are responsible for routing messages to queues based on predefined rules and bindings. A message routing agent in the broker.
- recieve messages and distribute how they’re addressed
- 可以连接many queues
- Queues: Queues act as storage for messages, allowing consumers to retrieve them at their own pace.
- Bindings: Bindings define the relationship between exchanges and queues, specifying how messages are routed. often with a routing key to filter messages
- Routing key: A string used to determine how messages are routed to queues.
- Messages: Messages are the data units exchanged between applications, containing both content and metadata.
- Delivery Guarantees. AMQP supports different delivery modes:
- At-most-once
- At-least-once
- Exactly-once (though this is complex and often simulated)
AMQP Frame type
- Method Frame: has class and method
- Content Header Frame
- Body Frame
- Heartbeat Frame
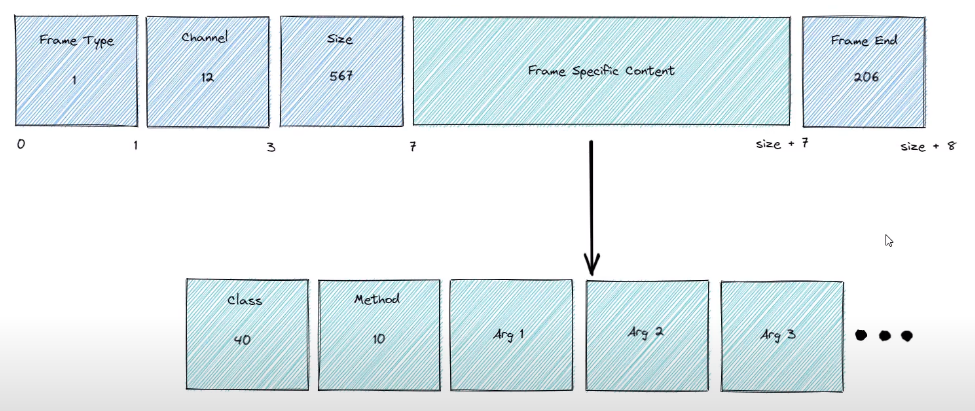
AMQP define exactly what should be contained each bytes of frame
40 表示exchange class, method 10 -> 表示declare method in exchange class
when sending or receiving a message through rabbitmq, the first frame always is a method frame which corresponds to sending/recieving method
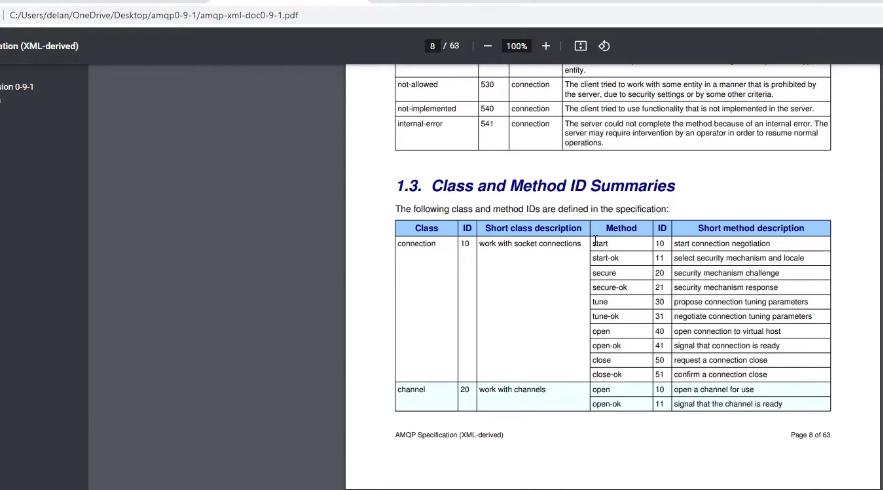
The doc for the AMQP specification gives a full which id for which methods and short description which methods do
| Frame | Frame | Description |
|---|---|---|
| Method | 1 | Carries AMQP commands like queue.declare, basic.publish, basic.consume, etc. |
| Header | 2 | Carries metadata about the message body, such as content type, delivery mode, and body size. |
| Body | 3 | Carries the actual message data (can be split across multiple body frames). |
| Heartbeat | 8 | Used to keep the connection alive and detect dead peers. |
| Heartbeat (reserved) | — | Sometimes shown separately, but technically type 8. |
| Frame End | — | Each frame ends with a constant byte 0xCE to mark the end of the frame. |
Key Concepts
- Producer: Application that sends the messages. sending messages to the RabbitMQ server
- Consumer: Application that receives the messages.reading and processing messages from queue
- Queue: In RabbitMQ, a Queue can be referred to as temporary or buffered storage of messages, RabbitMQ manages a queue, where messages are stored before they are consumed by the receiver. Queues can have the nature of durable or transient which means persisting across restarts and deleted when the server restarts respectively.
- Connection: A TCP connection between your application and the RabbitMQ broker.
- Channel: Lightweight connections that share a single TCP connection. Publishing or or consuming messages from a queue is done over a channel.
- Exchange:
- An exchange is responsible for routing messages among queues. RabbitMQ provides support for various kinds of exchanges such as direct, fanout, topic, and headers, each queue with its logic.
- Direct Exchange: In this exchange, messages are being routed based on routing keys. This means that when the routing key matches the binding key, the message gets delivered to its corresponding queue.
- Fanout Exchange: With this exchange, RabbitMQ does the broadcasts to all messages that are bound to it regardless of the routing key.
- Topic Exchange: With topic exchange message routing happens based on pattern matching to the routing and binding key. Routes to queues based on pattern matching (*.error, app.#). Routing key and binding keys可以是partial matches
- Headers Exchange: In this route messages are based on headers instead of the routing key. The headers exchange is more flexible but less efficient compared to other exchange types.
- Default exchange: not AMQP, 只是rabbitmq support, The routing is tied with name of exchange. 比如 routing key 是 “inv”, 有个queue name是 “inv”, route to there
- Receives messages from producers and pushes them to queues depending on rules defined by the exchange type. A queue must be bound to at least one exchange to receive messages.
- An exchange is responsible for routing messages among queues. RabbitMQ provides support for various kinds of exchanges such as direct, fanout, topic, and headers, each queue with its logic.
- Binding: Bindings are rules that exchanges use (among other things) to route messages to queues.
- Routing key: In RabbitMQ a** connection between queue and exchange is called binding**. The message route from the exchange to the queue is defined by binding based on specific criteria such as routing keys. A key that the exchange uses to decide how to route the message to queues. Think of the routing key as an address for the message.
- Users: It is possible to connect to RabbitMQ with a given username and password. Users can be assigned permissions such as rights to read, write, and configure privileges within the instance. Users can also be assigned permissions for specific virtual hosts.
- Vhost, virtual host: Virtual hosts provide logical grouping and separation of resources. Users can have different permissions to different vhost(s), and queues and exchanges can be created so they only exist in one vhost.
How RabbitMQ Works
In the first step, the producer sends a message to RabbitMQ and the exchange receives the message. Then the exchange routes the message to one or more queues based on the routing key and exchange typ3. Once the message is in the queue, it waits for the consumer to receive and process it. Once the process starts, the consumer sends an acknowledgment to RabbitMQ which indicates that the message has been handled successfully. In case of no acknowledgment, RabbitMQ may resend the message to ensure the successful full process of the message.
RabbitMQ provides support for multiple messaging patterns such as Point-to-Point, Publish/Subscribe, and Request/Reply.
- Point-to-Point: In this pattern, one producer sends the message to only one queue, which will be consumed by one consumer only.
- Publish/Subscribe: In this pattern, the producer sends the message to an exchange, which routes to multiple queues. Here each queue can have one or more consumers.
- Request/Reply: Here, the consumer processes the message that it has received and sends a response back to the producer, this can be referred to as two-way communication also.
Advantages of using RabbitMQ
After looking at the introduction and the way RabbitMQ works, now let’s take a deep dive into the advantages of using RabbitMQ.
- Reliable: RabbitMQ supports mechanisms such as message durability, acknowledgment, and persistence to make sure that messages are not lost even if the server crashes.
- Scalable: RabbitMQ is capable of handling thousands of messages per second, which makes it well-suited for large-scale applications(distributed systems). With the support of clustering, multiple RabbitMQ servers can work together to increase capability and capacity.
- 是async 不是sync, Synchronous messaging is possible but impacts scalability. If a publisher has to wait for its recipients to respond, then it will be limited in how much it can achieve at any given time.
- Flexible: With multiple messaging pattern support, RabbitMQ can be used for multiple use cases. It can also be integrated with multiple protocols such as AMQP, MQTT, and STOMP.
- Easy to use: RabbitMQ offers a user-friendly web-based interface that allows users to monitor queues and exchanges in real time. It provides client libraries for various programming languages such as Java, Python, and Node.js.
- Strong community support: RabbitMQ has a large and active community with rich documentation and tutorials. It is backed by commercial support from Pivot Software, which ensures that users can get help when needed.
对于其他的queue, broker administrator define in message model how message moves (all defined), but within RabbitMQ, the moves through the system is largely a part of the message metadata. 是Application and developer that has a lot of control how message move through the system
Another benefits of RabbitMQ is cloud friendly, 可以deploy an instance in docker or container software. It can also run as cluster, fault tolerant, high available, and high throughput
across language
it support message acknowledgement. When a message in a queue and goes to consumer, the message stays in the queue until the consumer lets the broker know that it has recieved the messeges.
Channel
In RabbitMQ, a channel is a virtual connection inside a TCP connection (also called a connection). It is a lightweight way for clients to communicate with the broker without opening multiple actual network connections.
Why Channels Exist
Opening a full TCP connection to RabbitMQ is expensive (in terms of resources). So instead of creating a new connection for every producer or consumer:
- A single TCP connection is opened.
- Multiple channels are created over that connection to handle different tasks in parallel (e.g., publishing and consuming).
| Property | Description |
|---|---|
| Lightweight | Much less overhead than creating a new TCP connection. |
| Isolated | Errors on one channel don’t affect others on the same connection. |
| Concurrency | Multiple producers/consumers can operate simultaneously via separate channels. |
| Scoped | AMQP commands (e.g., declaring a queue, publishing) are always done over a channel. |
| Mandatory | Every RabbitMQ operation (publish, consume, declare queue/exchange) must be done via a channel. |
install rabbitmq
https://www.rabbitmq.com/docs/install-homebrew
brew update
brew install rabbitmq
Running and Managing the Node
Starting a Node In the Foreground
CONF_ENV_FILE="/opt/homebrew/etc/rabbitmq/rabbitmq-env.conf" /opt/homebrew/opt/rabbitmq/sbin/rabbitmq-server
After starting a node, we recommend enabling all feature flags on it:
# highly recommended: enable all feature flags on the running node
/opt/homebrew/sbin/rabbitmqctl enable_feature_flag all
Starting a Node In the Background
# starts a local RabbitMQ node
brew services start rabbitmq
# highly recommended: enable all feature flags on the running node
/opt/homebrew/sbin/rabbitmqctl enable_feature_flag all
Stopping the Server
# stops the locally running RabbitMQ node
brew services stop rabbitmq
or CLI tools directly:
/opt/homebrew/sbin/rabbitmqctl shutdown
Python Implementation
producer.py
import pika
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
#don't directly interact with the connection, use a channel instead
channel = connection.channel()
channel.queue_declare(queue="letterbox")
#use default exchange
message = "Hello. this is my first message"
# exchange="" means the default exchange
channel.basic_publish(exchange="", routing_key="letterbox", body=message)
print(f"Sent message: {message}")
# Close the connection
connection.close()
consumer.py
import pika
def on_message_recieved(ch, method, properties, body):
print(f"Received message: {body.decode()}")
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
#don't directly interact with the connection, use a channel instead
channel = connection.channel()
# Even though we declare in both producer and consumer, but rabbitMQ brokers knows decalre the queue once
channel.queue_declare(queue="letterbox")
#use default exchange
channel.basic_consume(queue="letterbox", on_message_callback=on_message_recieved, auto_ack=True)
# when pull off from the queue, it automatically ack and no manually do that
print("start consuming messages")
channel.start_consuming()
# Close the connection
# connection.close() # Not needed here as we are consuming messages indefinitely
Web Dashboard
Go to http://localhost:15672/
Enter username and password, both guest
AMQP RabbitMQ
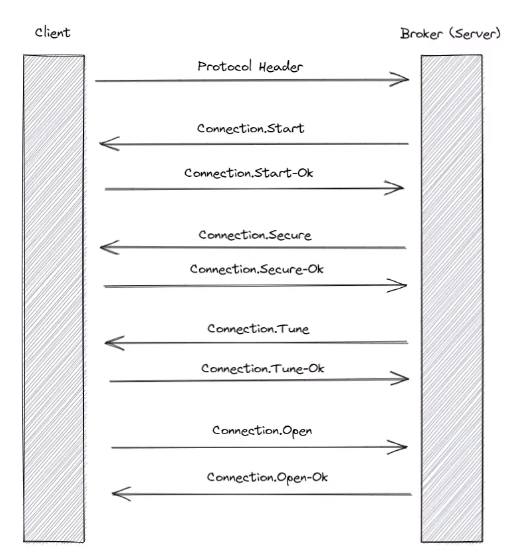
在connection 开始发送protocol header, only data not formatted. The protocol 通常是 AMQP + constant + protocol major version + protocol minor version + protocol revision.
- Then server either accept or reject protocol header.
- 如果是reject, write a valid protocol header to the open TCP socket, and close the socket. 如果是accept socket, it implements the protocol accordingly and responding with the connection start method frame. .
- 当client recieve this, client select SLA scruty and respond connection start ok method frame.
- Next server will send client a **connection secure **method,the SLA protocol by exchanging chanllenges and response until both peers have recieved sufficient information to authenticate each other. The connection secure method chanllenges the client to provide more information.
- Once authenicated on both side, server will send a connection tune method frame to the client. The connection tune method data contains various different pieces of information around sever connections. 比如maximum channel supported, the max frame size supported, and the desired heartbeat delay
- client respond a connection tune ok method frame 包括了details around negotiated max number of channels, maximum frames and heartbeat delay.
- Final is to open connection itself by sending the server connection open method frame. Then server responds with a connection openok method frame which signals to the client that the connection is ready for use. Can see connection negotiation and opening process. The communication between the client and broker is mostly sync. This is different than consuming messages from the broker.
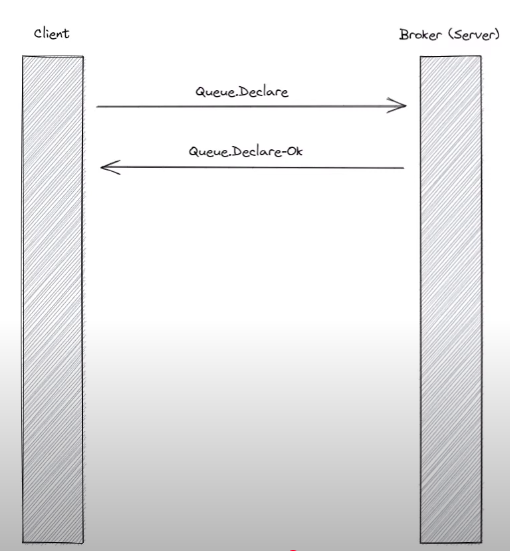
Once open a connection to broker or the server, may perform different actions 比如creating exchanges or queues or binding queues to exchanges. This is done by various different method frames from client to server. 如果queue was declared and created successfully, the server will respond with a q.declare ok method frame. 如果有error when create queue, rabbitmq will close the channel that rpc request was issued on.
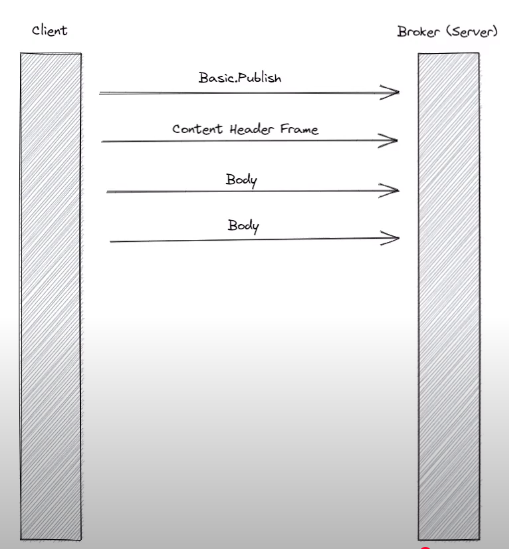
send basic publish frame then send content header frame (包括details 比如size of messages). Finally send one or more body frames, which makes the actual content of message. The number of body frames required depends on both size of message and maximum size supported by the connection by RabbitMQ.
Recieving messages: two main approaches
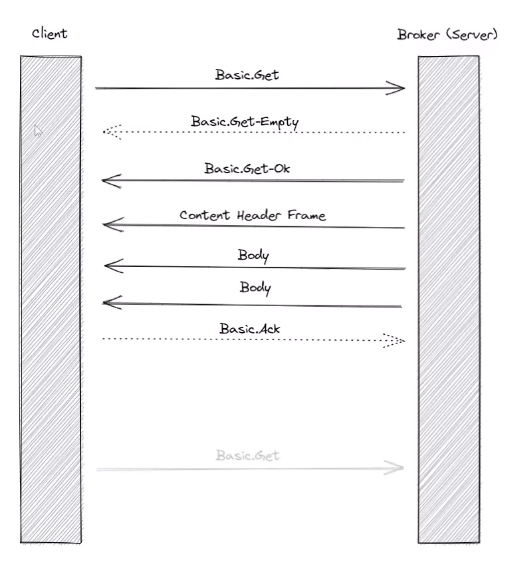
- basic get method: provide direct access to the messages in a queue sync.
- server respond
Get-Empty(如果没有) orGet-Okmethod - followed by the message which contain a content header frame and a number of body frame depending on the size of messages.
- client then respond with a basic_ack the receipt of the message (除非设置不需要ack)
- not ideal for rabbitmq recieving messages. We should consume them not getting them
- server respond
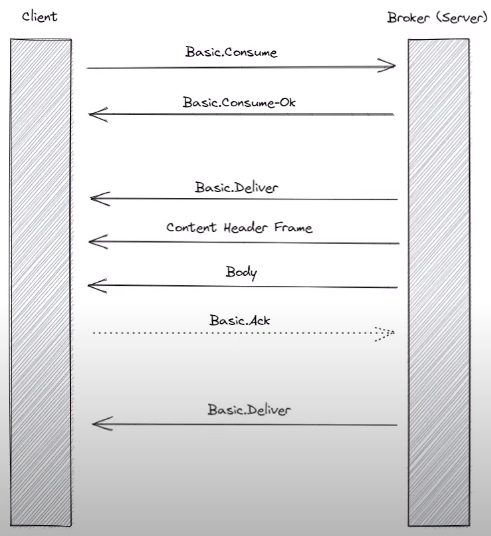
- basic consume method: start to ask consumer which is a transient request for messages from a specific queue. Consumer last as long as the channel declared on or client cancel them
- broker respond Basic
consume-okbasic frame. 当messages arrive for that consumer, consumer send a basic deliver to the client. Followed by a header frame and a number of body frames - client should ack messages recieved (除非no ack required)
- this continue until channel close or client cancel consume
- broker respond Basic
Competing Consumers
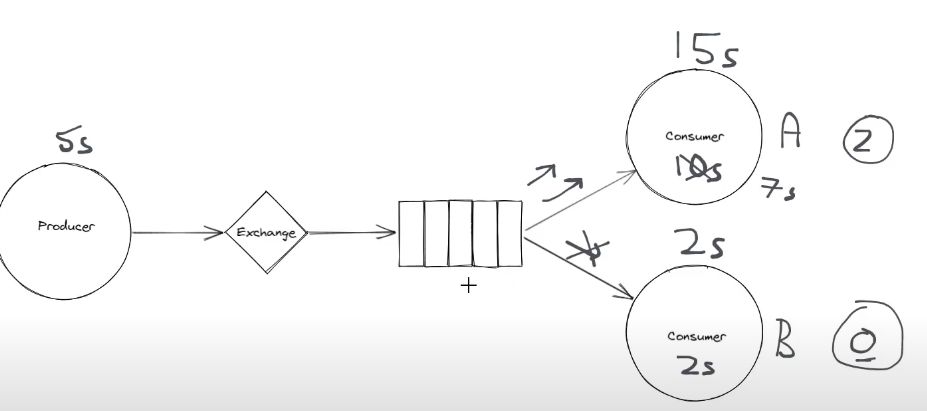
what if consumer processing speed < producer write speed. More message fill up in the queue and cause trouble on broker as each message in the queue will take up a bit memory on sever. By default, rmq use round robin manner.
This gives some benefits in terms of scability and reliable.
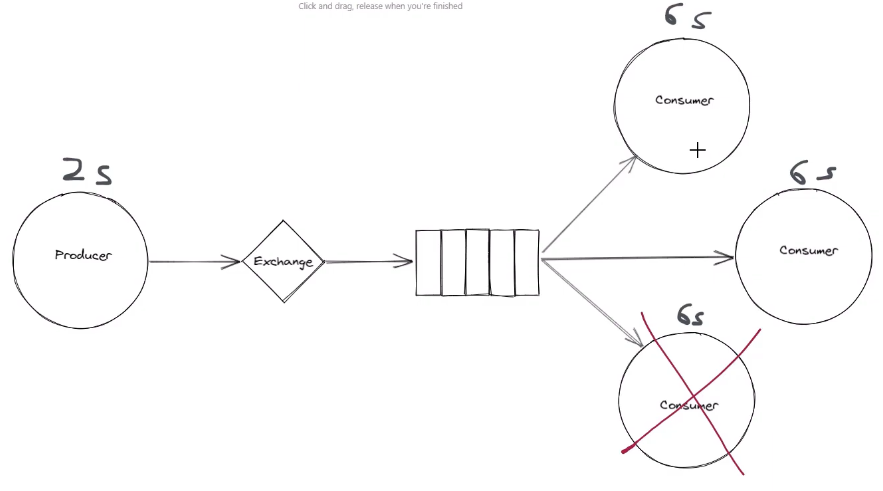
比如其中一个node goes down, no longer process messages, still have other consumers
producer.py: use default exchange, no need to declare exchange
import pika
import time
import random
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
#don't directly interact with the connection, use a channel instead
channel = connection.channel()
channel.queue_declare(queue="letterbox")
#use default exchange
messageID = 1
while True:
message = f"Sending Message {messageID}"
# exchange="" means the default exchange
channel.basic_publish(exchange="", routing_key="letterbox", body=message)
print(f"Sent message: {message}")
time.sleep(random.randint(1, 4)) # Simulate processing time
messageID += 1 # Increment message ID
consumer.py
import pika
import time
import random
def on_message_recieved(ch, method, properties, body):
processing_time = random.randint(1, 6)
print(f"Received message: {body.decode()}, will take {processing_time} seconds to process")
time.sleep(processing_time) # Simulate processing time
ch.basic_ack(delivery_tag=method.delivery_tag) # Acknowledge the message
print('Finish processing message')
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
#don't directly interact with the connection, use a channel instead
channel = connection.channel()
# Even though we declare in both producer and consumer, but rabbitMQ brokers knows decalre the queue once
channel.queue_declare(queue="letterbox")
#use default exchange
channel.basic_qos(prefetch_count=1) # Fair dispatch, process one message at a time,
# 如果移走这个,remove fair dispatch mechanism (有的queue没有完成,还在继续assign给它 =》 use roundbin 不efficient)
channel.basic_consume(queue="letterbox", on_message_callback=on_message_recieved)
print("start consuming messages")
channel.start_consuming()
# Close the connection
# connection.close() # Not needed here as we are consuming messages indefinitely
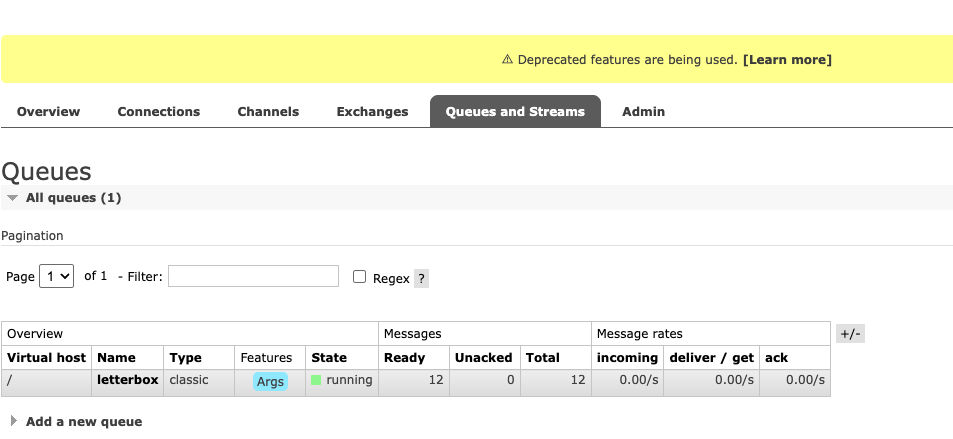
如果开一个producer 和 一个consumer, 可以看见queue increase
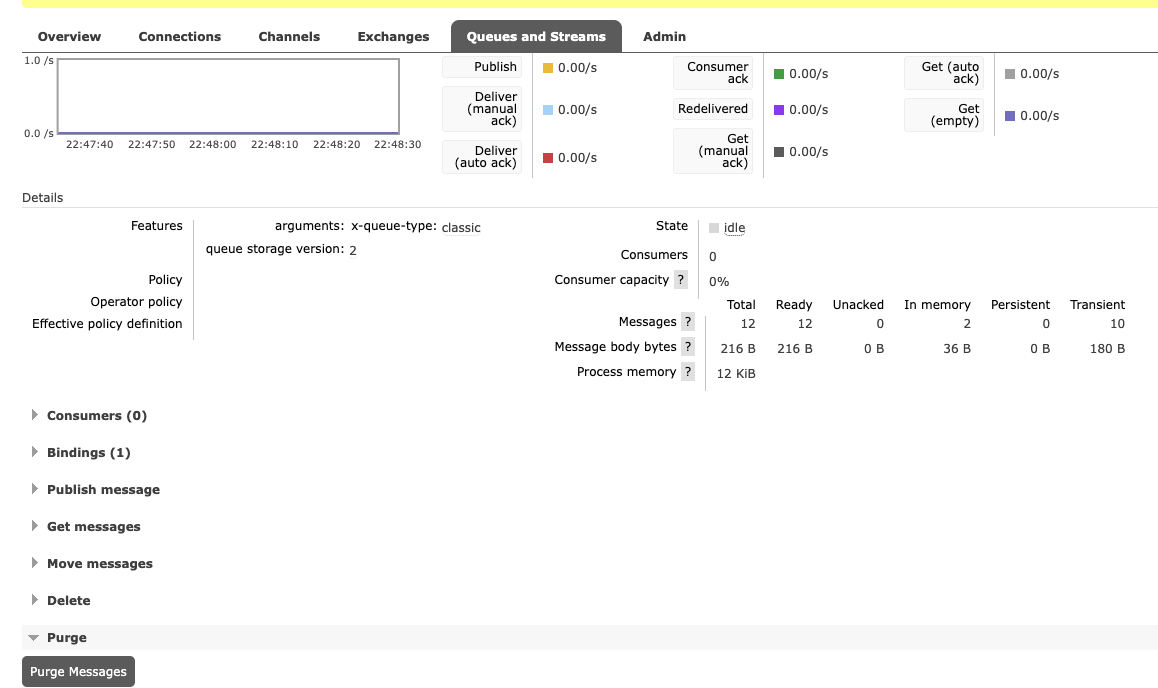
purge queue: click the name of queue (比如letterbox), click purge messages
开多个consumer, 开几个terminal tab同时run
Pub/Sub
deliver message to multiple consumers (fan-out exchange), to multiple different queue (Memory used by rabbitmq doesn’t store multiple copies of messages, just store once, and each queue store a reference to that message)
Completely decoupling our producer from our downstream service. Producer doesn’t care if 0 services are consuming messages or if hundreds of services consuming messages. It will continue to publish them and the fan-out exchange will take care who is interested in
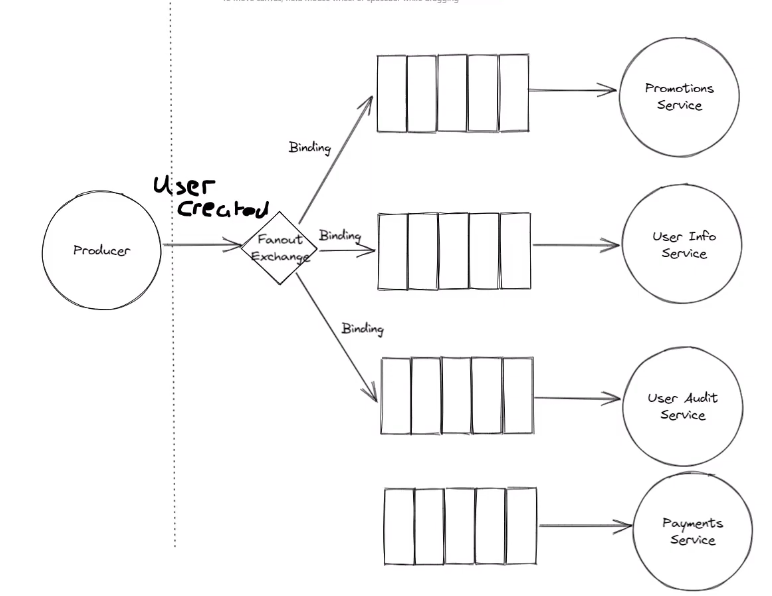
bind each queues to the exchange. The fanout exchange use these bindings to know what queues are interested in message in question. 上图是3 queue, 3 bindings => each messages will send to each queue
可以使用temporary queue, no need to specifically declare these queues upfront
producer.py
import pika
import time
from pika.exchange_type import ExchangeType
import random
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
#don't directly interact with the connection, use a channel instead
channel = connection.channel()
#channel.queue_declare(queue="letterbox")
# producer doesn't need to declare the queue, as each consumer has dedicated queue created by itself
#use default exchange
#declare fanout exchange
channel.exchange_declare(exchange='pubsub', exchange_type='fanout')
# exchange = '' 是给一个命名,不是种类,也可以命名pubsub123
message = f"I want to boadcast this message"
# exchange="" means the default exchange
channel.basic_publish(exchange="pubsub", routing_key="", body=message)
print(f"Sent message: {message}")
connection.close()
firstConsumer.py
import pika
def on_message_recieved(ch, method, properties, body):
print(f"first consumer Received message: {body.decode()}, ")
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
#don't directly interact with the connection, use a channel instead
channel = connection.channel()
channel.exchange_declare(exchange='pubsub', exchange_type='fanout')
queue = channel.queue_declare(queue="", exclusive=True) # Declare a unique queue for this consumer
# Queue = "", server randomly choose the name of the queue
# exclusive=True means the queue will be deleted when the consumer disconnects
# use default exchange
channel.queue_bind(exchange='pubsub', queue=queue.method.queue)
# Bind the queue to the exchange, otherwise it may not receive messages
channel.basic_qos(prefetch_count=1) # Fair dispatch, process one message at a time
channel.basic_consume(queue=queue.method.queue, auto_ack=True, on_message_callback=on_message_recieved)
print("start consuming messages")
channel.start_consuming()
# Close the connection
# connection.close() # Not needed here as we are consuming messages indefinitely
secondConsumer.py
import pika
def on_message_recieved(ch, method, properties, body):
print(f"second consumer Received message: {body.decode()}, ")
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
#don't directly interact with the connection, use a channel instead
channel = connection.channel()
channel.exchange_declare(exchange='pubsub', exchange_type='fanout')
queue = channel.queue_declare(queue="", exclusive=True) # Declare a unique queue for this consumer
# Queue = "", server randomly choose the name of the queue
# exclusive=True means the queue will be deleted when the consumer disconnects
#use default exchange
channel.queue_bind(exchange='pubsub', queue=queue.method.queue)
# Bind the queue to the exchange, otherwise it may not receive messages
channel.basic_consume(queue=queue.method.queue, auto_ack=True, on_message_callback=on_message_recieved)
print("start consuming messages")
channel.start_consuming()
# Close the connection
# connection.close() # Not needed here as we are consuming messages indefinitely
Routing
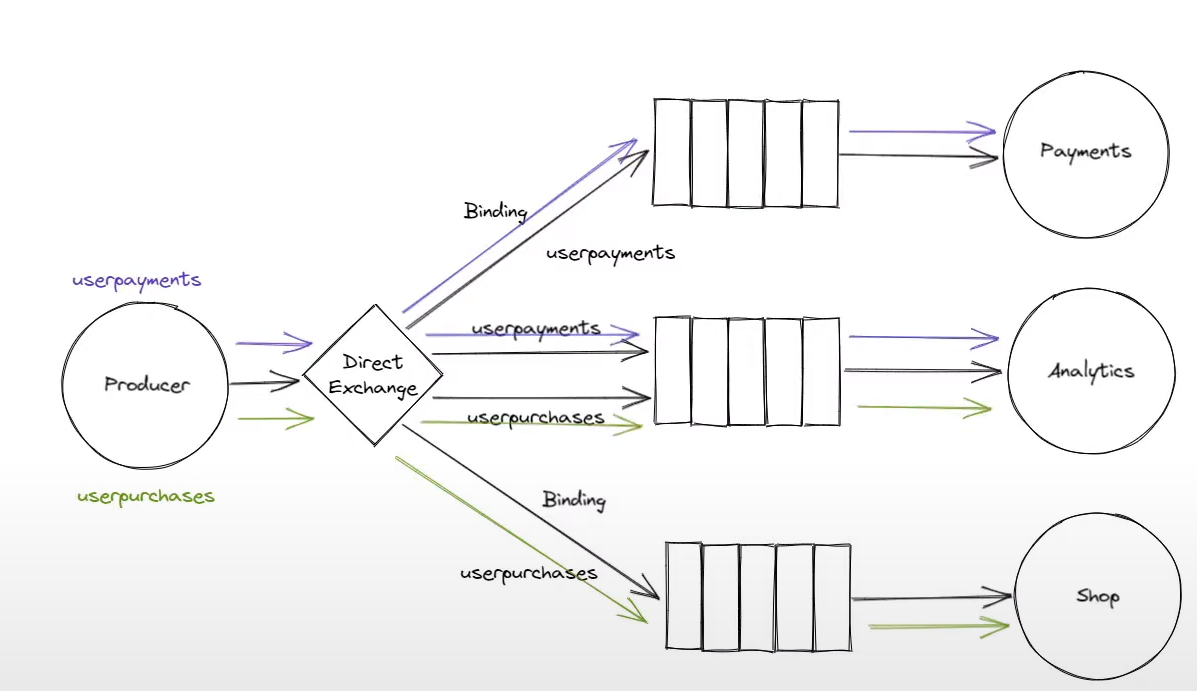
- Direct Exchange: use binding keys and routing keys to route the message
- 比如publish a message to direct exchange, message routing key 必须和binding key 一样才可以
- 多个queue 可以bound to the direct exchange using the same binding key
- A single queue 可以有多个bindings (比如上图中间的example, 两个binding keys) => Give great flexibility how to route the messages
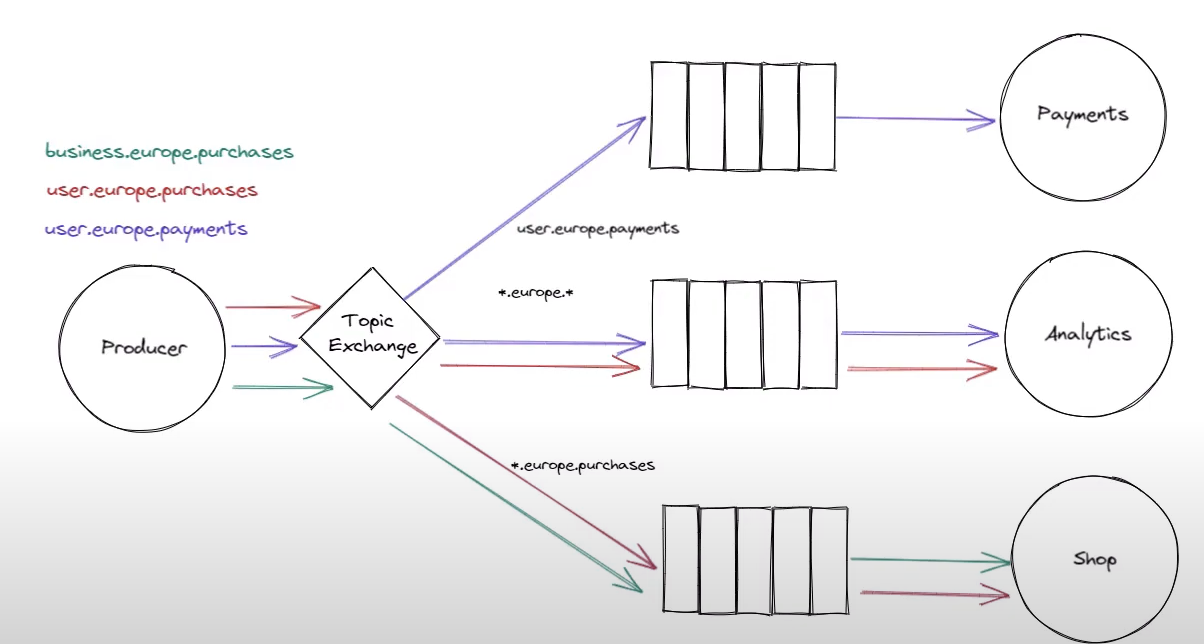
- Topic exchange: 不能有arbitrary routing keys, it must be a list of words delimited by dots.
- 也需要binding keys, pass by routing keys
*表示 exactly one word, or#表示zero or more words- 比如
user.europe.*表示user.europe开始加上任何一个词, 比如user.europe.payment user.#可以是以user开始的任何词, 可以是user, 可以是user.eruope, 也可以是user.europe.payment
- 比如
- Achieve interesting flexibility
Direct Exchange
producer.py
import pika
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
#don't directly interact with the connection, use a channel instead
channel = connection.channel()
# producer doesn't need to declare the queue, as each consumer has dedicated queue created by itself
#use default exchange
#declare exchange
channel.exchange_declare(exchange='routing', exchange_type='direct')
# exchange = '' 是给一个命名,不是种类,也可以命名routing123
message = f"This analytics message needs to be routed"
# exchange="" means the default exchange
channel.basic_publish(exchange="routing", routing_key="analytics", body=message)
print(f"Sent message: {message}")
message = f"This message needs to be routed"
# exchange="" means the default exchange
channel.basic_publish(exchange="routing", routing_key="both", body=message)
print(f"Sent message: {message}")
connection.close()
analyticConsumer.py
import pika
def on_message_received(ch, method, properties, body):
print(f"analytics consumer Received message: {body.decode()}")
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
channel = connection.channel()
channel.exchange_declare(exchange='routing', exchange_type='direct')
queue = channel.queue_declare(queue="", exclusive=True)
channel.queue_bind(exchange='routing', queue=queue.method.queue, routing_key='analytics')
channel.queue_bind(exchange='routing', queue=queue.method.queue, routing_key='both')
channel.basic_consume(queue=queue.method.queue,
auto_ack=True, on_message_callback=on_message_received)
print("Analytics Start Consuming")
channel.start_consuming()
paymentConsumer.py
import pika
def on_message_recieved(ch, method, properties, body):
print(f"payments consumer Received message: {body.decode()}")
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
channel = connection.channel()
channel.exchange_declare(exchange='routing', exchange_type='direct')
# 不一定非要是routing, 可以是别的名字,routing命名只是说我们定义一个routing
queue = channel.queue_declare(queue="", exclusive=True)
# queue="" allow server to assign random queue to it
# exclusive=True means the queue will be deleted when the consumer disconnects
channel.queue_bind(exchange='routing', queue=queue.method.queue, routing_key='paymentsonly')
channel.queue_bind(exchange='routing', queue=queue.method.queue, routing_key='both')
channel.basic_consume(queue=queue.method.queue, auto_ack=True,
on_message_callback=on_message_recieved)
print("start consuming")
channel.start_consuming()
Topic Exchange
producer.py
import pika
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
#don't directly interact with the connection, use a channel instead
channel = connection.channel()
# producer doesn't need to declare the queue, as each consumer has dedicated queue created by itself
#use default exchange
#declare exchange
channel.exchange_declare(exchange='mytopicexchange', exchange_type='topic')
message = f"This analytics message needs to be routed"
# exchange="" means the default exchange
channel.basic_publish(exchange="mytopicexchange", routing_key="user.analytics", body=message)
print(f"Sent message: {message}")
message = f"This message needs to be routed"
# exchange="" means the default exchange
channel.basic_publish(exchange="mytopicexchange", routing_key="user.user.end", body=message)
print(f"Sent message: {message}")
connection.close()
userConsumer.py
import pika
def on_message_received(ch, method, properties, body):
print(f"user consumer Received message: {body.decode()}")
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
channel = connection.channel()
# use topic exchange
channel.exchange_declare(exchange='mytopicexchange', exchange_type='topic')
queue = channel.queue_declare(queue="", exclusive=True)
channel.queue_bind(exchange='mytopicexchange', queue=queue.method.queue, routing_key='user.#')
channel.basic_consume(queue=queue.method.queue,
auto_ack=True, on_message_callback=on_message_received)
print("User Start Consuming")
channel.start_consuming()
Request Reply Pattern
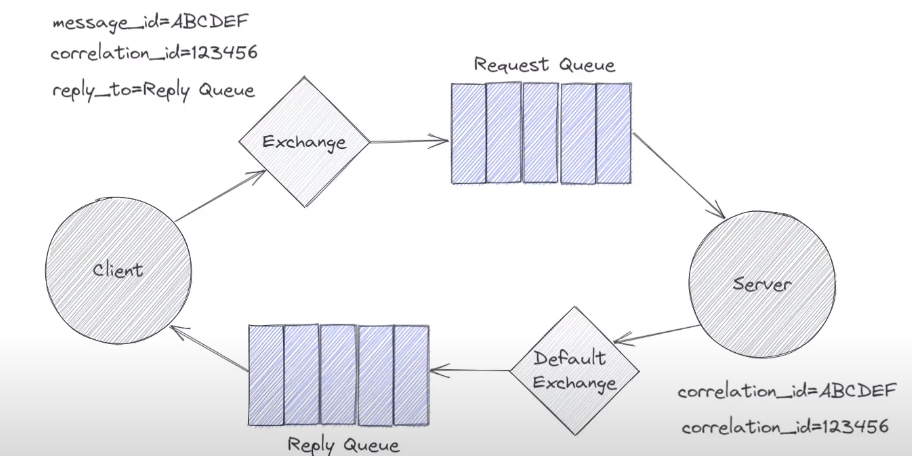
如果both service both consuming and publishing request, 不叫producer or consumer. First thing client do, declare the queue that wants to receive replies for requests on. The client will process all the messages sent to this queue from the server as a response to a previously sent request. Then publish the request onto an exchange (可以是各种). Exchange put requst on request queue. Server read requests from request queue and process them. Once finish process, send reply back to the client. Does this by publishing onto the reply queue using default exchange.
How does server know which reply queue to send to from server. It is needed to specify by the client (by reply_to property)
如果有多个request, send to 多个reply queue, How does client know which reply is for which request. Can tag some metadata on the request which uniquely identified the request. Then server can tag this metadata also on the reply so the client so the client can coordiante which reply for which request (correlation_id property often used )
Often we have unique message id per message. So client send a message to the exchange with a unique message id. 当server收到,population correlation_id using message_id => allow client to uniquely identify which reply is for which request. Alternative approach is just to use the same correlation_id got from request
client.py
import pika
import uuid
def on_reply_message_received(ch, method, properties, body):
print(f"Received reply message: {body.decode()}")
connection_parameter = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameter)
channel = connection.channel()
reply_queue = channel.queue_declare(queue="", exclusive=True)
# exclusive=True means the queue will be deleted when the consumer disconnects
# exclusive=True: only allow access by the current connection
channel.basic_consume(queue=reply_queue.method.queue, auto_ack=True,
on_message_callback=on_reply_message_received)
channel.queue_declare(queue='request-queue')
message = "Can I request a reply?"
cor_id = str(uuid.uuid4)
print(f"Sent Request:cor_id= {cor_id}")
channel.basic_publish(
exchange="",
routing_key="request-queue",
properties = pika.BasicProperties(
reply_to=reply_queue.method.queue,
correlation_id=cor_id
),
body=message
)
print("starting client")
channel.start_consuming()
server.py
import pika
def on_request_message_received(ch, method, properties, body):
print(f"server Received message: cor_id = {properties.correlation_id} body = {body.decode()}")
ch.basic_publish('', routing_key=properties.reply_to,
body=f"Reply to \"{body.decode()}\" cor_id = {properties.correlation_id}")
# no need to generate correlation_id in server, it is generated by client
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
channel = connection.channel()
channel.queue_declare(queue='request-queue')
# just in case if server starts before the client
channel.basic_consume(queue='request-queue', auto_ack=True,
on_message_callback=on_request_message_received)
print("Start Server")
channel.start_consuming()

Exchange
Exchange to Exchange

Direct Exchange first route based on routing key. Then use fanout exchange to route the message
consumer.py
import pika
def on_message_recieved(ch, method, properties, body):
print(f"Received message: {body.decode()}, ")
connection_parameter= pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameter)
channel = connection.channel()
channel.exchange_declare(exchange='secondexchange', exchange_type='fanout')
channel.queue_declare(queue='letterbox')
channel.queue_bind(exchange='secondexchange', queue='letterbox')
channel.basic_consume(queue='letterbox',
auto_ack=True,
on_message_callback=on_message_recieved)
print("Start consuming")
channel.start_consuming()
producer.py
import pika
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
#don't directly interact with the connection, use a channel instead
channel = connection.channel()
channel.exchange_declare(exchange='firstexchange', exchange_type='direct')
channel.exchange_declare(exchange='secondexchange', exchange_type='fanout')
channel.exchange_bind('secondexchange', source='firstexchange')
message = "This message go through multiple exchanges"
channel.basic_publish(exchange='firstexchange', routing_key='', body=message)
# producer doesn't need to declare the queue, as each consumer has dedicated queue created by itself
#use default exchange
#declare exchange
print(f"sent message: {message}")
connection.close()

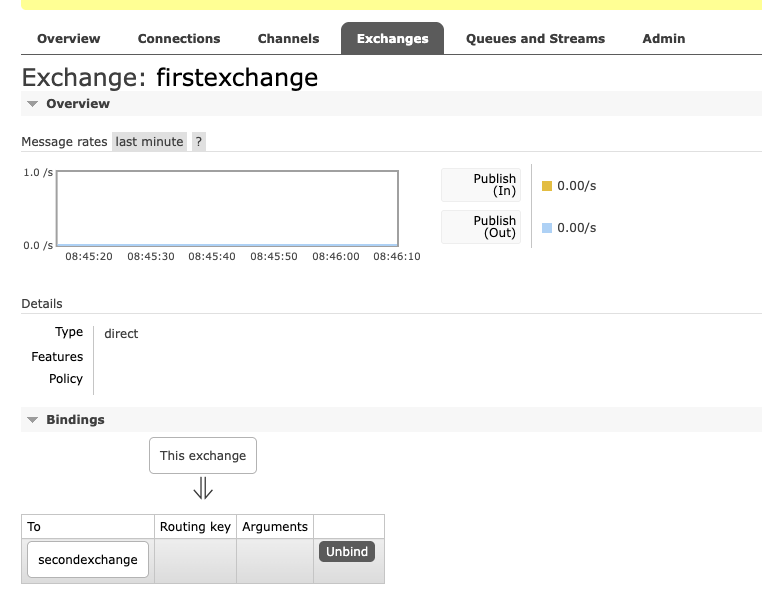
first exchange binds to the second exchange
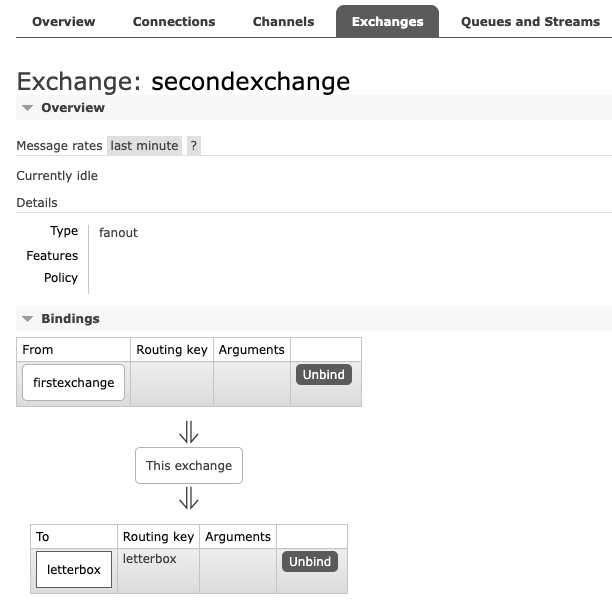
second exchange binds to the letterbox queue
Header Exchange
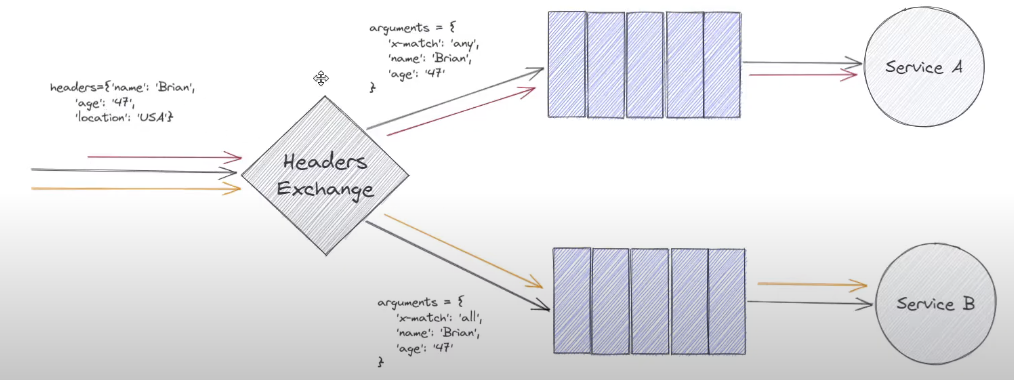
use header table to decide how to route message instead of routing key
x-match: any: tells the header exchange that in order for a message to be routed from headers exchange to the queue connected to service a. One of the headers on the header either name: Brian or age:47 matches, the message will be routed successfully to the queue connected to the service a.
另一个是 x-match: all. 必须所有的header都match了才能是真的match. 只要要求的所有header 都match即可,如果message has more header, 也没有问题。
consumer.py
import pika
def on_message_recieved(ch, method, properties, body):
print(f"Received message: {body.decode()}, ")
connection_parameter= pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameter)
channel = connection.channel()
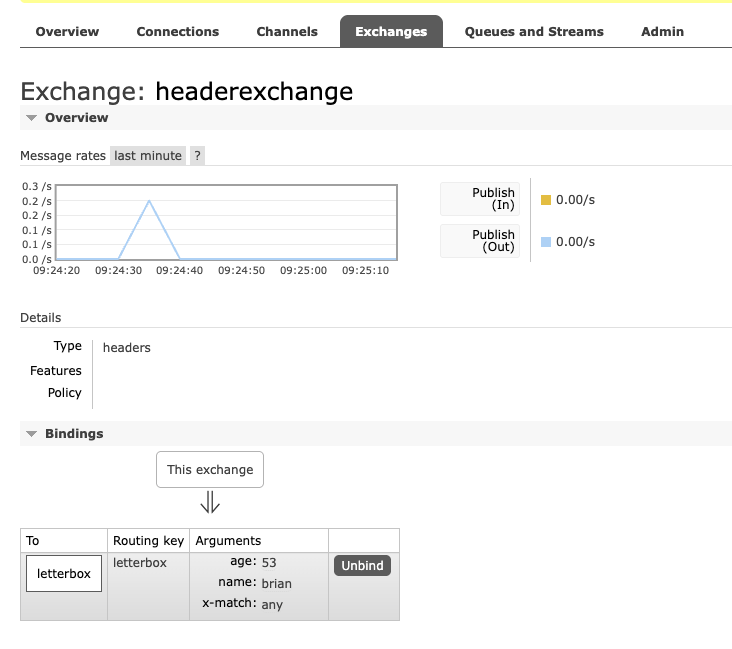
channel.exchange_declare(exchange='headerexchange', exchange_type='headers')
channel.queue_declare(queue='letterbox')
bind_args = {
'x-match': 'all', # Match any headers
'name': 'brian',
'age': 53,
}
channel.queue_bind(exchange='headerexchange', queue='letterbox', arguments=bind_args)
channel.basic_consume(queue='letterbox',
auto_ack=True,
on_message_callback=on_message_recieved)
print("Start consuming")
channel.start_consuming()
producer.py
import pika
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
#don't directly interact with the connection, use a channel instead
channel = connection.channel()
channel.exchange_declare(exchange='headerexchange', exchange_type='headers')
message = "This message go through header exchanges"
channel.basic_publish(
exchange='headerexchange',
routing_key='',
body=message,
properties=pika.BasicProperties(
#headers={'x-match': 'all', 'type': 'text', 'format': 'plain'}
headers={'name': 'brian'}
),
)
# producer doesn't need to declare the queue, as each consumer has dedicated queue created by itself
#use default exchange
#declare exchange
print(f"sent message: {message}")
connection.close()

Consistent Hashing Exchange
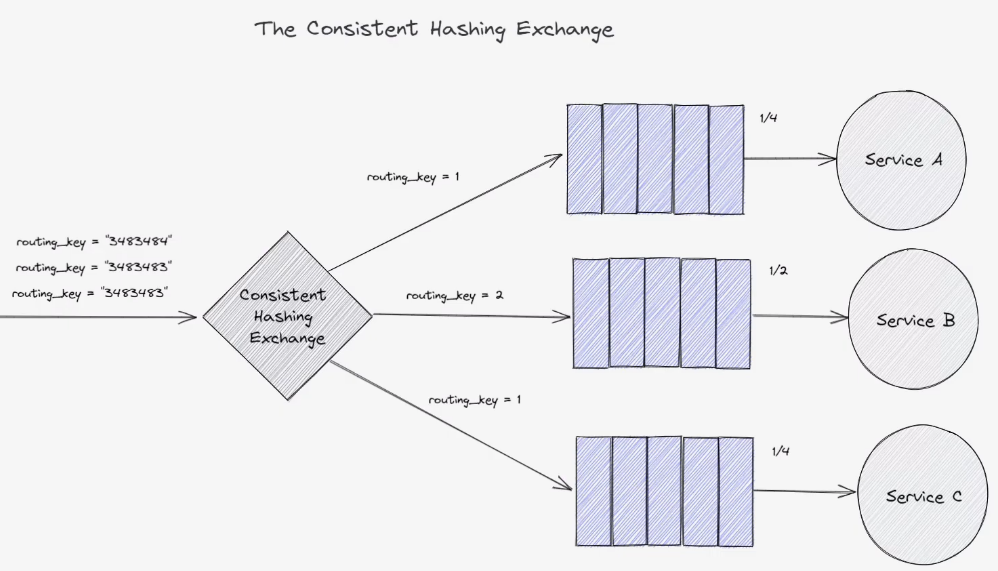
equally distribute service. Consistent hashing exchange, a simple numeric value 决定what proporiting of messages should be sent to the queue from the hashing exchange
- 比如 所有的
routing_key=1tell consistent hashing exchange to treat all queues equal - 如果 有一个queue的
routing_key=2其他的queue 都是routing_key=1,tell this queue to recieve twice the messages as usual.- Essential doing is doubling the hash space that is allocated to the queue to service b than service a 和 c
- when a message comes in, set it routing key, then the routing key hashed by the consistent hashing exchange. The hash is then assigned to one or more queues based on where it falls in to the hash space
- if we send another message with the routing key as before => that message 一定会被routed 到之前的queue
- 如果改变routing key, 可能会被发到完全不同的queue
- 如果add additional queue,need to be careful, 可能会screw hash space
Publish Option

RMQ gives a custom header datat structure where w ecan add user defined key value pairs
ContentType: allow consumer to determinte the type without examining message bodyContentEncoding: tell consumer what encoding standard the message is usinguserID: 如果不是the same userID as logged in user, RMQ will reject message.DeliveryMode:- 1: message should be persisted to disk before sent to consumers. Can improve reliability published messages won’t lost before consume. It also leads latency and consume hardware resource
- 0: doesn’t need to be persisted to disk
Expiration: 告诉RMQ to discard if not consumed after a certain period. use it to free up memory in system as out of date or irrelevant messages

- The fastest but least: not guarantee delivery. no confirmation that message has been successfully or unsuccessfully routed to consumer
- 第二快的, mandatory flag: only notify us if a message failed to be routed (只有failed to route会被 notify)
- 第三快, publisher confirms (set at channel level). All message sent on a channel when this is enabled will be published using this setting => force RMQ respond with an ack that the message was successfully published (on all queues it published or successfully persist).No guarantee of when it will be consumed
- Transactions: gives a guarantee that a batch of messages have been committed to a queue or else rolled back
- 如果affect more than 1 queues, won’t be atomic => all messages published or none of published
- 因为decouple nature, publisher 不知道多少consumer, transaction often used with caution
- slow speed best relability: persist messages by sending delivery mode as 1
- queue durable: the queue existence will survive a reboot of the message broker, 如果把queue durable 和 persistent message 一起用, 最高的reliability at a sacrifice of significant speeds (必须用SSD 才可以)
use it in producer.py
import pika
connection_parameters = pika.ConnectionParameters("localhost")
connection = pika.BlockingConnection(connection_parameters)
#don't directly interact with the connection, use a channel instead
channel = connection.channel()
#Enable Publish confirms
channel.confirm_delivery()
#Enable Transactions
#channel.tx_select()
channel.exchange_declare(exchange='headerexchange', exchange_type='headers')
# Creates a durable queue that survives server restarts
channel.queue_declare(queue='letterbox', durable=True)
message = "This message go through header exchanges"
channel.basic_publish(
exchange='headerexchange',
routing_key='',
body=message,
properties=pika.BasicProperties(
#headers={'x-match': 'all', 'type': 'text', 'format': 'plain'}
headers={'name': 'brian'},
# deliverymode
delivery_mode=1,
#expiration time
expiration=17889890,
content_type='application/json',
),
# Set the publish to mandatory - i.e. receive a notification of failure
mandatory=True,
)
# Commit a transaction
channel.tx_commit()
# Uncomment the line below to rollback a transaction
channel.tx_rollback()
#declare exchange
print(f"sent message: {message}")
connection.close()
Alternate Exchange
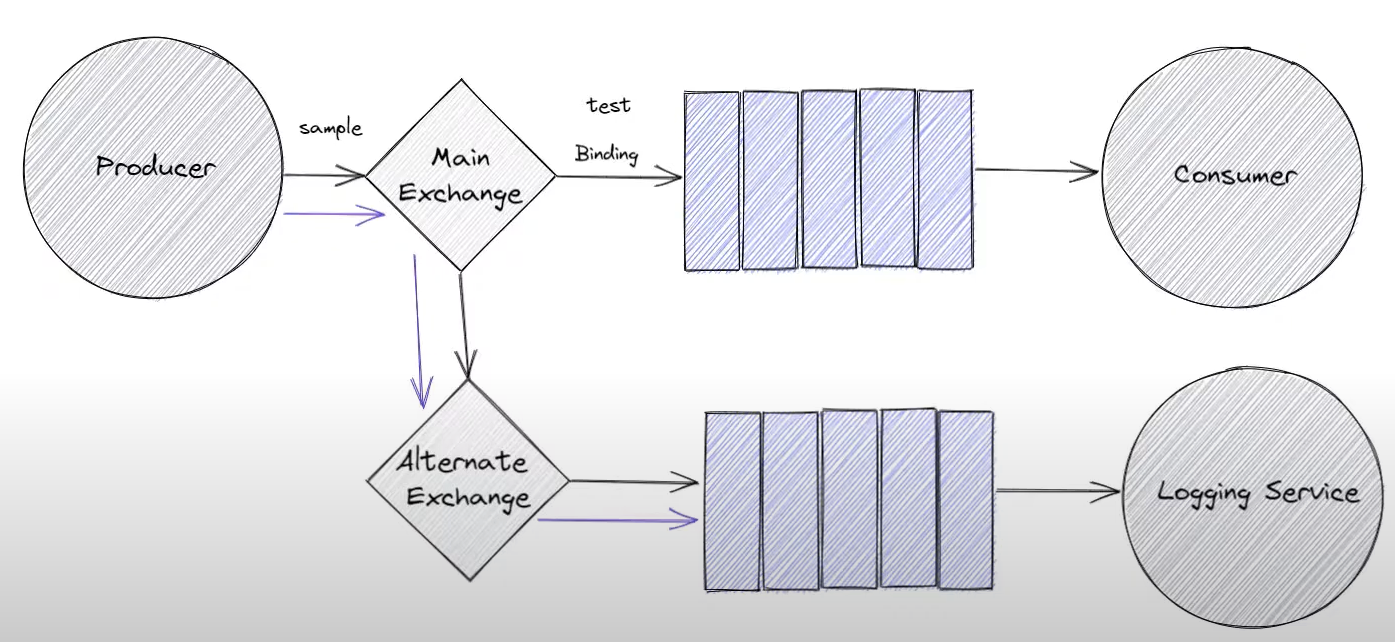
Alternate Exchange are an extension to the AMQP model created by rabbitmq to handle unrouted messages. 包括了 specifying an already existing exchange that new exchange route message to if currently they are not routed
比如 binding 是test. 如果publish a message from producer to main with key sample. Main exchange 不能route this message to any queues => unroutable message route to alternate exchange. Alternate exchange is same as any other exchange in rabbitmq. 可以是任何exchange type 比如direct, fanout, topc etc. 最常见的是fanout exchange.
比如route unrouted message to a logging service to alert
Dead Letter Exchange
When we declare a queue, we can declare that queue has an associated dead letter exchange. Any message that is route to that queue but cannot be delivered to a consumer or expires for some reason can be sent to the dead letter exchange (有message 不能deliver to consumer 或者expire 可以发到dead letter exchange)
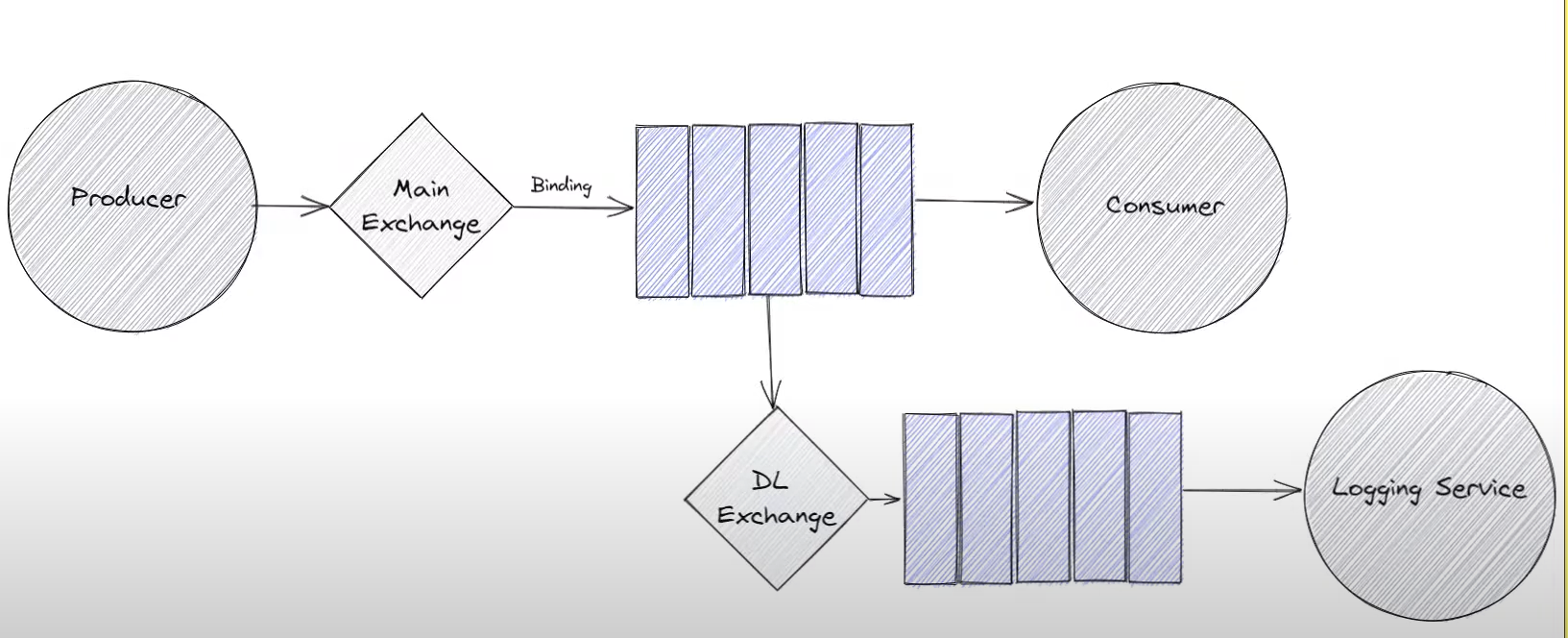
A common usage is to logging service to alert us to make developers aware that messages are being rejected from a queue or not being delivered to consumers.
Difference between alternate exchange 和 dead letter exchange 是 expired or rejected messages are delivered to dead letter exchange. Unrouted message route to alternate exchange
Message Acks

basic_ack: when finish consume a message, need to send an ack to the broker that we finish consuming the message, can usebasic_ackdelivery_tag: 是parameter ofbasic_ack: is an auto-incrementing number for that particular consumer that indicates what message it has now received. 第一个message 是tag 0, 之后1,2,3.。。- need to send the same channel that message received
multiple: boolean. allow to ack multiple messages at once. 比如收到5个message, none ack, 当ack 第5个message and set multiple flag set to true, that means we ack all messages up to and including 5
basic_reject: very similar tobasic_ackexcept instead of telling rabbitmq we successfully process the message, it’s telling rabbitmq that haven’t successfully process messages or cannot process itdelivery_tag: 是parameter ofbasic_reject: tell which messages rejectingrequeue: boolean 尽管reject message, but we want it to be requeued onto the queue it came from。 如果只有一个consumer for that queue => lead a loop, messages rejected and requeue multiple times. 如果有多个consumer, rabbitmq make an effort to deliver to different consumer- 没有
multiple只能single reject
basic_nack: has option torequeueandmultiple. allow to reject multiple messages at once and allow ack multiple messages at once
Queue Options

auto delete: automatically delete queue if not needed. A queue is deleted only if no consumering consume from (also known for temporary queue, 通用于chat application or applications that us ea request reply pattern)auto expire: only delete queue after certain amount of time if queue not used- set
x-expireargument to tell how long for timeout
- set
auto expire msg: prevent messages from hanging around too long on a queue if they haven’t been consumed. 如果有 dead letter exchange, message on the queue expires then it will sent to the dead letter exchange.- set
x-message-ttl: how long message message survive on the queue
- set
max length queue: limit the number of messages on a queue at any one time. Allow us to create queues that have a known max length. 如果有more messages published to the queue, drop message at the front the queue. These removed message can be dead lettersx-max-length最多 多少个messages allowed on queue
exclusive: only allow one consumer at a timeflag: set by a flag when creating the queue
durable: a queue persist across server restart- important flag to make rabbitmq reliable